#modelcompression 검색 결과

Excited to share: our paper “On Pruning State-Space LLMs” was accepted to EMNLP 2025! 🎉 Preprint: arxiv.org/abs/2502.18886 Code: github.com/schwartz-lab-N… Model: Smol-Mamba-1.9B → huggingface.co/schwartz-lab/S… w/ @MichaelHassid & @royschwartzNLP (HUJI) #Mamba #ModelCompression


🔥 Read our Highly Cited Paper 📚Stable Low-Rank CP #Decomposition for Compression of Convolutional Neural Networks Based on Sensitivity 🔗mdpi.com/2076-3417/14/4… 👨🔬by Chenbin Yang and Huiyi Liu 🏫Hohai University #convolutionalneuralnetworks #modelcompression


AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. By @antgrasso #AI #ModelCompression #Efficiency


Today's #PerfiosAITechTalk talks about how #ModelCompression can be used for efficient on-device runtimes. #NeuralNetworks #Datascience #ML #AI


AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. Microblog by @antgrasso #AI #ModelCompression #Efficiency…

The four common #ModelCompression techniques: 1) Quantization 2) Pruning 3) Knowledge distillation 4) Lower rank matrix factorization. What does your experience point you toward? #NeuralNetworks #DataScience #PerfiosAITechTalk


Model compression in ICCLOUD! 8 - bit Quantization cuts memory by 75%, Weight Pruning reduces compute by 50%. Save resources! #ModelCompression #Resources

What do you mean by #ModelCompression? The answer is here, courtesy #NeuralNetworks expert @bsourav29 #PerfiosAITechTalk


Accuracy hides issues in quantized LLMs. 'Accuracy is Not All You Need' (NeurIPS 2024) shows 'flips' & KL-Divergence reveal output changes. #AI #ModelCompression #LLM


📢 Our paper "Quantifying Knowledge Distillation Using Partial Information Decomposition" will be presented at #AISTATS2025 on May 5th, Poster Session 3! Our work brings together #modelcompression and #explainability through the lens of #informationtheory Link:…


Introducing QDP Studio—a modest yet practical framework for deep learning model compression that combines quantization, pruning, and decomposition. #DeepLearning #ModelCompression Link : github.com/jaicdev/QDPStu…


How #AI can give you a Life after death. . .? An interesting thread #modelcompression mirror.xyz/dashboard/edit… 1/4


Very happy to give a talk titled "BERT, Compression and Applications" for the Autonomous Driving Center at Xpeng Motors (en.xiaopeng.com, 小鹏汽车)! Efficient AI techniques like #ModelCompression, #FewShotDistillation will greatly improve autonomous driving technology.


RT Model Compression: A Look into Reducing Model Size dlvr.it/RqDnWR #machinelearning #modelcompression #tinyml #deeplearning


What is #ModelCompression in #AI? #Infographic by @antgrasso #ArtificialIntelligence #MachineLearning #NeuralNetworks #DeepLearning #AIResearch #DataScience cc: @jeffkagan @SpirosMargaris @jblefevre60 @CES


AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. Microblog by @antgrasso #AI #ModelCompression #Efficiency

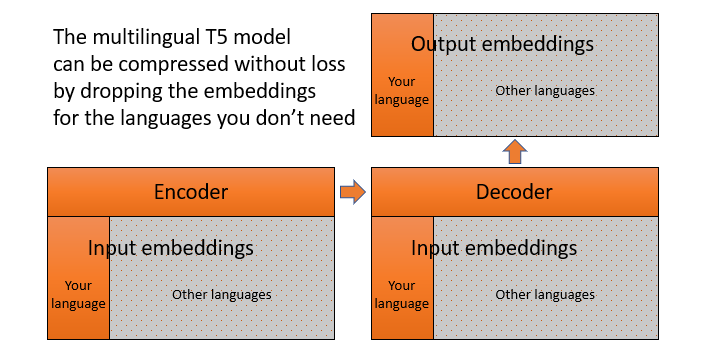
RT How to adapt a multilingual T5 model for a single language dlvr.it/Rz5ltX #nlp #transformers #modelcompression #machinelearning #t5

📖 I'm exploring ICLR 2025 accepted papers on model compression! Here’s my curated reading list on Model Compression & Training Efficiency: github.com/nanguoyu/ICLR2… Let me know if you have recommendations! 🚀 #ICLR2025 #AI #ModelCompression


🔍 New Blog Alert! Dive deep into the fascinating journey of AI model compression in Part VII: From Vision to Understanding - The Birth of Attention, written by Ateeb Taseer. ➡️ Read the full blog now 👉 s.mtrbio.com/ewdstjvwye #AI #ModelCompression #AttentionMechanisms

Introducing Nota 🇰🇷 AI model compression technology that makes deep learning models run faster with less computing power. They help companies deploy AI on mobile devices without sacrificing performance. Efficiency-focused AI innovation. #AI #ModelCompression #MobileAI


4/6 The next frontier is clear: Efficient World Models. How do we get this powerful reasoning capability into a tiny footprint? This is where our work on #ModelCompression is critical. We need: Quantization for model state Pruning of the planning process Distillation of the…

🚀 OptiPFair v0.2.0 is out! New: Data-driven width pruning for LLMs 📊 Use your data to guide pruning 🎯 Better preservation of domain knowledge pip install --upgrade optipfair Docs: peremartra.github.io/optipfair/ #LLM #ModelCompression #AI
The tech behind this is #AI and #modelcompression - Which I will explore in my next thread . 4/4
How #AI can give you a Life after death. . .? An interesting thread #modelcompression mirror.xyz/dashboard/edit… 1/4
AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. By @antgrasso #AI #ModelCompression #Efficiency
AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. rt @antgrasso #AI #ModelCompression #Efficiency


When @heyelsaAi brings scalable speech AI, @antix_in compresses models to the extreme, and @SentientAGI pushes cognitive boundaries— you don’t just get smaller models. You get smarter, faster, and more accessible intelligence. #AI #ModelCompression #AGI #bb27 #CharlieKirkshot
🔥 Read our Highly Cited Paper 📚Stable Low-Rank CP #Decomposition for Compression of Convolutional Neural Networks Based on Sensitivity 🔗mdpi.com/2076-3417/14/4… 👨🔬by Chenbin Yang and Huiyi Liu 🏫Hohai University #convolutionalneuralnetworks #modelcompression
Excited to share: our paper “On Pruning State-Space LLMs” was accepted to EMNLP 2025! 🎉 Preprint: arxiv.org/abs/2502.18886 Code: github.com/schwartz-lab-N… Model: Smol-Mamba-1.9B → huggingface.co/schwartz-lab/S… w/ @MichaelHassid & @royschwartzNLP (HUJI) #Mamba #ModelCompression
Accuracy hides issues in quantized LLMs. 'Accuracy is Not All You Need' (NeurIPS 2024) shows 'flips' & KL-Divergence reveal output changes. #AI #ModelCompression #LLM

Graft and Go: How Knowledge Grafting Shrinks AI Without Shrinking Its Brain cognaptus.com/blog/2025-07-2… #AIoptimization #edgecomputing #modelcompression #knowledgetransfer #resource-constrainedAI
cognaptus.com
Graft and Go: How Knowledge Grafting Shrinks AI Without Shrinking Its Brain
A novel approach called knowledge grafting allows AI models to be drastically slimmed down while improving generalization, enabling deployment in resource-constrained environments.

💡 Dynamic Quantization isn’t just compression. It’s context-aware model tuning. Why run a full 8-bit matrix multiply when a 5-bit op would do? @TheoriqAI is giving models a sixth sense — and saving compute for the rest of us. #EdgeAI #ModelCompression

خلّيت الموديل يصوم: شلت ٨٠٪ من الـ neurons ورجع يكسّر الدقة القديمة. Framework: قياس – قطع – إعادة تأهيل. لما الشبكة تحس إنها وحيدة في الحلبة، كل عصب بيقاتل بجد. الكود بتاعك تقيل؟ حرّمه من السعرات وشوف الفرق. #SparseAI,#NeuralNetworks,#ModelCompression,#EdgeAI,#TechLeadership

AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. By @antgrasso #AI #ModelCompression #Efficiency


Think of it like "language modeling as compression." When you compress the same info to its maximum, different algorithms converge. If architectures are similar, the underlying representations should also be converging. #ModelCompression #AI


AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. rt @antgrasso #AI #ModelCompression #Efficiency

Introducing Nota 🇰🇷 AI model compression technology that makes deep learning models run faster with less computing power. They help companies deploy AI on mobile devices without sacrificing performance. Efficiency-focused AI innovation. #AI #ModelCompression #MobileAI

AI model compression tools reduce size by 60%. Deploy on edge devices, scaling from cloud to IoT. @PublicAIData #ModelCompression #EdgeScaling
Excited to share: our paper “On Pruning State-Space LLMs” was accepted to EMNLP 2025! 🎉 Preprint: arxiv.org/abs/2502.18886 Code: github.com/schwartz-lab-N… Model: Smol-Mamba-1.9B → huggingface.co/schwartz-lab/S… w/ @MichaelHassid & @royschwartzNLP (HUJI) #Mamba #ModelCompression
AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. By @antgrasso #AI #ModelCompression #Efficiency
🔥 Read our Highly Cited Paper 📚Stable Low-Rank CP #Decomposition for Compression of Convolutional Neural Networks Based on Sensitivity 🔗mdpi.com/2076-3417/14/4… 👨🔬by Chenbin Yang and Huiyi Liu 🏫Hohai University #convolutionalneuralnetworks #modelcompression
Today's #PerfiosAITechTalk talks about how #ModelCompression can be used for efficient on-device runtimes. #NeuralNetworks #Datascience #ML #AI
The four common #ModelCompression techniques: 1) Quantization 2) Pruning 3) Knowledge distillation 4) Lower rank matrix factorization. What does your experience point you toward? #NeuralNetworks #DataScience #PerfiosAITechTalk

🧪 Subnetwork-only tuning outperforms full finetuning on many tasks. DPO: +1.6% PRIME: +2.4% Especially at higher difficulty levels. 📊 #ModelCompression #RLforLLMs

What do you mean by #ModelCompression? The answer is here, courtesy #NeuralNetworks expert @bsourav29 #PerfiosAITechTalk
What is #ModelCompression in #AI? #Infographic by @antgrasso #ArtificialIntelligence #MachineLearning #NeuralNetworks #DeepLearning #AIResearch #DataScience cc: @jeffkagan @SpirosMargaris @jblefevre60 @CES
AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. Microblog by @antgrasso #AI #ModelCompression #Efficiency…
Model compression in ICCLOUD! 8 - bit Quantization cuts memory by 75%, Weight Pruning reduces compute by 50%. Save resources! #ModelCompression #Resources
Think of it like "language modeling as compression." When you compress the same info to its maximum, different algorithms converge. If architectures are similar, the underlying representations should also be converging. #ModelCompression #AI
RT Model Compression: A Look into Reducing Model Size dlvr.it/RqDnWR #machinelearning #modelcompression #tinyml #deeplearning
RT How to adapt a multilingual T5 model for a single language dlvr.it/Rz5ltX #nlp #transformers #modelcompression #machinelearning #t5

Policy Compression for Intelligent Continuous Control on Low-Power Edge Devices mdpi.com/1424-8220/24/1… #modelcompression #softactor #edgecomputing


See you at #ICLR2025! ⭐ 📝 You Only Prune Once: Designing Calibration-Free Model Compression With Policy Learning 👥 Ayan Sengupta, Siddhant Chaudhary (@sid_codetalker7), Tanmoy Chakraborty (@Tanmoy_Chak) 💾 Code: github.com/LCS2-IIITD/Pru… #ModelCompression #NLProc

AI model compression isn't just a technical refinement but a strategic choice that aligns cost reduction, sustainability, and operational agility with the pressing demands of today's rapidly evolving digital landscape. Microblog by @antgrasso #AI #ModelCompression #Efficiency
Introducing Nota 🇰🇷 AI model compression technology that makes deep learning models run faster with less computing power. They help companies deploy AI on mobile devices without sacrificing performance. Efficiency-focused AI innovation. #AI #ModelCompression #MobileAI
Accuracy hides issues in quantized LLMs. 'Accuracy is Not All You Need' (NeurIPS 2024) shows 'flips' & KL-Divergence reveal output changes. #AI #ModelCompression #LLM

🔥New Research by Mr. Cesar Pachon, Prof. Diego Renza and Prof. Dora Ballesteros: "Is My Pruned Model Trustworthy? PE-Score: A New CAM-Based Evaluation Metric" @lamilitar #deeplearning #modelcompression #pruning #trustworthy #SeNPIS Access for Free: mdpi.com/2504-2289/7/2/…

RT A Variational Information Bottleneck (VIB) Based Method to Compress Sequential Networks for Human… dlvr.it/S6CRw3 #modelcompression #edgecomputing #sparsity #lstm #neuralnetworks

Something went wrong.
Something went wrong.
United States Trends
- 1. Vandy 6,427 posts
- 2. Carnell Tate 1,271 posts
- 3. Donaldson 1,512 posts
- 4. Vanderbilt 5,729 posts
- 5. French Laundry 3,452 posts
- 6. Clemson 8,255 posts
- 7. Christmas 129K posts
- 8. #HookEm 2,620 posts
- 9. Dalot 20.5K posts
- 10. Jeremiah Smith 1,080 posts
- 11. Julian Sayin 2,147 posts
- 12. Buckeyes 3,231 posts
- 13. Arch Manning 2,242 posts
- 14. Amad 22.5K posts
- 15. ESPN 80.4K posts
- 16. Jim Knowles N/A
- 17. Disney 90.9K posts
- 18. Colin Simmons N/A
- 19. #GoBucks 1,948 posts
- 20. Duke 17K posts