#knowledgedistillation search results

SD-HRNet: Slimming and Distilling High-Resolution Network for Efficient Face Alignment mdpi.com/1424-8220/23/3… #facealignment; #knowledgedistillation; #networkpruning

Lightweight Depth Completion Network with Local Similarity-Preserving Knowledge Distillation mdpi.com/1424-8220/22/1… #depthcompletion #localsimilarity #knowledgedistillation #modelcompression #sensor #multimodallearning
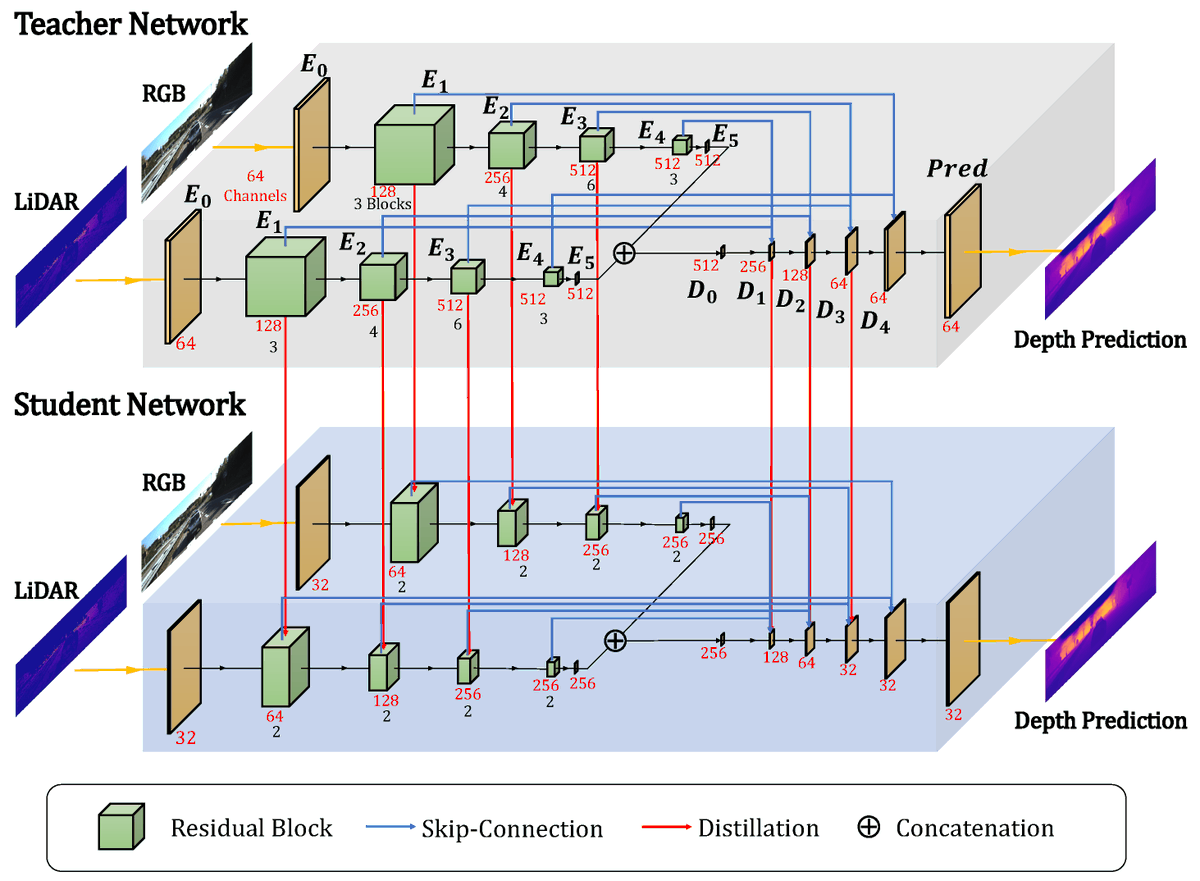
NTCE-KD: Non-Target-Class-Enhanced Knowledge Distillation mdpi.com/1424-8220/24/1… #knowledgedistillation


🤯 Unlock the power of #KnowledgeDistillation with the groundbreaking paper "EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval" by Seungyeon Kim et al., including @sanjeevk_! 🔐 Check out the paper: deepai.org/publication/em… #ComputerScience #Learning
Lowkey Goated When #KnowledgeDistillation Is The Vibe! Check out this awesome paper by Francisco J. Peña et al. to learn more about self-supervised semantic segmentation of wetlands from SAR images! deepai.org/publication/de… 🤩
Enhanced Knowledge Distillation for Advanced Recognition of Chinese Herbal Medicine mdpi.com/1424-8220/24/5… #knowledgedistillation


Assoc. Prof. Wang Zhi’s team from @TsinghuaSIGS won the Best Paper Award at @IEEEorg ICME 2023. Their paper focuses on collaborative data-free #KnowledgeDistillation via multi-level feature sharing, representing the latest developments in #multimedia.


Visual Attention for Robotics - websystemer.no/visual-attenti… #attentionnetwork #disturbance #knowledgedistillation #robotics #visualattention
A #MachineLearning model can be compressed by #KnowledgeDistillation to be used on less powerful hardware. A method proposed a @TsinghuaSIGS team can minimize knowledge loss during the compression of pattern detector models. For more: bit.ly/3X34is0




We introduce a knowledge distillation method for multi-crop, multi-disease detection, creating lightweight models with high accuracy. Ideal for smart agriculture devices. #PlantDiseaseDetection #KnowledgeDistillation #SmartFarming Details: spj.science.org/doi/10.34133/p…


Great example of DL engineering for production #DeepLearning #knowledgedistillation

How we crop images in your Twitter app efficiently and accurately. We use knowledge distillation and pruning to make the model really efficient. Then the salient regions of the images are detected. Finally a crop is generated focusing on such regions.

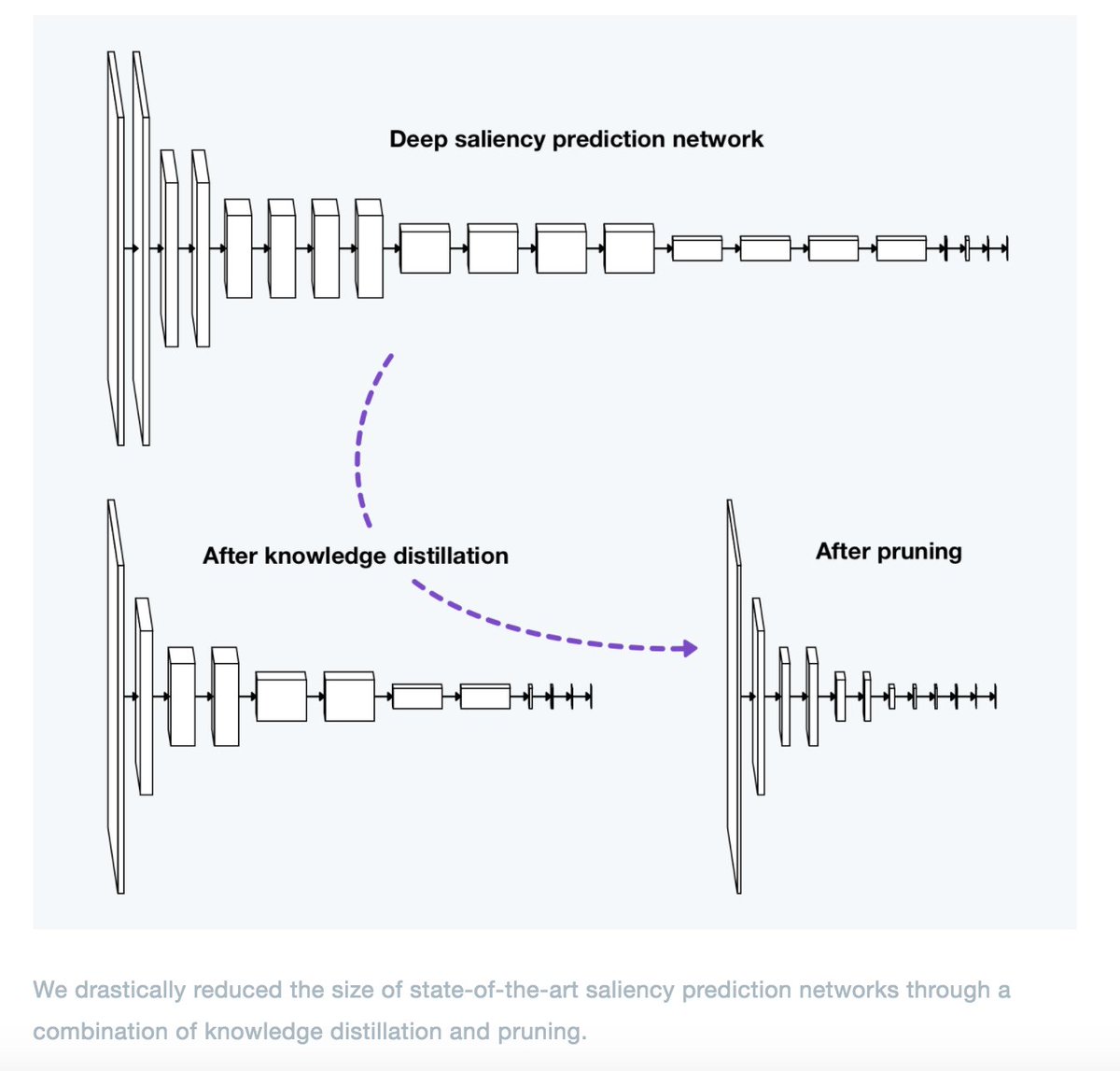

Innovative use of Transformer neural networks and Knowledge Distillation for Structural Health Monitoring outperforms traditional methods. #StructuralHealthMonitoring #Transformers #KnowledgeDistillation


#Selectedarticles with GA Title: Lightweight Infrared and Visible #ImageFusion via Adaptive DenseNet with #KnowledgeDistillation Authors: Zongqing Zhao, Shaojing Su, Junyu Wei, Xiaozhong Tong, Weijia Gao Find more here: mdpi.com/2079-9292/12/1… #mdpielectronics #openaccess


#KnowledgeDistillation does have scalable impact both +ve and -ve... I recall one of the very first papers (in our group) in the context of @AnthropicAI 's post!




Talking about how we make the most of "knowledge distillation" to level up our labeling process using foundation models at Google for Startups YoloVision Conference @ultralytics 🧠🤖🔍 #AI #Labeling #KnowledgeDistillation #YV23 #ComputerVision

Distilling BERT Using an Unlabeled Question-Answering Dataset - websystemer.no/distilling-ber… #deeplearning #knowledgedistillation #machinelearning #nlp #questionanswering

[Paper Summary] Distilling the Knowledge in a Neural Network - websystemer.no/paper-summary-… #deeplearning #knowledgedistillation #machinelearning #performance #softmax
![Websystemer's tweet image. [Paper Summary] Distilling the Knowledge in a Neural Network - websystemer.no/paper-summary-…
#deeplearning #knowledgedistillation #machinelearning #performance #softmax](https://pbs.twimg.com/media/Ebu9DIkWkAEOOvW.jpg)

Just like how our brains can sometimes create illusions, #GPT AI models can experience hallucinations, generating text that sounds logical but isn't factually accurate. At @opentensor, is working on models to minimize this issue #AI #knowledgedistillation

What is Knowledge Distillation in #AI? #KnowledgeDistillation #legalbattleoverAI #IPinfringement linkedin.com/posts/pinakila…
linkedin.com
#ai #knowledgedistillation #legalbattleoverai #ipinfringement | Pinaki Laskar
What is Knowledge Distillation in #AI? #KnowledgeDistillation is a machine learning technique that aims to transfer the learnings of a large pre-trained model, the teacher model, to a smaller student...

KD-MARL: Resource-Aware Knowledge Distillation in Multi-Agent Reinforcement Learning Preprint: This study introduces a two-stage framework for resour… arxiv.org/abs/2604.06691 #AI #ReinforcementLearning #KnowledgeDistillation #MachineLearning #Preprint #Arxiv #ScienceNews

Stop asking 1.2B-parameter VLMs to teach ResNet-18 directly. It doesn't work. ❌🦉 DAIT (Distilling CLIP via Adaptive Intermediate Teacher) is the new SOTA for fine-grained vision. 🧵👇 Full Paper + PyTorch Implementation:🔗aitrendblend.com/dait-distillat… #KnowledgeDistillation #VLM


有人把巴菲特、Karpathy、张一鸣的思维全拆成了 AI skill,搞了个开源 repo。 以前比的是"你认识谁",马上要比"你 AI 后台装了谁的脑子"。 知识蒸馏从模型卷到了真人,个人护城河怕是得重新定义了。 #AI #KnowledgeDistillation x.com/ianneo_ai/stat…

可怕,已经有人开始批量蒸馏别人的脑子了 这个 repo 里,巴菲特、PG、Karpathy、张一鸣、毛选、MrBeast,都被拆成了 skill 你拿到的就不只是观点 而是他们怎么判断、怎么拆问题、怎么做决策 这玩意儿看着像资料库 真用起来更像给自己挂了一排数字军师


PCKD (Physically Motivated Knowledge Distillation) is a new framework that straightens sonar imagery blind—no navigation data needed. 🧵👇 Paper breakdown + Full PyTorch Code: 🔗aitrendblend.com/pckd-physicall… #SideScanSonar #KnowledgeDistillation #ComputerVision #PCKD #AITrendBlend


#highlycited paper 📚MicroBERT: Distilling MoE-Based Knowledge from BERT into a Lighter Model 🔗mdpi.com/2076-3417/14/1… 👨🔬by Dashun Zheng et al. @mpu1991 #naturallanguageprocessing #knowledgedistillation


📈 The $80M Silent Launch: How Gemini Video Create and 'Proprietary AI' are Replacing Human Consulting in 2026 In 2026, learners are hitting $80M l… versaroc.co.jp/blog/80m-dolla… #GeminiVideoCreate #AIMarketing2026 #KnowledgeDistillation #DigitalTwinBusiness #VERSAROC

Steve-Evolving: Open-World Embodied Self-Evolution via Fine-Grained Diagnosis and Dual-Track Knowledge Distillation Preprint: Steve-Evolving is a self-evolving framework fo… arxiv.org/abs/2603.13131 #AI #KnowledgeDistillation #MachineLearning #Preprint #Arxiv #ScienceNews

Caffeine-fueled curiosity got me wondering: if the universe were a library, which books would you burn to make way for new knowledge? #knowledgedistillation

🔥 Read our Paper 📚Discriminator-Enhanced #KnowledgeDistillation Networks 🔗mdpi.com/2076-3417/13/1… 👨🔬by Zhenping Li et al. @CAS__Science #knowledgedistillation #reinforcementlearning


📱Big model, small device?📉 Knowledge distillation helps you shrink LLMs without killing performance. Learn how teacher–student training works👉labelyourdata.com/articles/machi… #MachineLearning #LLM #KnowledgeDistillation

📢 New #ACL2025Findings Paper 📢 Can smaller language models learn how large ones reason, or just what they conclude? Our latest paper in #ACLFindings explores the overlooked tension in #KnowledgeDistillation - generalization vs reasoning fidelity. #NLProc


📚🤖 Knowledge Distillation = small AI model learning from a big one! Smarter, faster, efficient. Perfect for NLP & vision! 🚀📱 See here - techchilli.com/artificial-int… #KnowledgeDistillation #AI2025 #DeepLearning #TechChilli #ModelCompression
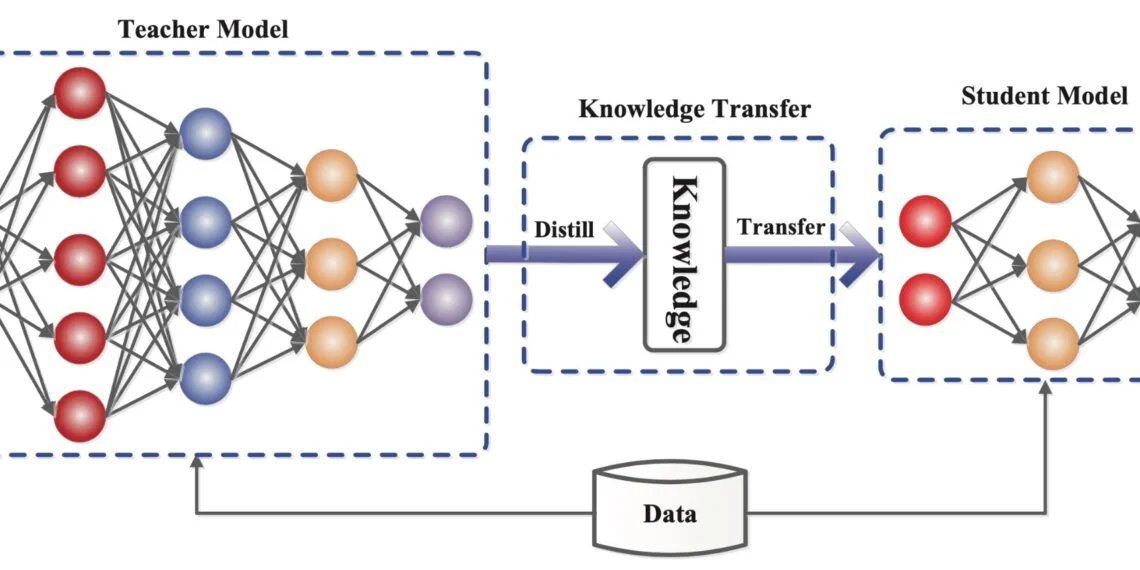

What Is Knowledge Distillation? Want to understand how neural networks are trained using this powerful technique with LeaderGPU®? Get all the details on our site: leadergpu.com/catalog/606-wh… #AI #NeuralNetworks #KnowledgeDistillation #GPU #DedicatedServer #Instance #GPUCloud


AI’s strategic importance is undeniable, with #knowledgedistillation enhancing user experiences through more efficient, tailored models. However, the challenges—limited context windows, #hallucinations, and high #computational costs—require deliberate strategies to overcome.

Esa conversación con Mr. Tavito sobre #DeepSeek y la magia de la destilación de conocimiento... de ahí nació mi tesis. Hoy, al ver mi propio modelo destilado funcionar, la lección es clara: el único límite somos nosotros mismos. ¡A seguir mejorando! 💪 #KnowledgeDistillation


#KnowledgeDistillation helps you train a smaller #AIModel to mimic a larger one—perfect when data is limited or devices have low resources. Use it for similar tasks with less compute. Learn more with @tenupsoft tenupsoft.com/blog/ai-model-… #AI #AITraining #EdgeAI


Check out the blog: superteams.ai/blog/a-hands-o… #AIInfrastructure #ModelCompression #KnowledgeDistillation
superteams.ai
A Hands-on Guide to Knowledge Distillation - Superteams.ai
Compress large AI models for cost-efficient deployment using Knowledge Distillation.
NTCE-KD: Non-Target-Class-Enhanced Knowledge Distillation mdpi.com/1424-8220/24/1… #knowledgedistillation

🌟Visual Intelligence highly cited papers No. 7🌟 Check out this cross-camera self-distillation framework for unsupervised person Re-ID to alleviate the effect of camera variation. 🔗Read more: link.springer.com/article/10.100… #Unsupervisedlearning #Personreid #Knowledgedistillation

Enhanced Knowledge Distillation for Advanced Recognition of Chinese Herbal Medicine mdpi.com/1424-8220/24/5… #knowledgedistillation




Enhanced Knowledge Distillation for Advanced Recognition of Chinese Herbal Medicine mdpi.com/1424-8220/24/5… #knowledgedistillation
Lightweight Depth Completion Network with Local Similarity-Preserving Knowledge Distillation mdpi.com/1424-8220/22/1… #depthcompletion #localsimilarity #knowledgedistillation #modelcompression #sensor #multimodallearning
NTCE-KD: Non-Target-Class-Enhanced Knowledge Distillation mdpi.com/1424-8220/24/1… #knowledgedistillation
We introduce a knowledge distillation method for multi-crop, multi-disease detection, creating lightweight models with high accuracy. Ideal for smart agriculture devices. #PlantDiseaseDetection #KnowledgeDistillation #SmartFarming Details: spj.science.org/doi/10.34133/p…
SD-HRNet: Slimming and Distilling High-Resolution Network for Efficient Face Alignment mdpi.com/1424-8220/23/3… #facealignment; #knowledgedistillation; #networkpruning
Caffeine-fueled curiosity got me wondering: if the universe were a library, which books would you burn to make way for new knowledge? #knowledgedistillation

Researchers have proposed a general & effective #knowledgedistillation method for #objectdetection, which helps to transfer the teacher's focal and global knowledge to the student. #machinelearning More at: bit.ly/3UB2swS

#highlycited paper 📚MicroBERT: Distilling MoE-Based Knowledge from BERT into a Lighter Model 🔗mdpi.com/2076-3417/14/1… 👨🔬by Dashun Zheng et al. @mpu1991 #naturallanguageprocessing #knowledgedistillation

A beginner’s guide to #KnowledgeDistillation in #DeepLearning buff.ly/33GA7Qt #fintech #AI #ArtificialIntelligence #MachineLearning @Analyticsindiam


And now @SwamiSivasubram arrived at @Amazon Sagemaker. Of course has all the capabilities teed up before - #KnowledgeDistillation #ReInforcementLearning etc etc. #AWSReinvent


LLM’s Grind 🔥 Explored Knowledge Distillation — the art of teaching a small model to think like a big one. Tried it on a simple CNN, and it worked perfectly! Now, onto applying it in LLMs #AI #LLM #KnowledgeDistillation #DeepLearning #LLMs
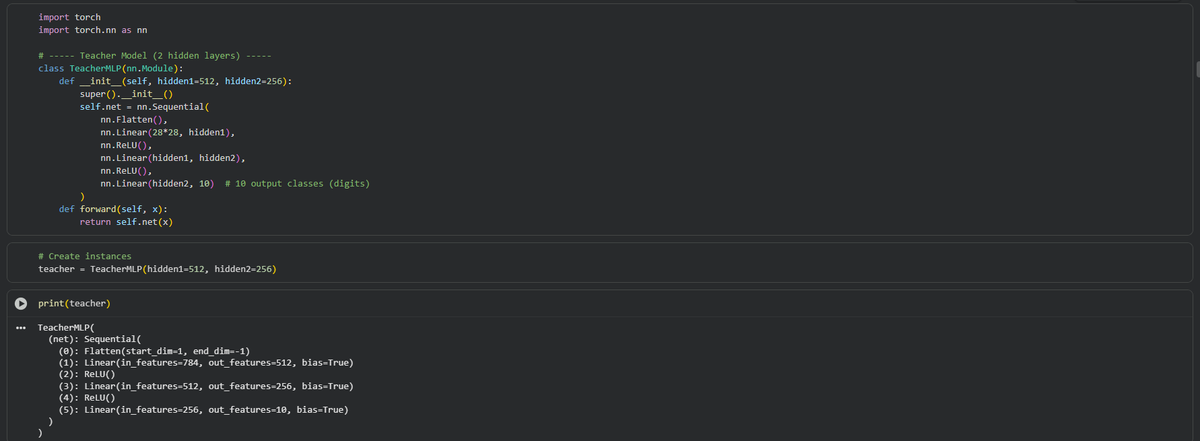
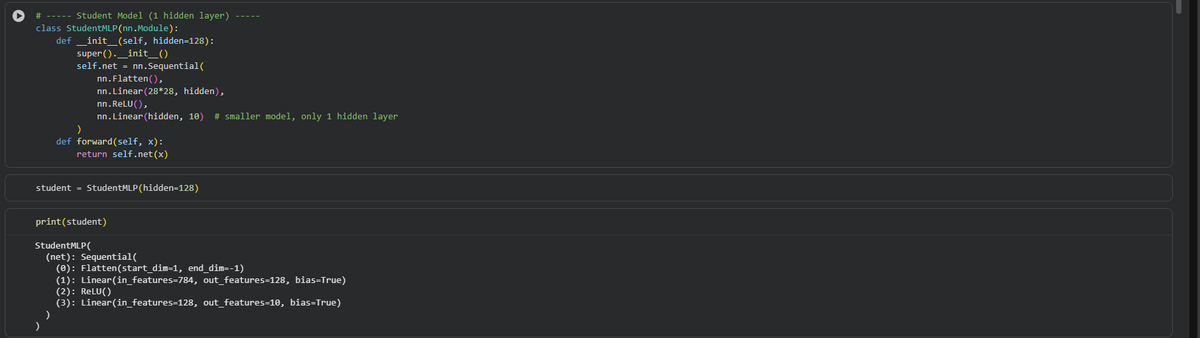
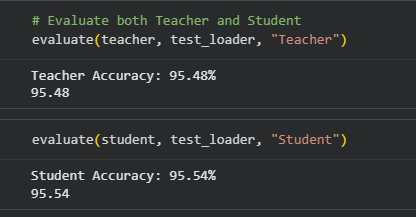
A #MachineLearning model can be compressed by #KnowledgeDistillation to be used on less powerful hardware. A method proposed a @TsinghuaSIGS team can minimize knowledge loss during the compression of pattern detector models. For more: bit.ly/3X34is0
#KnowledgeDistillation helps you train a smaller #AIModel to mimic a larger one—perfect when data is limited or devices have low resources. Use it for similar tasks with less compute. Learn more with @tenupsoft tenupsoft.com/blog/ai-model-… #AI #AITraining #EdgeAI
Assoc. Prof. Wang Zhi’s team from @TsinghuaSIGS won the Best Paper Award at @IEEEorg ICME 2023. Their paper focuses on collaborative data-free #KnowledgeDistillation via multi-level feature sharing, representing the latest developments in #multimedia.
🔥 Read our Highly Cited Paper 📚MicroBERT: Distilling MoE-Based #Knowledge from BERT into a Lighter Model 🔗mdpi.com/2076-3417/14/1… 👨🔬by Dashun Zheng et al. @mpu1991 #naturallanguageprocessing #knowledgedistillation


Knowledge Distillation in Deep Learning rb.gy/xaraa #KnowledgeDistillation #NaturalLanguageProcessing #TransferLearning #DataDistillation #MachineLearning #ArtificialNeurons #SmartSystems


I will be at #NeurIPS2025 in San Diego next week! Please stop by my poster if you are interested in the underlying mechanisms of #KnowledgeDistillation in generative models! - Paper: Why Knowledge Distillation Works in Generative Models: A Minimal Working Explanation - Wed 3




RT CODIR: Train smaller, faster NLP models dlvr.it/RpvMSW #machinelearning #knowledgedistillation #naturallanguageprocessing

🔥 Read our Paper 📚Discriminator-Enhanced #KnowledgeDistillation Networks 🔗mdpi.com/2076-3417/13/1… 👨🔬by Zhenping Li et al. @CAS__Science #knowledgedistillation #reinforcementlearning
Something went wrong.
Something went wrong.
United States Trends
- 1. Good Sunday N/A
- 2. Muhammad Qasim N/A
- 3. $RISE N/A
- 4. NO MORE MR. NICE GUY N/A
- 5. Everton N/A
- 6. Sunday Funday N/A
- 7. Bengals N/A
- 8. #EVELIV N/A
- 9. Gakpo N/A
- 10. Blessed Sunday N/A
- 11. Iowa City N/A
- 12. #SundayVibes N/A
- 13. New Glenn N/A
- 14. Mo Salah N/A
- 15. #SeductiveSunday N/A
- 16. #2YearsOfTSTTPD N/A
- 17. #WrestleManiaDayOne N/A
- 18. Blue Origin N/A
- 19. For God N/A
- 20. Stefanik N/A