#kagglemodels نتائج البحث

Welcome Qwen3-Next-80B-A3B on #KaggleModels! 🤖 Learn more: kaggle.com/models/qwen-lm…

🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here! 🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!) 🔹Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed &…

🤖 Now on #KaggleModels! Learn more: kaggle.com/models/mistral…

Introducing Magistral Small 1.2 & Magistral Medium 1.2, minor updates to our Magistral 1.1 models! - Multimodality: Now equipped with a vision encoder, these models handle both text and images seamlessly. - Performance Boost: 15% improvements on math and coding benchmarks such…

🤖 VaultGemma is now on #KaggleModels! Learn more: kaggle.com/models/google/…

🔒 VaultGemma is the world's most capable differentially private LLM.

📣 Llama 2 and Code Llama are now on #KaggleModels!
🤖 New on #KaggleModels! Introducing Llama 2 from @MetaAI: a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. 📚 Explore, share, and upvote your favorite notebooks. Happy Kaggling! goo.gle/3PDlvqA

You can still buy my book on all data analytics, building models, and Generative AI on @kaggle. Now with a 20% discount. Link to Amazon book page: amazon.com/Developing-Kag… #GenerativeAI #Kaggle #KaggleModels #Llama #RAG #DataAnalytics #MachineLearning

🤖 Now on #KaggleModels! Learn more: kaggle.com/models/google/…
The Gemma family is growing today. First up: T5Gemma ✨, the new generation of encoder-decoder models ↓ developers.googleblog.com/en/t5gemma

🤖 Now on #KaggleModels! Learn more kaggle.com/models/mistral…
Introducing Devstral Small and Medium 2507! This latest update offers improved performance and cost efficiency, perfectly suited for coding agents and software engineering tasks.

Now available on #KaggleModels! Learn more: kaggle.com/models/google/…
Run Gemma 3 27B on your desktop GPU 🔥 Our new QAT-optimized int4 models slash VRAM needs (54GB -> 14.1GB) while maintaining quality. Now accessible on consumer cards like the NVIDIA RTX 3090 via @ollama, @huggingface, @lmstudio & more.

🤖Now on #KaggleModels! Learn more: kaggle.com/models/google/…
Introducing Gemma 3 270M! 🚀 It sets a new standard for instruction-following in compact models, while being extremely efficient for specialized tasks. developers.googleblog.com/en/introducing…

🤖 @CohereForAI’s Aya Vision is now available on #KaggleModels 👉 Learn more: kaggle.com/models/coheref…

Introducing ✨ Aya Vision ✨ - an open-weights model to connect our world through language and vision Aya Vision adds breakthrough multimodal capabilities to our state-of-the-art multilingual 8B and 32B models. 🌿

Recently, Kaggle Models opened its doors to user contributions, specifically welcoming Keras model uploads. Learn more at: bit.ly/3QCBSDV . . . #developers #marketinghacks #KaggleModels #KerasUploads #HuggingFaceIntegration #AICommunityEmpowerment #ModelSharingGuide

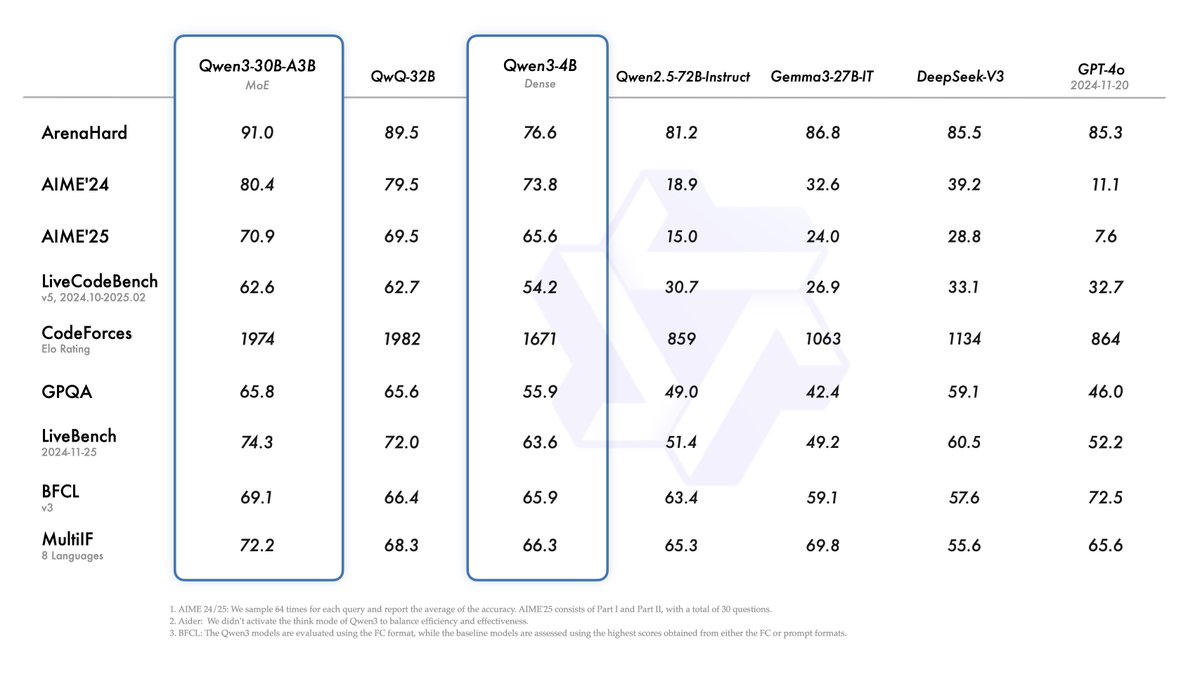
🤖 Now on #KaggleModels! The long-awaited @Alibaba_Qwen's Qwen 3 is here - featuring dense + MoE models, trained on 36T tokens across 119 languages. Big gains in reasoning, performance, and long-context (32k tokens) support! Learn more: kaggle.com/models/qwen-lm…
Introducing Qwen3! We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general…

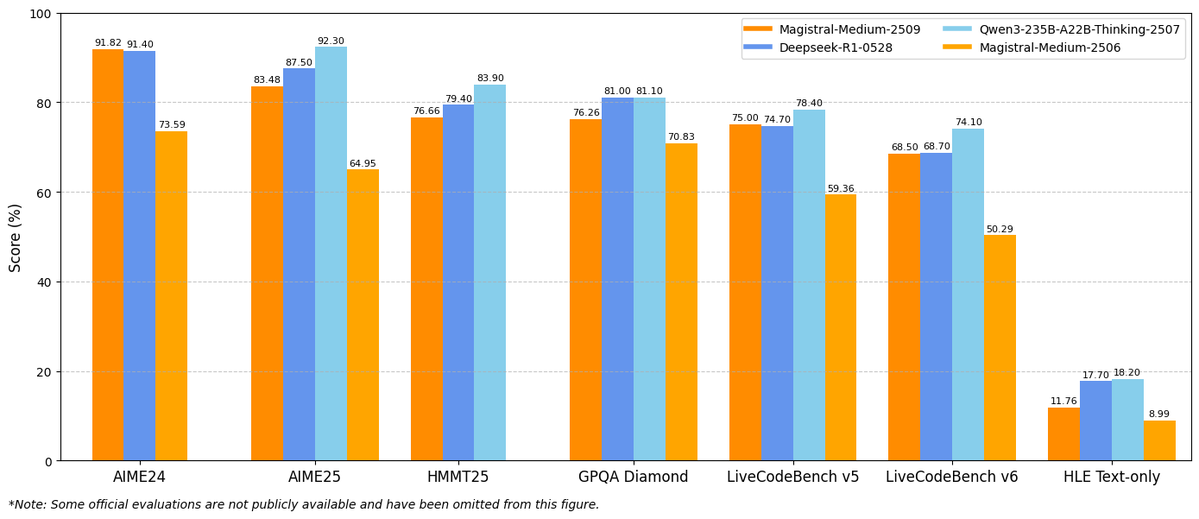
🤖 @MistralAI’s Magistral is now on #KaggleModels! 👉 Learn more: kaggle.com/models/mistral…
Announcing Magistral, our first reasoning model designed to excel in domain-specific, transparent, and multilingual reasoning.

🤖 Now on #KaggleModels! @Alibaba_Qwen's QwQ-32B, a 32B parameter reasoning model, uses Reinforcement Learning to enhance tasks like math, coding, and problem-solving, ensuring high performance and accuracy. Check it out here 👇 kaggle.com/models/qwen-lm…
🤖 @Google’s Gemma 3 and Shield Gemma are now on #KaggleModels! 👉 Gemma 3 kaggle.com/models/google/… 👉ShieldGemma 2 kaggle.com/models/google/…
Gemma 3 is a collection of lightweight, state-of-the-art open models built from the same research and technology that powers our Gemini 2.0 models. → goo.gle/43Ic5RV

That's great news! Llama 2 and Code Llama being featured on #KaggleModels is a fantastic achievement. It's always exciting to see innovative models being recognized and shared within the Kaggle community. Congratulations to the teams behind Llama 2 and Code Llama!
🤖PaliGemma 2 mix is now on #KaggleModels! Learn more: kaggle.com/models/google/…
PaliGemma 2 mix is an upgraded vision-language model that supports image captioning, OCR, image Q&A, object detection, and segmentation. With sizes from 3B-28B parameters, there's a model for everyone. Get started. → goo.gle/430HnDe

🤖 @MistralAI’s Small 3 is now available on #KaggleModels! Learn more: kaggle.com/models/mistral…
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building! mistral.ai/news/mistral-s…

🤖 @MistralAI’s Devstral is now on #KaggleModels! Devstral is a 24B-parameter open model for software engineering tasks - built to support codebase exploration, multi-file edits, and agentic coding workflows. kaggle.com/models/mistral…

🤖 Now on #KaggleModels! Learn more: kaggle.com/models/mistral…
Introducing Magistral Small 1.2 & Magistral Medium 1.2, minor updates to our Magistral 1.1 models! - Multimodality: Now equipped with a vision encoder, these models handle both text and images seamlessly. - Performance Boost: 15% improvements on math and coding benchmarks such…
🤖 VaultGemma is now on #KaggleModels! Learn more: kaggle.com/models/google/…
🔒 VaultGemma is the world's most capable differentially private LLM.
Welcome Qwen3-Next-80B-A3B on #KaggleModels! 🤖 Learn more: kaggle.com/models/qwen-lm…
🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here! 🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!) 🔹Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed &…
🤖Now on #KaggleModels! Learn more: kaggle.com/models/google/…
Introducing Gemma 3 270M! 🚀 It sets a new standard for instruction-following in compact models, while being extremely efficient for specialized tasks. developers.googleblog.com/en/introducing…
🤖 Now on #KaggleModels! Learn more kaggle.com/models/mistral…
Introducing Devstral Small and Medium 2507! This latest update offers improved performance and cost efficiency, perfectly suited for coding agents and software engineering tasks.
🤖 Now on #KaggleModels! Learn more: kaggle.com/models/google/…
The Gemma family is growing today. First up: T5Gemma ✨, the new generation of encoder-decoder models ↓ developers.googleblog.com/en/t5gemma
🤖 @MistralAI’s Magistral is now on #KaggleModels! 👉 Learn more: kaggle.com/models/mistral…
Announcing Magistral, our first reasoning model designed to excel in domain-specific, transparent, and multilingual reasoning.
🤖 @MistralAI’s Devstral is now on #KaggleModels! Devstral is a 24B-parameter open model for software engineering tasks - built to support codebase exploration, multi-file edits, and agentic coding workflows. kaggle.com/models/mistral…
Now available on #KaggleModels! Learn more: kaggle.com/models/google/…
✨ Introducing Gemma 3n, available in early preview today. The model uses a cutting-edge architecture optimized for mobile on-device usage. It brings multimodality, super fast inference, and more.
🤖 Now on #KaggleModels! The long-awaited @Alibaba_Qwen's Qwen 3 is here - featuring dense + MoE models, trained on 36T tokens across 119 languages. Big gains in reasoning, performance, and long-context (32k tokens) support! Learn more: kaggle.com/models/qwen-lm…
Introducing Qwen3! We release and open-weight Qwen3, our latest large language models, including 2 MoE models and 6 dense models, ranging from 0.6B to 235B. Our flagship model, Qwen3-235B-A22B, achieves competitive results in benchmark evaluations of coding, math, general…
Now available on #KaggleModels! Learn more: kaggle.com/models/google/…
Run Gemma 3 27B on your desktop GPU 🔥 Our new QAT-optimized int4 models slash VRAM needs (54GB -> 14.1GB) while maintaining quality. Now accessible on consumer cards like the NVIDIA RTX 3090 via @ollama, @huggingface, @lmstudio & more.
🤖 @Google’s Gemma 3 and Shield Gemma are now on #KaggleModels! 👉 Gemma 3 kaggle.com/models/google/… 👉ShieldGemma 2 kaggle.com/models/google/…
Gemma 3 is a collection of lightweight, state-of-the-art open models built from the same research and technology that powers our Gemini 2.0 models. → goo.gle/43Ic5RV
🤖 Now on #KaggleModels! @Alibaba_Qwen's QwQ-32B, a 32B parameter reasoning model, uses Reinforcement Learning to enhance tasks like math, coding, and problem-solving, ensuring high performance and accuracy. Check it out here 👇 kaggle.com/models/qwen-lm…

@kaggle, wow, Aya Vision being available on #KaggleModels opens doors for innovation! Utilizing AI efficiently can amplify our insights in unexpected ways. What exciting projects do you see emerging from this? 🤔
🤖 @CohereForAI’s Aya Vision is now available on #KaggleModels 👉 Learn more: kaggle.com/models/coheref…
Introducing ✨ Aya Vision ✨ - an open-weights model to connect our world through language and vision Aya Vision adds breakthrough multimodal capabilities to our state-of-the-art multilingual 8B and 32B models. 🌿
🤖PaliGemma 2 mix is now on #KaggleModels! Learn more: kaggle.com/models/google/…
PaliGemma 2 mix is an upgraded vision-language model that supports image captioning, OCR, image Q&A, object detection, and segmentation. With sizes from 3B-28B parameters, there's a model for everyone. Get started. → goo.gle/430HnDe
🤖 Now on #KaggleModels! @MistralAI’s Small 3 is the newest open-weight model under 70B, built for efficiency and versatility. Ideal for conversational AI, robotics, and low-latency tasks, it packs powerful performance into a compact size. Learn more: kaggle.com/models/mistral…

Prepping for the recruitment season by diving into business problem datasets on @kaggle to sharpen my ML & Data Science skills! 🚀 If you have any interesting datasets in mind, drop them my way! #MachineLearning #DataScience #KaggleModels #Kaggle #machinelearningbasics
🤖 @MistralAI’s Small 3 is now available on #KaggleModels! Learn more: kaggle.com/models/mistral…
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building! mistral.ai/news/mistral-s…
🤖 Now on #KaggleModels! @deepseek_ai's Janus-Pro is a unified MLLM for multimodal understanding and generation, built on DeepSeek-LLM-1.5b/7b-base. It uses SigLIP-L for vision encoding, supporting 384x384 images, optimized for image generation. kaggle.com/models/deepsee…
You can still buy my book on all data analytics, building models, and Generative AI on @kaggle. Now with a 20% discount. Link to Amazon book page: amazon.com/Developing-Kag… #GenerativeAI #Kaggle #KaggleModels #Llama #RAG #DataAnalytics #MachineLearning
Recently, Kaggle Models opened its doors to user contributions, specifically welcoming Keras model uploads. Learn more at: bit.ly/3QCBSDV . . . #developers #marketinghacks #KaggleModels #KerasUploads #HuggingFaceIntegration #AICommunityEmpowerment #ModelSharingGuide
Something went wrong.
Something went wrong.
United States Trends
- 1. #warmertogether N/A
- 2. $BARRON 2,110 posts
- 3. Harvey Weinstein 3,165 posts
- 4. Diane Ladd 3,514 posts
- 5. Ben Shapiro 27.8K posts
- 6. $PLTR 16.9K posts
- 7. Laura Dern 1,678 posts
- 8. Gold's Gym 49.7K posts
- 9. Cardinals 11.9K posts
- 10. #NXXT 2,507 posts
- 11. #maddiekowalski 4,165 posts
- 12. iOS 26.1 N/A
- 13. #CAVoteYesProp50 6,074 posts
- 14. #EAPartner N/A
- 15. McBride 2,999 posts
- 16. Standout 7,798 posts
- 17. University of Virginia 1,871 posts
- 18. Teen Vogue N/A
- 19. Mumdumi 13.1K posts
- 20. $HIMS 6,197 posts