#llmperformance search results

Revolutionizing AI Evaluation: How Fluid Benchmarking Enhances LLM Assessment #ArtificialIntelligence #FluidBenchmarking #LLMPerformance #AIResearch #MachineLearning itinai.com/revolutionizin… In the rapidly evolving field of artificial intelligence, evaluating large language mod…


Struggling to optimize #LLMperformance for your content goals? Join our "Lost in Translation?" webinar on October 8 to learn why and how to course correct. Register now and get a free evaluation of 50,000 words! brnw.ch/21wVBXc
Is your #AIsolution up to the task? In our recent webinar, Simone Lamont, VP of Global Solutions at Lionbridge, offered practical steps for evaluating #LLMperformance and #translationquality. Hear from Simone below, or check out our webinar recap: brnw.ch/21wX3Zq

7️⃣ 📊 Results? Big wins. For Qwen2-7B, SENATOR boosts performance on tough medical exams (like GPQA Genetics) by up to +37.5%! Even with less training data than traditional methods. #LLMperformance


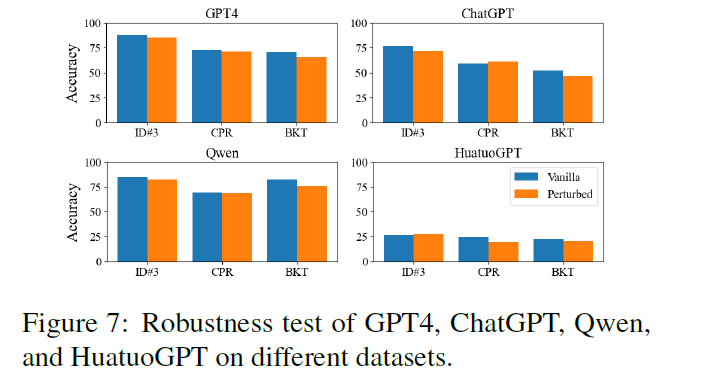
4/ How do models perform? - Evaluated models include GPT-4, ChatGPT, ERNIE-Bot, Qwen, and others. - Even GPT-4 scored only 69.2%, highlighting the challenge of medical reasoning tasks - Chinese medical LLMs underperform, pointing to major areas for improvement #LLMPerformance…
5/7 📊 The study evaluated multiple LLMs including GPT-4o, OpenBioLLM, and Llama3-70B, showing that even advanced models struggle to consistently match human judgment in complex medical scenarios. GPT-4o achieved a notable but modest 52% accuracy. #LLMPerformance #GPT4


What are the key considerations when it comes to cost control 💵 and #LLMs? Hear from Jed Dougherty, Dataiku's VP of Platform Strategy, for the two-minute overview below or check out the full #LLMMesh video here: | bit.ly/49lHD0w | #LLMPerformance #LLMCosts

𝗛𝗼𝘄 𝗡𝗮𝘁𝘂𝗿𝗮𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗕𝗼𝗹𝘀𝘁𝗲𝗿𝘀 𝗟𝗟𝗠 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗶𝗻 𝗗𝗶𝘃𝗲𝗿𝘀𝗲 𝗙𝗶𝗲𝗹𝗱𝘀 rb.gy/lzmmje #LLMPerformance #NaturalLanguageProcessing #LargeLanguageModels #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine

Four Cutting-Edge Methods for Evaluating AI Agents and Enhancing LLM Performance itinai.com/four-cutting-e… #AIAgents #LLMperformance #MachineLearning #DataAnalysis #InnovationInAI #ai #news #llm #ml #research #ainews #innovation #artificialintelligence #machinelearning #technol…


Unlocking LLM potential requires integrating domain-specific knowledge into the data lifecycle. Tools like InstructLab help manage diverse data types for improved model training. 📊💡 #LLMPerformance #DomainKnowledge #DataIntegration #Youtube link: ift.tt/Y68th3o


Boosting LLM Performance on RTX: Leveraging LM Studio and GPU Offloading: Explore how GPU offloading with LM Studio enables efficient local execution of large language models on RTX-powered… dlvr.it/TFfJnG #LLMPerformance #RTX #GPUOffloading #LMStudio #AIApplications

Exploring the Dual Nature of RAG Noise: Enhancing Large Language Models Through Beneficial Noise and Mitigating Harmful Effects itinai.com/exploring-the-… #AIresearch #RAGnoise #LLMperformance #beneficialnoise #automationopportunities #ai #news #llm #ml #research #ainews #innova…

Cracking the Code of AI Alignment: This AI Paper from the University of Washington and Meta FAIR Unveils Better Alignment with Instruction Back-and-Forth Translation itinai.com/cracking-the-c… #AIAlignment #InstructionTranslation #LLMPerformance #AIAdvancements #AIInnovation #ai…


Now a session on #LLMperformance with @chipro @GregoryDiamos Ankit Mathur David Kanter Beyang Liu #LLMavalanche by @ChiefScientist lnkd.in/exjUjJze

LM Cache boosts LLM efficiency, scalability, and cost savings by letting the system remember previous outputs and complementing other optimizations. - hackernoon.com/optimizing-llm… #llmperformance #caching
hackernoon.com
Optimizing LLM Performance with LM Cache: Architectures, Strategies, and Real-World Applications |...
LM Cache boosts LLM efficiency, scalability, and cost savings by letting the system remember previous outputs and complementing other optimizations.


🤔 Did you know? When asked to ‘think step by step’, ChatGPT's accuracy jumps from 25% to 90%! System prompts reveal the potential of tweaking LLMs for better performance. 🧠 buff.ly/45nSbsD #ChatGPT #LLMPerformance

(3/9) Factor 1: Performance & Accuracy. Don't just rely on general benchmarks! Evaluate how well the model performs on *your specific tasks*. Are responses relevant, high-quality & coherent? Does it follow instructions precisely? #LLMPerformance

⚖️ GPT-4o scores 86.4% on MMLU. 🧾 Perplexity gives 50+ citations per query. 🧠 Grok3 links 93% of its claims to sources. Which model really earns your trust? 📖 medium.com/@rogt.x1997/gp… #AIbenchmarking #GenerativeAI #LLMperformance #TowardsAI
medium.com
GPT-4o vs.
🔍 How the Top Three AI Models Compete, Collaborate, and Confuse in Our Search for What’s Real

🚀#NewBlog @vllm_project 🔥 𝐯𝐋𝐋𝐌 𝐟𝐨𝐫 𝐁𝐞𝐠𝐢𝐧𝐧𝐞𝐫𝐬 𝐏𝐚𝐫𝐭 𝟐:📖𝐊𝐞𝐲 𝐅𝐞𝐚𝐭𝐮𝐫𝐞𝐬 & 𝐎𝐩𝐭𝐢𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧s💫 💎 What makes #vLLM the Rolls Royce of inference? 👉check it out: cloudthrill.ca/what-is-vllm-f… @vllm_project @lmcache #LLMPerformance

Is your #AIsolution up to the task? In our recent webinar, Simone Lamont, VP of Global Solutions at Lionbridge, offered practical steps for evaluating #LLMperformance and #translationquality. Hear from Simone below, or check out our webinar recap: brnw.ch/21wX3Zq
Revolutionizing AI Evaluation: How Fluid Benchmarking Enhances LLM Assessment #ArtificialIntelligence #FluidBenchmarking #LLMPerformance #AIResearch #MachineLearning itinai.com/revolutionizin… In the rapidly evolving field of artificial intelligence, evaluating large language mod…
Struggling to optimize #LLMperformance for your content goals? Join our "Lost in Translation?" webinar on October 8 to learn why and how to course correct. Register now and get a free evaluation of 50,000 words! brnw.ch/21wVBXc
LM Cache boosts LLM efficiency, scalability, and cost savings by letting the system remember previous outputs and complementing other optimizations. - hackernoon.com/optimizing-llm… #llmperformance #caching
hackernoon.com
Optimizing LLM Performance with LM Cache: Architectures, Strategies, and Real-World Applications |...
LM Cache boosts LLM efficiency, scalability, and cost savings by letting the system remember previous outputs and complementing other optimizations.

SWE-Lancer, which measures models’ ability to code by having them complete real tasks on Upwork. WindowsAgentArena, which specifically tests AI agents’ ability to navigate a Windows operating system and apps like Excel and PowerPoint. bit.ly/46rrRCh #llmperformance


It seems that Grok needs to be more brave to discover new math. Probably, bravery requires more parameters. @grok #GPT #LLM #llmperformance
Witness multi-token prediction's transformative power across seven large-scale experiments: unlocking exponential gains with model size, 3x faster inference - hackernoon.com/unrivaled-llm-… #multitokenprediction #llmperformance
hackernoon.com
Unrivaled LLM Efficacy: Multi-Token Prediction Revolutionizes Performance Across Domains | Hacker...
Witness multi-token prediction's transformative power across seven large-scale experiments: unlocking exponential gains with model size, 3x faster inference
🚀#NewBlog @vllm_project 🔥 𝐯𝐋𝐋𝐌 𝐟𝐨𝐫 𝐁𝐞𝐠𝐢𝐧𝐧𝐞𝐫𝐬 𝐏𝐚𝐫𝐭 𝟐:📖𝐊𝐞𝐲 𝐅𝐞𝐚𝐭𝐮𝐫𝐞𝐬 & 𝐎𝐩𝐭𝐢𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧s💫 💎 What makes #vLLM the Rolls Royce of inference? 👉check it out: cloudthrill.ca/what-is-vllm-f… @vllm_project @lmcache #LLMPerformance

3/8 📈 Performance boost: +90.2%! Claude’s multi-agent engine crushed breadth-first queries (e.g. S&P500 board scans) 90.2% better than single-agent Claude Opus 4. #AIbenchmarks #ClaudeOpus #LLMperformance #AIproductivity
7️⃣ 📊 Results? Big wins. For Qwen2-7B, SENATOR boosts performance on tough medical exams (like GPQA Genetics) by up to +37.5%! Even with less training data than traditional methods. #LLMperformance
⚖️ GPT-4o scores 86.4% on MMLU. 🧾 Perplexity gives 50+ citations per query. 🧠 Grok3 links 93% of its claims to sources. Which model really earns your trust? 📖 medium.com/@rogt.x1997/gp… #AIbenchmarking #GenerativeAI #LLMperformance #TowardsAI
medium.com
GPT-4o vs.
🔍 How the Top Three AI Models Compete, Collaborate, and Confuse in Our Search for What’s Real
🧠💸 Is your GenAI stack burning cash just to stay responsive? We ran 10K+ simulations to prove a point: timing inference can save millions. 🔄 Smarter schedules > more GPUs Read the forecasting 👉 medium.com/@rogt.x1997/th… #AIEngineering #CostOptimization #LLMperformance
medium.com
The Inference Forecasting Secret: Why Your AI Stack Might Be Overpaying to Sound Smart…
Using Predictive Analytics to Make AI More Affordable and Scalable 🧠

.@UiPath AI agents are available in its broader #RPA platform for selective use as the industry awaits improved #LLMPerformance and cost. bit.ly/44S6NDZ


Stop wasting AI resources! Learn how Prompt Caching slashes response times to <500ms and cuts costs by 70%. Check out our latest blog on optimizing AI efficiency! innovationm.co/optimizing-ai-… #LLMPerformance #MachineLearning #InnovationM
Revolutionizing AI Evaluation: How Fluid Benchmarking Enhances LLM Assessment #ArtificialIntelligence #FluidBenchmarking #LLMPerformance #AIResearch #MachineLearning itinai.com/revolutionizin… In the rapidly evolving field of artificial intelligence, evaluating large language mod…
7️⃣ 📊 Results? Big wins. For Qwen2-7B, SENATOR boosts performance on tough medical exams (like GPQA Genetics) by up to +37.5%! Even with less training data than traditional methods. #LLMperformance
4/ How do models perform? - Evaluated models include GPT-4, ChatGPT, ERNIE-Bot, Qwen, and others. - Even GPT-4 scored only 69.2%, highlighting the challenge of medical reasoning tasks - Chinese medical LLMs underperform, pointing to major areas for improvement #LLMPerformance…
𝗛𝗼𝘄 𝗡𝗮𝘁𝘂𝗿𝗮𝗹 𝗟𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗕𝗼𝗹𝘀𝘁𝗲𝗿𝘀 𝗟𝗟𝗠 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗶𝗻 𝗗𝗶𝘃𝗲𝗿𝘀𝗲 𝗙𝗶𝗲𝗹𝗱𝘀 rb.gy/lzmmje #LLMPerformance #NaturalLanguageProcessing #LargeLanguageModels #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine
5/7 📊 The study evaluated multiple LLMs including GPT-4o, OpenBioLLM, and Llama3-70B, showing that even advanced models struggle to consistently match human judgment in complex medical scenarios. GPT-4o achieved a notable but modest 52% accuracy. #LLMPerformance #GPT4
Four Cutting-Edge Methods for Evaluating AI Agents and Enhancing LLM Performance itinai.com/four-cutting-e… #AIAgents #LLMperformance #MachineLearning #DataAnalysis #InnovationInAI #ai #news #llm #ml #research #ainews #innovation #artificialintelligence #machinelearning #technol…
Boosting LLM Performance on RTX: Leveraging LM Studio and GPU Offloading: Explore how GPU offloading with LM Studio enables efficient local execution of large language models on RTX-powered… dlvr.it/TFfJnG #LLMPerformance #RTX #GPUOffloading #LMStudio #AIApplications
Exploring the Dual Nature of RAG Noise: Enhancing Large Language Models Through Beneficial Noise and Mitigating Harmful Effects itinai.com/exploring-the-… #AIresearch #RAGnoise #LLMperformance #beneficialnoise #automationopportunities #ai #news #llm #ml #research #ainews #innova…
Cracking the Code of AI Alignment: This AI Paper from the University of Washington and Meta FAIR Unveils Better Alignment with Instruction Back-and-Forth Translation itinai.com/cracking-the-c… #AIAlignment #InstructionTranslation #LLMPerformance #AIAdvancements #AIInnovation #ai…
Unlocking LLM potential requires integrating domain-specific knowledge into the data lifecycle. Tools like InstructLab help manage diverse data types for improved model training. 📊💡 #LLMPerformance #DomainKnowledge #DataIntegration #Youtube link: ift.tt/Y68th3o
Something went wrong.
Something went wrong.
United States Trends
- 1. #River 5,857 posts
- 2. Jokic 28K posts
- 3. Lakers 53.1K posts
- 4. Namjoon 64.6K posts
- 5. FELIX VOGUE COVER STAR 7,751 posts
- 6. #FELIXxVOGUEKOREA 8,181 posts
- 7. Rejoice in the Lord 1,154 posts
- 8. #ReasonableDoubtHulu N/A
- 9. #AEWDynamite 51.5K posts
- 10. #PieMeACoffee 4,270 posts
- 11. Clippers 15.2K posts
- 12. Shai 16.8K posts
- 13. Simon Nemec 2,364 posts
- 14. Thunder 41K posts
- 15. Mikey 73.5K posts
- 16. Visi 7,745 posts
- 17. Rory 8,466 posts
- 18. Ty Lue 1,272 posts
- 19. Valve 62.3K posts
- 20. Steph 31.9K posts