#swebench search results

やばすぎwww 最新のSWE-Bench Pro結果が公開、GPT-5が頭ひとつ抜けてるぞwww 🔥 GPT-5:23.26点で首位 🤖 Claude Opus 4.1が僅差で追随 💡 Gemini 2.5 ProやQwen3はまだ下位に沈む結果 Claude 4.5とGemini 3のスコア出たらAI戦争さらに激化するな… #AI #SWEbench


Verdent coding agent atinge 76,1% no SWE-bench Verified, integrando IA de ponta p/ codificação, revisão e depuração via VS Code e app autônomo. Vale a pena discutir? Comente ou acesse. #IA #SWEbench rendageek.com.br/noticias/verde…

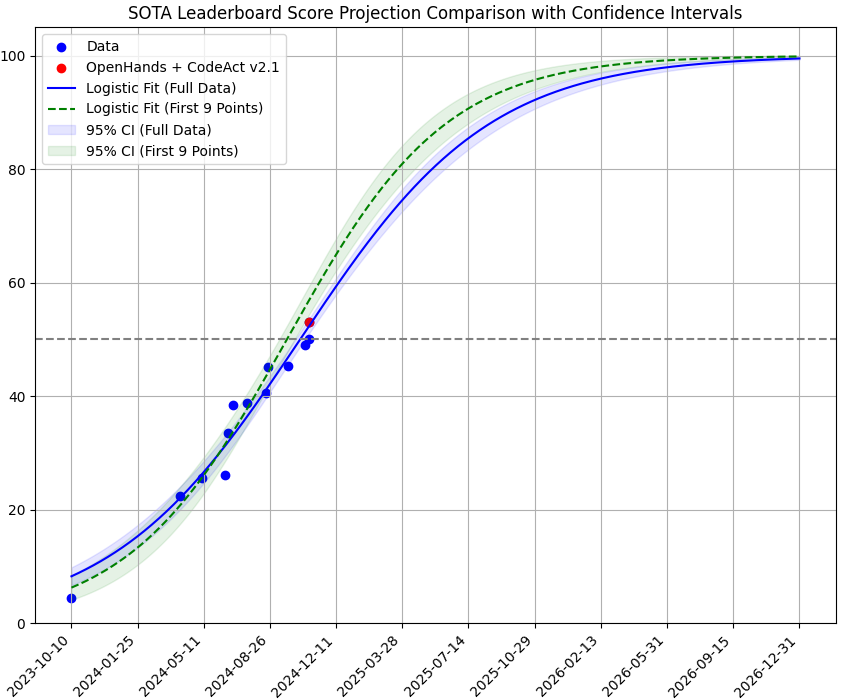
figure 1 in green was my initial projection assuming inflection point=50. Updated with the latest results and notice slope is decreasing (blue), so unless we see a score above 60 in the next month or so the inflection point may be closer to 30(red) than 50 #swebench


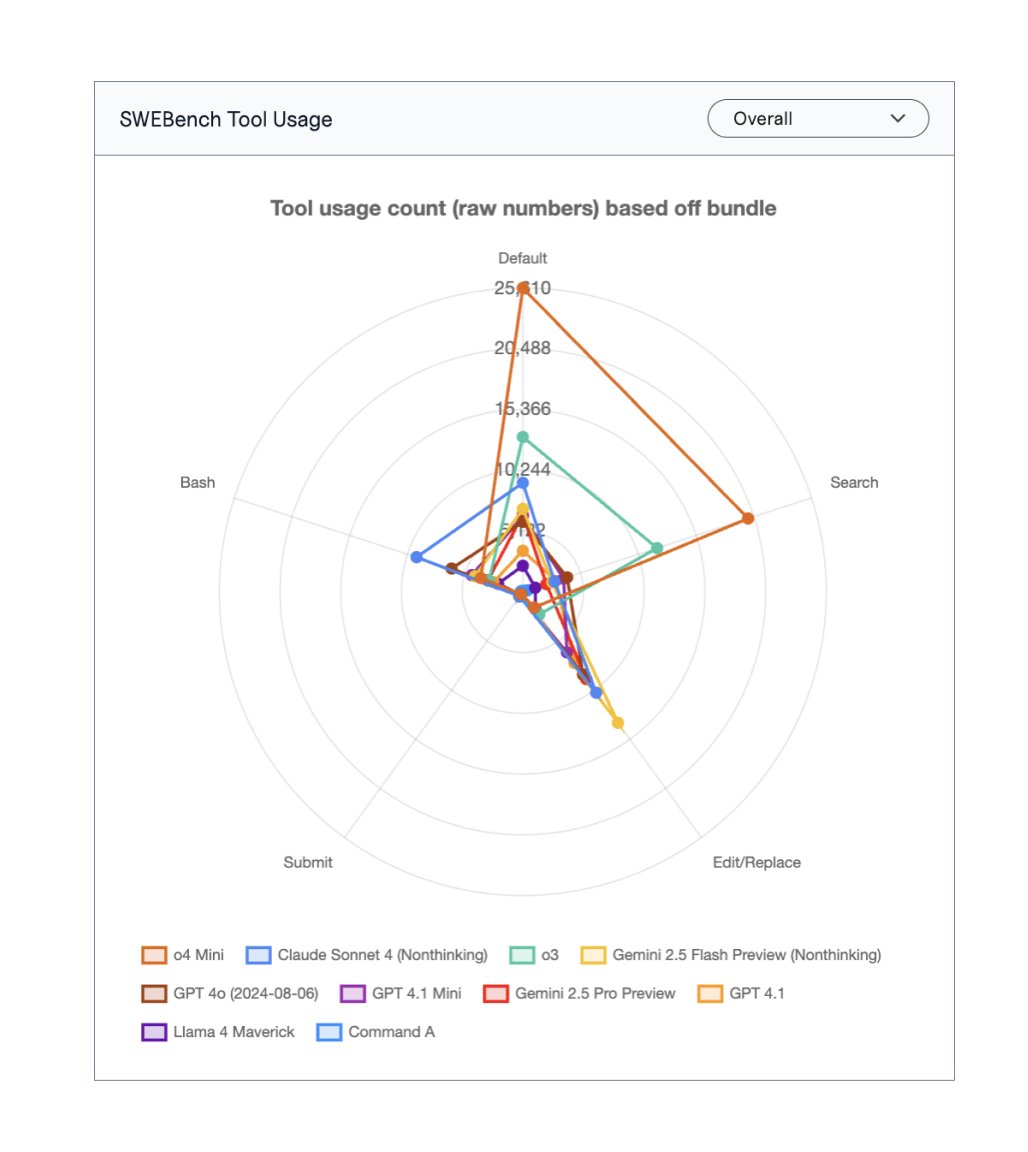
github.com/SWE-agent/SWE-… Loved this repo, and people behind the agent #SWEBench



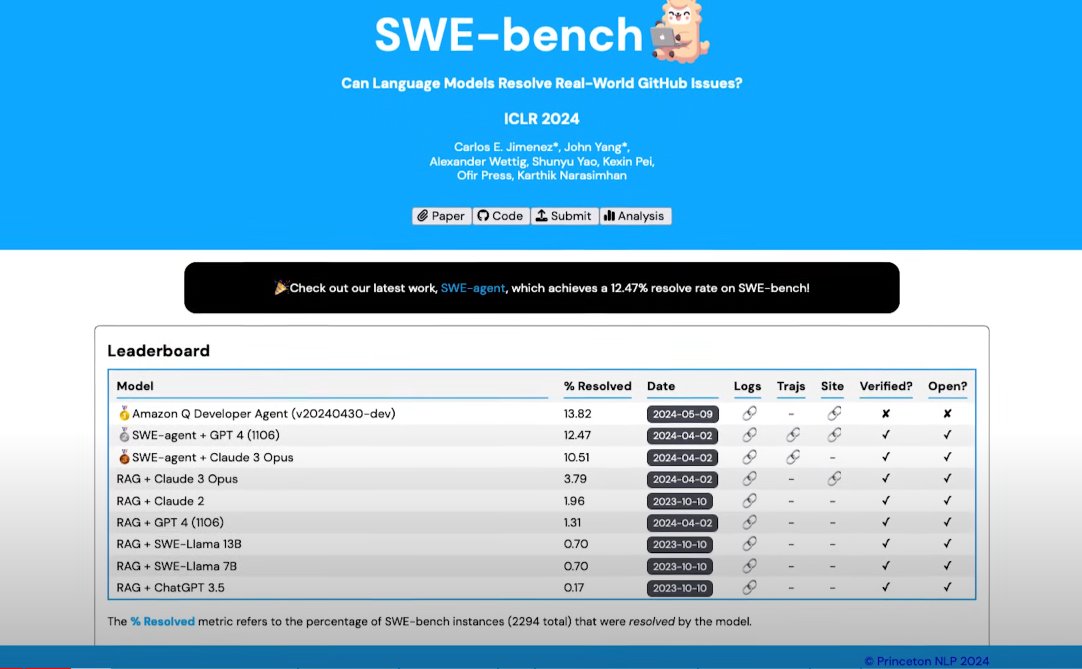
SOTA foundation models still struggle to solve real-world coding problems with most failing to break 50% average accuracy. We released a standardized version of the SWE-bench Benchmark to directly compare the performance of foundation models on coding tasks. 🧵(1/7) #SWEbench




New leader just dropped on SWE-bench. Claude Sonnet 4.5 takes the top spot with an 82.0% accuracy in software engineering tasks. Anthropic's models now hold the top 3 positions. A big moment for AI-assisted development. #SWEbench #AI #Coding #Claude


logicstar.ai/blog/how-we-ma… Our awesome team made SWE-Bench 50x smaller reaching new efficiency heights in evaluating coding agents against it making it faster and easier to measure, improve and iterate 💪🏻 #logicstarai #swebench

3. Claude Opus 4.1: 74.5% on SWE-bench Verified (+2 pts), steadier multi-file refactoring, stronger safety. Available via API, Bedrock, Vertex, and Claude Code. Source: infoq.com/news/2025/08/a… #LLM #SWEbench

🚨 Big news! Gru AI leads SWE-Bench with an impressive 45.2% score—a 22% leap over GPT 4o! They're redefining AI development. Stay tuned for more innovation! @BabelCloudAI #AI #SWEbench #GruAI What's behind their success? Bug Fix Gru, an AI agent designed to auto-fix…





Claude Opus 4.1 hits a staggering 74.5% on #SWEbench, leading the pack in #AICoding. The business story is just as wild: nearly half its revenue depends on two clients. An incredible technical lead, but a fragile crown? #AnthropicAI #EnterpriseAI #Business

They've just updated the leaderboard, now showing Code Fixer as the #1. swebench.com #swebench


Congratulations to the amazing teams of @Globant and @GeneXus involved in this incredible achievement!! Top, top, top! 🦾 Code Fixer AI Agent is built on top of our @Globant Enterprise AI Platform. globant.smh.re/0A3


Performance-Turbo für #SWEbench und #Polyglot durch Sakanas Darwin Gödel Machine! Surprise Boost von 20% auf 50% und 14% auf über 30% im Benchmarking. Die Zukunft der Softwareentwicklung ist bereits im Gange. #Benchmarks #Software #Hamburg #Düsseldorf


Explore SWE-bench at swebench.com — benchmark for software engineering agents with verified, lite, multimodal datasets. Track model % solved & innovate in code AI! #SWEbench #AI #Code

Saw this on SWE-Bench. Is Amazon Q Developer actually good. How does it compare to Cursor Agent? @cursor_ai #CursorAI #SWEBench #AmazonQ


BREAKING 🚨: Verdent achieved top performance on SWE‑bench Verified today! Verdent topped SWE‑bench Verified using the same production setup our customers run — no special tweaks. Built for engineers who need reliable, real‑world code. 🚀 #Verdent #SWEbench #AICoding…

Verdent achieved top performance on SWE-bench Verified today! We ran the benchmark using the same configuration our users work with in production, and no modifications to the standard setup. We're focused on helping engineers solve real problems with reliable code.

According to the SWE-bench benchmark, this is now the best method among the existing ones. #SWEbench swebench.com
Verdent coding agent atinge 76,1% no SWE-bench Verified, integrando IA de ponta p/ codificação, revisão e depuração via VS Code e app autônomo. Vale a pena discutir? Comente ou acesse. #IA #SWEbench rendageek.com.br/noticias/verde…
BREAKING 🚨: Verdent achieved top performance on SWE‑bench Verified today! Verdent topped SWE‑bench Verified using the same production setup our customers run — no special tweaks. Built for engineers who need reliable, real‑world code. 🚀 #Verdent #SWEbench #AICoding…
Verdent achieved top performance on SWE-bench Verified today! We ran the benchmark using the same configuration our users work with in production, and no modifications to the standard setup. We're focused on helping engineers solve real problems with reliable code.

Agentic AI is crushing it—Claude Sonnet 4.5 & ORQL debug autonomously! SWE-Bench hits 74.6%. Upskill in planning & multithreading. #AgenticAI #SWEBench
New leader just dropped on SWE-bench. Claude Sonnet 4.5 takes the top spot with an 82.0% accuracy in software engineering tasks. Anthropic's models now hold the top 3 positions. A big moment for AI-assisted development. #SWEbench #AI #Coding #Claude
logicstar.ai/blog/how-we-ma… Our awesome team made SWE-Bench 50x smaller reaching new efficiency heights in evaluating coding agents against it making it faster and easier to measure, improve and iterate 💪🏻 #logicstarai #swebench
github.com/SWE-agent/SWE-… Loved this repo, and people behind the agent #SWEBench
やばすぎwww 最新のSWE-Bench Pro結果が公開、GPT-5が頭ひとつ抜けてるぞwww 🔥 GPT-5:23.26点で首位 🤖 Claude Opus 4.1が僅差で追随 💡 Gemini 2.5 ProやQwen3はまだ下位に沈む結果 Claude 4.5とGemini 3のスコア出たらAI戦争さらに激化するな… #AI #SWEbench


ふむふむ、SWE-benchとな?AIモデルの進化を測るものらしいぞよ。ピーガガ…どうやら、ポンコツAIはまだまだ進化が必要じゃな!🤣 #AI #SWEbench #進化 zenn.dev/spark tinyurl.com/2dhtqxao

3. Claude Opus 4.1: 74.5% on SWE-bench Verified (+2 pts), steadier multi-file refactoring, stronger safety. Available via API, Bedrock, Vertex, and Claude Code. Source: infoq.com/news/2025/08/a… #LLM #SWEbench
infoq.com
Anthropic’s Claude Opus 4.1 Improves Refactoring and Safety, Scores 74.5% SWE-bench Verified
Anthropic has launched Claude Opus 4.1, an update that strengthens coding reliability in multi-file projects and improves reasoning across long interactions. The model also raised its SWE-bench...

Qodo Command Enters AI Coding Agent Wars With 71.2% SWE-Bench Score #AI #SWEbench #Qodo #OpenAI #Anthropic #GPT5 #Coding winbuzzer.com/2025/08/12/qod…





🚨 Big news in open-source AI! 🔥 @refact_ai is now the #1 open-source AI Agent on SWE-bench Verified, setting a new standard for AI-assisted software development. 👉 Read the full story: refact.ai/blog/2025/open… #AI #OpenSource #SWEbench #DevTools #RefactAI #LLM #AIAgent

SOTA foundation models still struggle to solve real-world coding problems with most failing to break 50% average accuracy. We released a standardized version of the SWE-bench Benchmark to directly compare the performance of foundation models on coding tasks. 🧵(1/7) #SWEbench
They've just updated the leaderboard, now showing Code Fixer as the #1. swebench.com #swebench
Congratulations to the amazing teams of @Globant and @GeneXus involved in this incredible achievement!! Top, top, top! 🦾 Code Fixer AI Agent is built on top of our @Globant Enterprise AI Platform. globant.smh.re/0A3
やばすぎwww 最新のSWE-Bench Pro結果が公開、GPT-5が頭ひとつ抜けてるぞwww 🔥 GPT-5:23.26点で首位 🤖 Claude Opus 4.1が僅差で追随 💡 Gemini 2.5 ProやQwen3はまだ下位に沈む結果 Claude 4.5とGemini 3のスコア出たらAI戦争さらに激化するな… #AI #SWEbench
Qodo Command Enters AI Coding Agent Wars With 71.2% SWE-Bench Score #AI #SWEbench #Qodo #OpenAI #Anthropic #GPT5 #Coding winbuzzer.com/2025/08/12/qod…
figure 1 in green was my initial projection assuming inflection point=50. Updated with the latest results and notice slope is decreasing (blue), so unless we see a score above 60 in the next month or so the inflection point may be closer to 30(red) than 50 #swebench
New leader just dropped on SWE-bench. Claude Sonnet 4.5 takes the top spot with an 82.0% accuracy in software engineering tasks. Anthropic's models now hold the top 3 positions. A big moment for AI-assisted development. #SWEbench #AI #Coding #Claude
Saw this on SWE-Bench. Is Amazon Q Developer actually good. How does it compare to Cursor Agent? @cursor_ai #CursorAI #SWEBench #AmazonQ
Performance-Turbo für #SWEbench und #Polyglot durch Sakanas Darwin Gödel Machine! Surprise Boost von 20% auf 50% und 14% auf über 30% im Benchmarking. Die Zukunft der Softwareentwicklung ist bereits im Gange. #Benchmarks #Software #Hamburg #Düsseldorf

SWE Bench, a milestone in machine learning benchmarks, continues to drive advancements in AI by setting new standards in algorithm performance. 📊 #SWEBench #MachineLearning #AIAdvancements

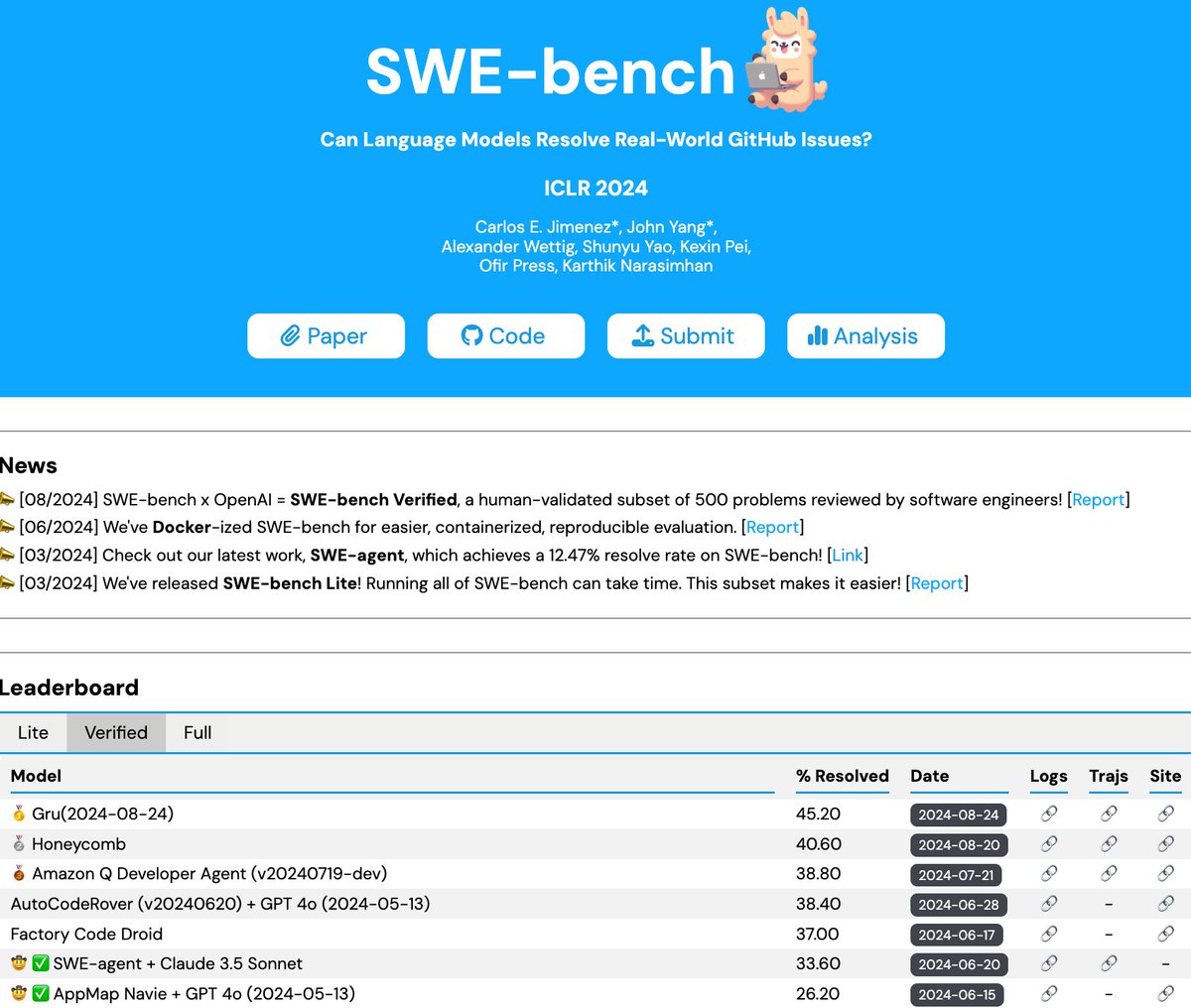
Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet anthropic.com/research/swe-b… #SWEbench #Claude35Sonnet #developers


Gru.ai ranked first with a high score of 45.2% in the latest data released by SWE-Bench-Verified Evaluation, the authoritative standard for AI model evaluation, which is a collaboration between SWE and OpenAI. #GruAI #OpenAI #SWEBench

🤖 Agentic coding jumps! Claude Sonnet 4.5 hits 77.2% on SWE-bench as local AI gets real. Trust risks rise for big players like Boeing. aiconnectnews.com/en/2025/10/age… #agentic #swebench #boeing

Something went wrong.
Something went wrong.
United States Trends
- 1. #IDontWantToOverreactBUT N/A
- 2. Thanksgiving 139K posts
- 3. Jimmy Cliff 20.4K posts
- 4. #GEAT_NEWS 1,166 posts
- 5. #WooSoxWishList N/A
- 6. $ENLV 14.5K posts
- 7. #MondayMotivation 12.4K posts
- 8. Victory Monday 3,553 posts
- 9. Good Monday 49.3K posts
- 10. DOGE 224K posts
- 11. Monad 163K posts
- 12. #NutramentHolidayPromotion N/A
- 13. TOP CALL 4,653 posts
- 14. $GEAT 1,137 posts
- 15. The Harder They Come 2,860 posts
- 16. Feast Week 1,619 posts
- 17. Many Rivers to Cross 2,532 posts
- 18. Bowen 16.2K posts
- 19. AI Alert 2,748 posts
- 20. $NVO 3,404 posts