#pdsabook search results

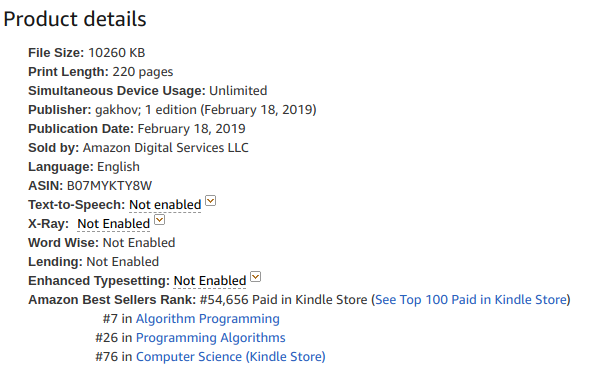
Just getting in the TOP 10 of Paid Kindle books in "Algorithm Programming" 🔝 #PDSABook #Algorithms #Kindlebook
When you need to count number of unique elements very fast and your expected cardinality isn't too large, use the Linear Counting algorithm. It requires one pass, constant memory, and performs very well if you accept some tiny error. #PDSABook #Cardinality #BigData #Algorithms

Do you know that the cardinality aggregation in Elasticsearch @elastic is powered by the #probabilistic data structure HyperLogLog++ since version 1.1.0! This is why it's so efficient, but also it is the reason why you cannot expect to get the exact counts #PDSABook #Algorithms
Join #Pittsburgh Code & Supply Meetup to learn about #Probabilistic Data Structures for Counting. If you cannot make it, watch the presentation at youtube.com/watch?v=kj-mkX… #PDSABook #PDSA #BigData #Python #Cython
youtube.com
YouTube
Too Much Data? - Just Sample, Just Hash, ...
Bloom Indexes in #PostgreSQL #PDSABook #BloomFilter @pdsa_book percona.com/blog/2019/06/1…
percona.com
Bloom Indexes in PostgreSQL
Bloom indexes in PostgreSQL are helpful when there is a table storing huge amounts of data and a lot of columns.
Bloom filter is not the only probabilistic data structure. Take a look at HyperLogLog, Count-Min Sketch, t-digest, Simhash... and many others. pdsa.gakhov.com #PDSABook
pdsa.gakhov.com
Book: Probabilistic data structures and algorithms
Probabilistic data structures and algorithms for Big Data applications.
When you make a read request for some partition, Apache @cassandra has to merge in-RAM and on-disk data. To avoid loading each data file, it uses such well-known #probabilistic data structure as Bloom filter (with 0.1% false positive probability) #PDSABook cassandra.apache.org/doc/latest/ope…

RT @gakhov Bloom Indexes in #PostgreSQL #PDSABook #BloomFilter @pdsa_book percona.com/blog/2019/06/1… #cloud #devops
A copy of my recent book "Probabilistic Data Structures and Algorithms for Big Data Applications" #PDSABook I've sent to my alma mater - Karazin Kharkiv National University @KarazinUniver and now it's available for students in Karazin Library @biblio2016 library.univer.kharkov.ua/OpacUnicode/in…
A copy of my recent book "Probabilistic Data Structures and Algorithms for Big Data Applications" #PDSABook I've sent to my alma mater - Karazin Kharkiv National University @KarazinUniver and now it's available for students in Karazin Library @biblio2016 library.univer.kharkov.ua/OpacUnicode/in…
Bloom filter is not the only probabilistic data structure. Take a look at HyperLogLog, Count-Min Sketch, t-digest, Simhash... and many others. pdsa.gakhov.com #PDSABook
pdsa.gakhov.com
Book: Probabilistic data structures and algorithms
Probabilistic data structures and algorithms for Big Data applications.
RT @gakhov Bloom Indexes in #PostgreSQL #PDSABook #BloomFilter @pdsa_book percona.com/blog/2019/06/1… #cloud #devops
Bloom Indexes in #PostgreSQL #PDSABook #BloomFilter @pdsa_book percona.com/blog/2019/06/1…
percona.com
Bloom Indexes in PostgreSQL
Bloom indexes in PostgreSQL are helpful when there is a table storing huge amounts of data and a lot of columns.
Join #Pittsburgh Code & Supply Meetup to learn about #Probabilistic Data Structures for Counting. If you cannot make it, watch the presentation at youtube.com/watch?v=kj-mkX… #PDSABook #PDSA #BigData #Python #Cython
youtube.com
YouTube
Too Much Data? - Just Sample, Just Hash, ...
When you make a read request for some partition, Apache @cassandra has to merge in-RAM and on-disk data. To avoid loading each data file, it uses such well-known #probabilistic data structure as Bloom filter (with 0.1% false positive probability) #PDSABook cassandra.apache.org/doc/latest/ope…
Do you know that the cardinality aggregation in Elasticsearch @elastic is powered by the #probabilistic data structure HyperLogLog++ since version 1.1.0! This is why it's so efficient, but also it is the reason why you cannot expect to get the exact counts #PDSABook #Algorithms
Just getting in the TOP 10 of Paid Kindle books in "Algorithm Programming" 🔝 #PDSABook #Algorithms #Kindlebook
When you need to count number of unique elements very fast and your expected cardinality isn't too large, use the Linear Counting algorithm. It requires one pass, constant memory, and performs very well if you accept some tiny error. #PDSABook #Cardinality #BigData #Algorithms
Just getting in the TOP 10 of Paid Kindle books in "Algorithm Programming" 🔝 #PDSABook #Algorithms #Kindlebook
Something went wrong.
Something went wrong.
United States Trends
- 1. Klay 19.6K posts
- 2. #AEWFullGear 69.5K posts
- 3. Lando 95.5K posts
- 4. McLaren 42K posts
- 5. #LasVegasGP 180K posts
- 6. LAFC 15.1K posts
- 7. Hangman 9,716 posts
- 8. Samoa Joe 4,637 posts
- 9. Ja Morant 8,579 posts
- 10. Gambino 2,183 posts
- 11. Swerve 6,306 posts
- 12. #Toonami 2,782 posts
- 13. Bryson Barnes N/A
- 14. Verstappen 77.1K posts
- 15. Utah 23.9K posts
- 16. Benavidez 15.7K posts
- 17. Kimi 37.4K posts
- 18. Mark Briscoe 4,372 posts
- 19. Fresno State 1,003 posts
- 20. Terry Crews 7,417 posts