#machinelearningdeeplearning 検索結果

International Conference on Intelligent Data Engineering and Automated Learning (IDEAL 2020) islab.di.uminho.pt/ideal2020/ #BigDataAnalytics #BioandNeuroInformatics #MachineLearningDeepLearning #BioInspiredModels #DataMining


Machine Learning 101 – The Problem-Solution Paradigm goo.gl/MjQfev #MachineLearningDeepLearning #MachineLearningArtificialIntellligence #MachineLearningTechnology


🏆 Day 21 of #MachineLearningDeepLearning! 🎯 On my Journey of Machine Learning and Deep Learning, I have started reading the book "Deep Learning - Ian Goodfellow". Here, I have read about Introduction to DL, Scalars, Vectors, Matrices and Tensors, Rando…lnkd.in/gWeY4RKb
linkedin.com
#machinelearningdeeplearning #66daysofdata #machinelearning #deeplearning #datascience #artificia...
🏆 Day 21 of #MachineLearningDeepLearning! 🎯 On my Journey of Machine Learning and Deep Learning, I have started reading the book "Deep Learning - Ian Goodfellow". Here, I have read about Introduc...
🏆 Day 2 of #MachineLearningDeepLearning! 🎯 On my Journey of Machine Learning and Deep Learning, I have been reading the book "Deep Learning for Computer Vision with Python". Here, I have read about Image Classification, OpenCV, Animals Dataset, Raw Pix…lnkd.in/dmCwJpKC
🏆 Day 22 of #MachineLearningDeepLearning! 💡 Pattern Recognition: The field of pattern recognition is concerned with the automatic discovery of regularities in data through the use of computer algorithms and with the use of these regularities to take a…lnkd.in/g3z_N5-N

Top Stories, Apr 5-11: Awesome Tricks And Best Practices From Kaggle; How to deploy Machine Learning/Deep Learning mo... #data #machinelearningdeeplearning #kdnuggets kdnuggets.com/?p=125489
🏆 Day 22 of #MachineLearningDeepLearning! 💡 Pattern Recognition: The field of pattern recognition is concerned with the automatic discovery of regularities in data through the use of computer algorithms and with the use of these regularities to take a…lnkd.in/g3z_N5-N
🏆 Day 21 of #MachineLearningDeepLearning! 🎯 On my Journey of Machine Learning and Deep Learning, I have started reading the book "Deep Learning - Ian Goodfellow". Here, I have read about Introduction to DL, Scalars, Vectors, Matrices and Tensors, Rando…lnkd.in/gWeY4RKb
linkedin.com
#machinelearningdeeplearning #66daysofdata #machinelearning #deeplearning #datascience #artificia...
🏆 Day 21 of #MachineLearningDeepLearning! 🎯 On my Journey of Machine Learning and Deep Learning, I have started reading the book "Deep Learning - Ian Goodfellow". Here, I have read about Introduc...
Top Stories, Apr 5-11: Awesome Tricks And Best Practices From Kaggle; How to deploy Machine Learning/Deep Learning mo... #data #machinelearningdeeplearning #kdnuggets kdnuggets.com/?p=125489
International Conference on Intelligent Data Engineering and Automated Learning (IDEAL 2020) islab.di.uminho.pt/ideal2020/ #BigDataAnalytics #BioandNeuroInformatics #MachineLearningDeepLearning #BioInspiredModels #DataMining
Machine Learning 101 – The Problem-Solution Paradigm goo.gl/MjQfev #MachineLearningDeepLearning #MachineLearningArtificialIntellligence #MachineLearningTechnology

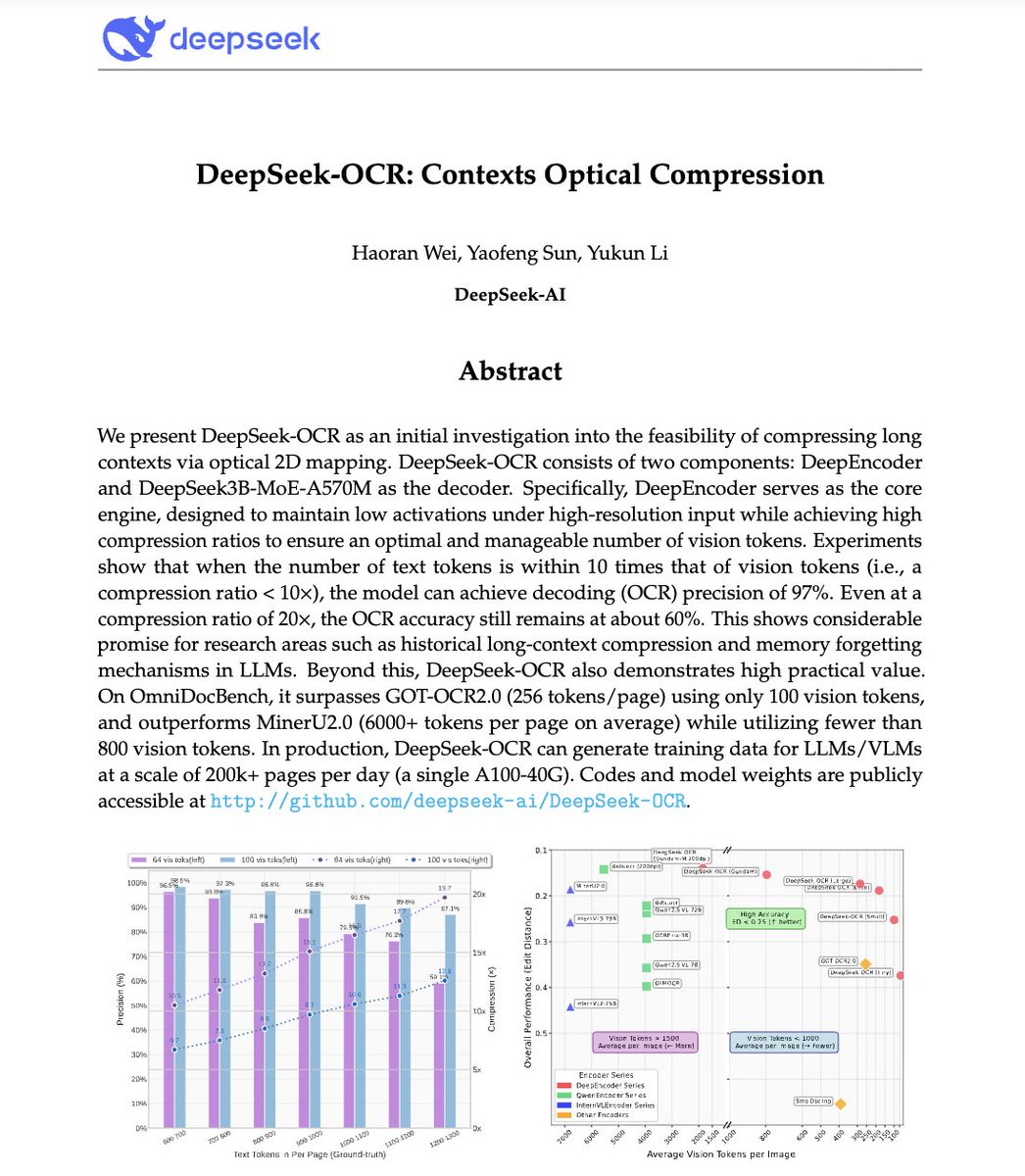
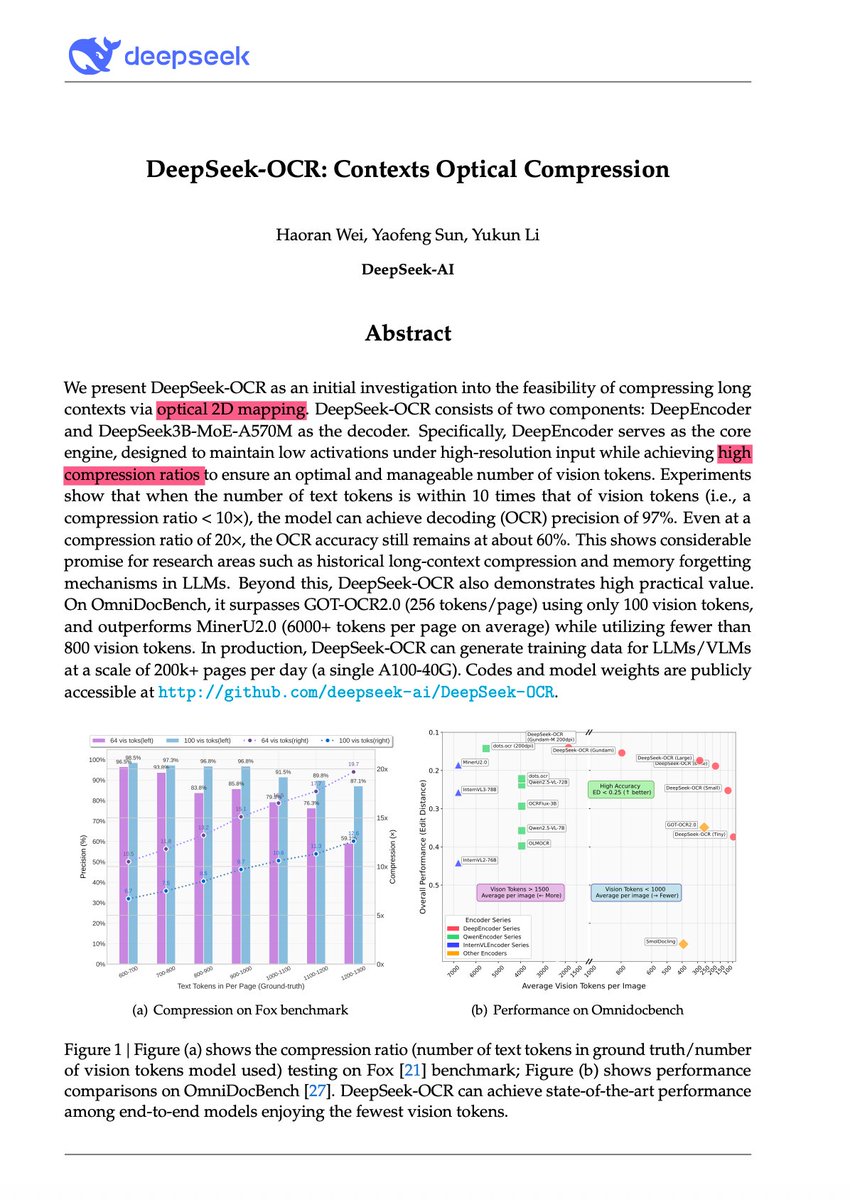
🚨 DeepSeek just did something wild. They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels. Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That…

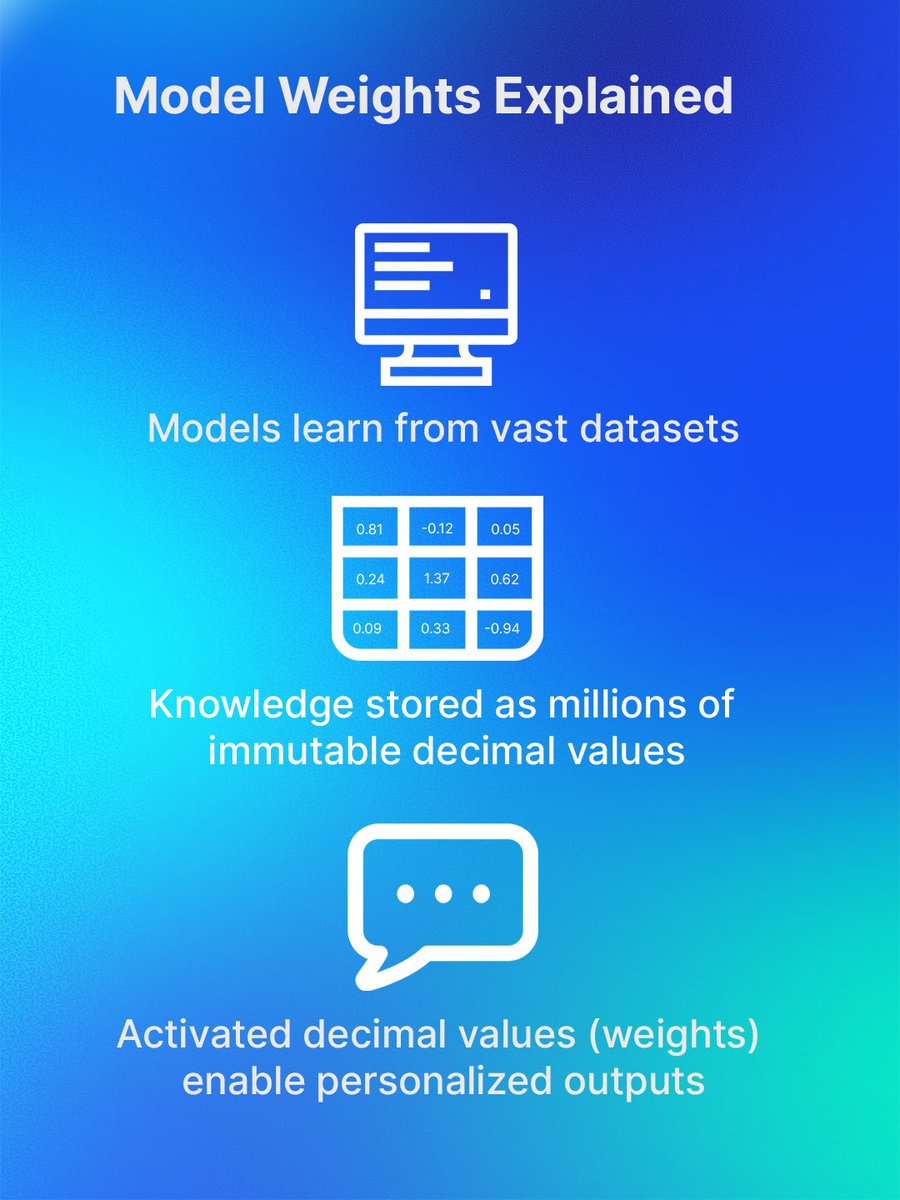
AI Models learn patterns through training, which sets fixed rules (weights). During responses, they use attention mechanisms to dynamically focus on relevant parts of your specific input.

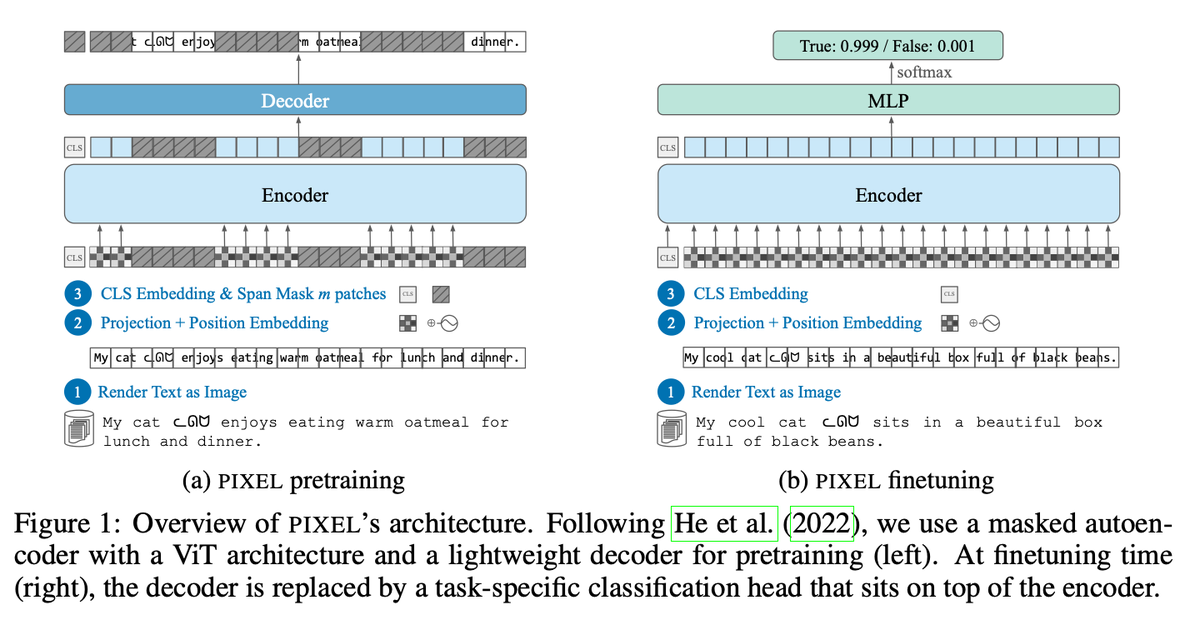
DeepSeek-OCR looks impressive, but its core idea is not new. Input “Text” as “Image” — already explored by: LANGUAGE MODELING WITH PIXELS (Phillip et al., ICLR 2023) CLIPPO: Image-and-Language Understanding from Pixels Only (Michael et al. CVPR 2023) Pix2Struct: Screenshot…
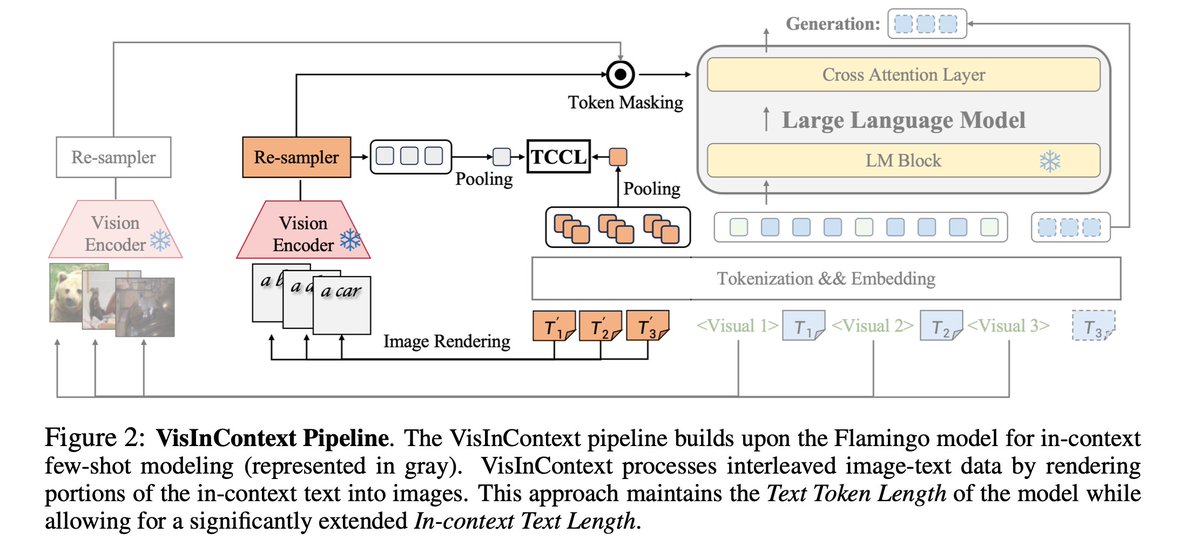
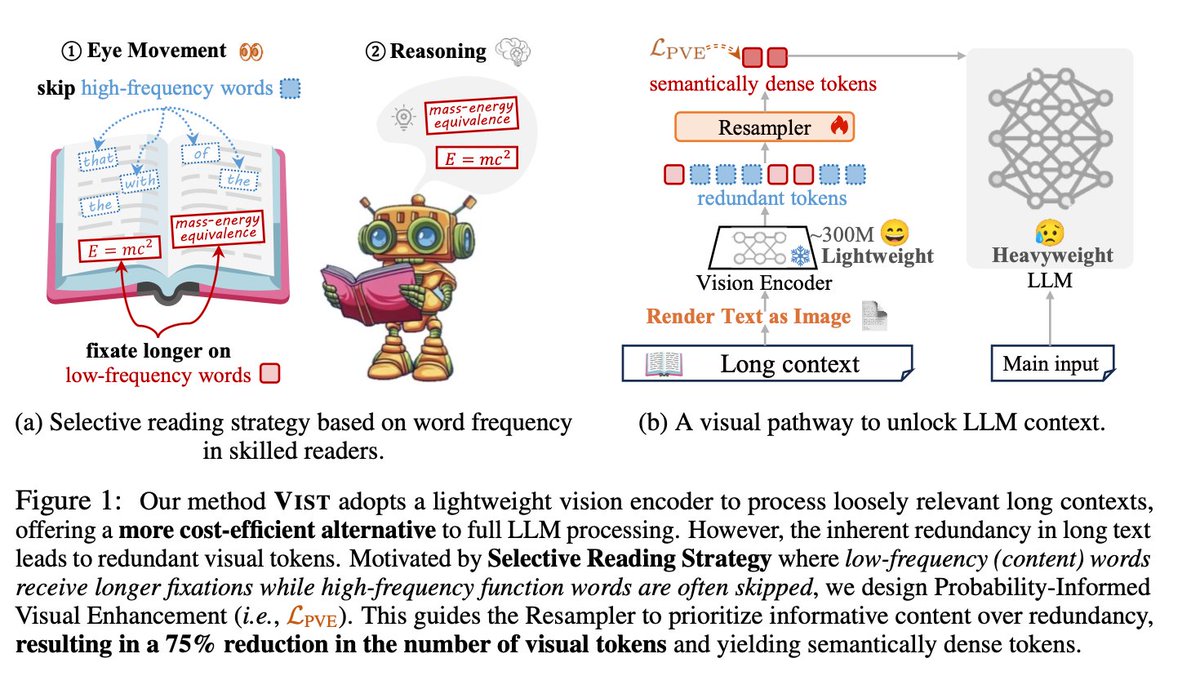

A more serious thread on the DeepSeek-OCR hype / serious misinterpretation going on. 1. On token reduction via representing text in images, researchers from Cambridge have previously shown that 500x prompt token compression is possible (ACL'25, Li, Su, and Collier). Without…

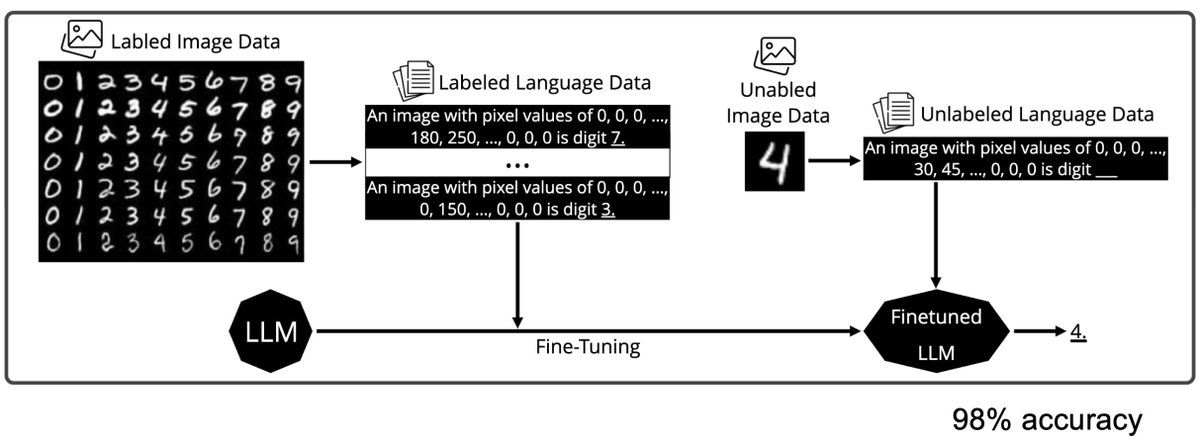
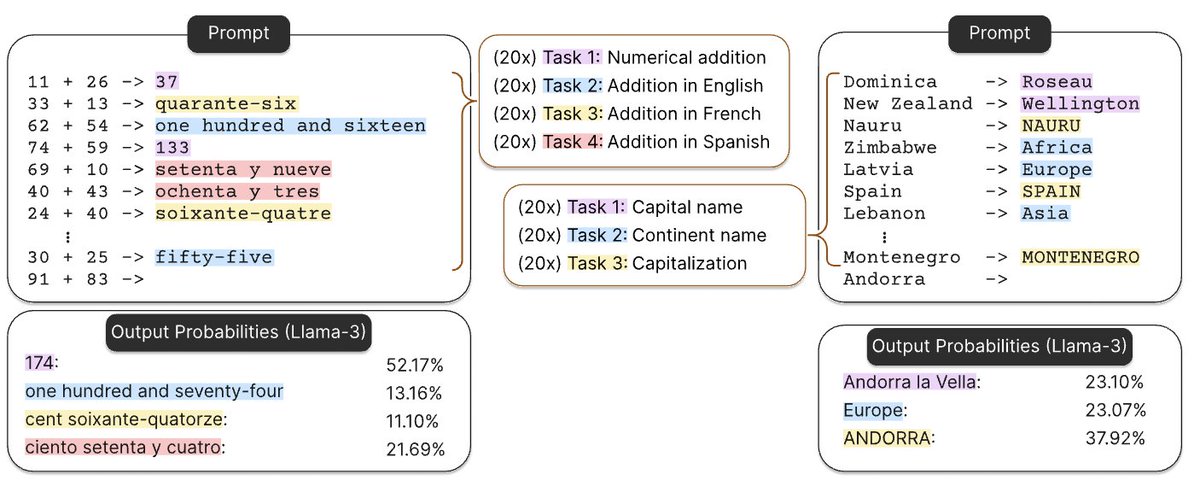

This new Deepseek release might have some AI labs rethinking if they should switch from using text and tokens to using… pixels.



This is the JPEG moment for AI. Optical compression doesn't just make context cheaper. It makes AI memory architectures viable. Training data bottlenecks? Solved. - 200k pages/day on ONE GPU - 33M pages/day on 20 nodes - Every multimodal model is data-constrained. Not anymore.…


☠️ Bienvenidos al círculo del infierno laboral donde algoritmos rechazan a algoritmos 🤖 #chatgpt #ia #inteligenciaartificial #empleo #desempleo #reclutamiento #trabajo #cv #sociedad #tecnologia #pictoline





BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…
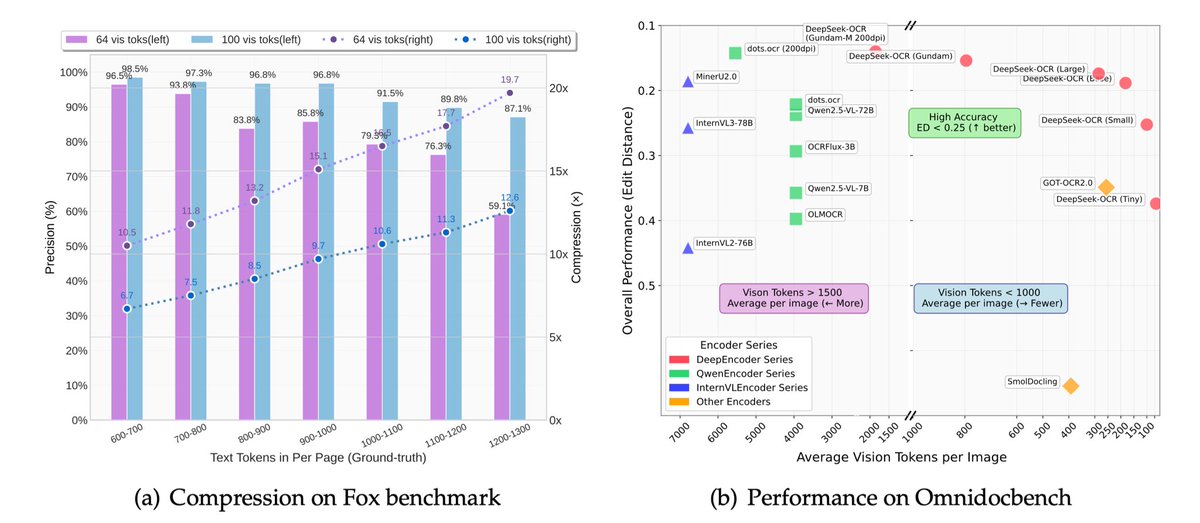

𝐡𝐞𝐫𝐞 𝐰𝐢𝐭𝐡 𝐚𝐧𝐨𝐭𝐡𝐞𝐫 𝐜𝐨𝐦𝐩𝐚𝐫𝐢𝐬𝐨𝐧 𝐛𝐞𝐭𝐰𝐞𝐞𝐧 𝐞𝐯𝐞𝐫𝐥𝐲𝐧 𝐚𝐢 𝐚𝐧𝐝 𝐢𝐦𝐚𝐠𝐞 𝐟𝐱 𝐛𝐲 𝐠𝐨𝐨𝐠𝐥𝐞 𝐥𝐚𝐛𝐬 ➙ left image generated using @everlyn_ai, generated in 11.8s ➙ right image: image fx by google labs which would you go for ? and why?



I don’t know if you guys have used Xiaomi’s filter options ( in their Leica optimised phones ) but they’re really good 📸 Xiaomi 15T Pro





what happened this week with OCR and VLMs? * deepseek-ocr * chandra-ocr * nanonets-ocr2 * paddleocr-vl * qwen3-vl (2B, 32B, Instruct and Thinking) * dots.ocr * olmOCR 2 (based on Qwen2.5-VL) * LightOnOCR (smallies) top 5 trending models on @huggingface are still OCR/VLM!

We will introduce DeepSeek, GPT-5, Grok, and Qwen to assist with predictions. Users can view the prediction accuracy and profitability of each AI. 0x139d5d5d871786425c63ee087454fd8e23964444

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…




Goodbye retouch apps You don’t need editing skills to look picture-perfect anymore. Now, your photos understand what you say and transform themselves. Let’s show you how:


DeepSeek finally released a new model and paper. And because this DeepSeek-OCR release is a bit different from what everyone expected, and DeepSeek releases are generally a big deal, I wanted to do a brief explainer of what it is all about. In short, they explore how vision…




Introducing DINOv3 🦕🦕🦕 A SotA-enabling vision foundation model, trained with pure self-supervised learning (SSL) at scale. High quality dense features, combining unprecedented semantic and geometric scene understanding. Three reasons why this matters…

Something went wrong.
Something went wrong.
United States Trends
- 1. Chauncey Billups 82.5K posts
- 2. Terry Rozier 77.8K posts
- 3. #FalloutDay 4,712 posts
- 4. Mafia 116K posts
- 5. Damon Jones 23.5K posts
- 6. Binance 188K posts
- 7. Ti West 2,413 posts
- 8. #7_years_with_ATEEZ 68.3K posts
- 9. Tiago Splitter 3,015 posts
- 10. #에이티즈_7주년_항해는_계속된다 53.7K posts
- 11. #A_TO_Z 52.9K posts
- 12. The FBI 172K posts
- 13. Changpeng Zhao 18.6K posts
- 14. Gambling 165K posts
- 15. The NBA 219K posts
- 16. Kash Patel 47.5K posts
- 17. Kirby Air Riders 11K posts
- 18. Gilbert Arenas 8,882 posts
- 19. New Vegas 6,070 posts
- 20. La Cosa Nostra 9,376 posts