#benchmarks search results

✨ Taking the stage, @Jared_Spataro here to share his thoughts and insights about “A New Frontier: Building the Future Firm with #AI” #BenchMarks 📈📉📊 #M365Con Day Three Keynote




One for you @martgathercole a few of the benchmarks in my area #benchmarking #ordnancesurvey #benchmarks

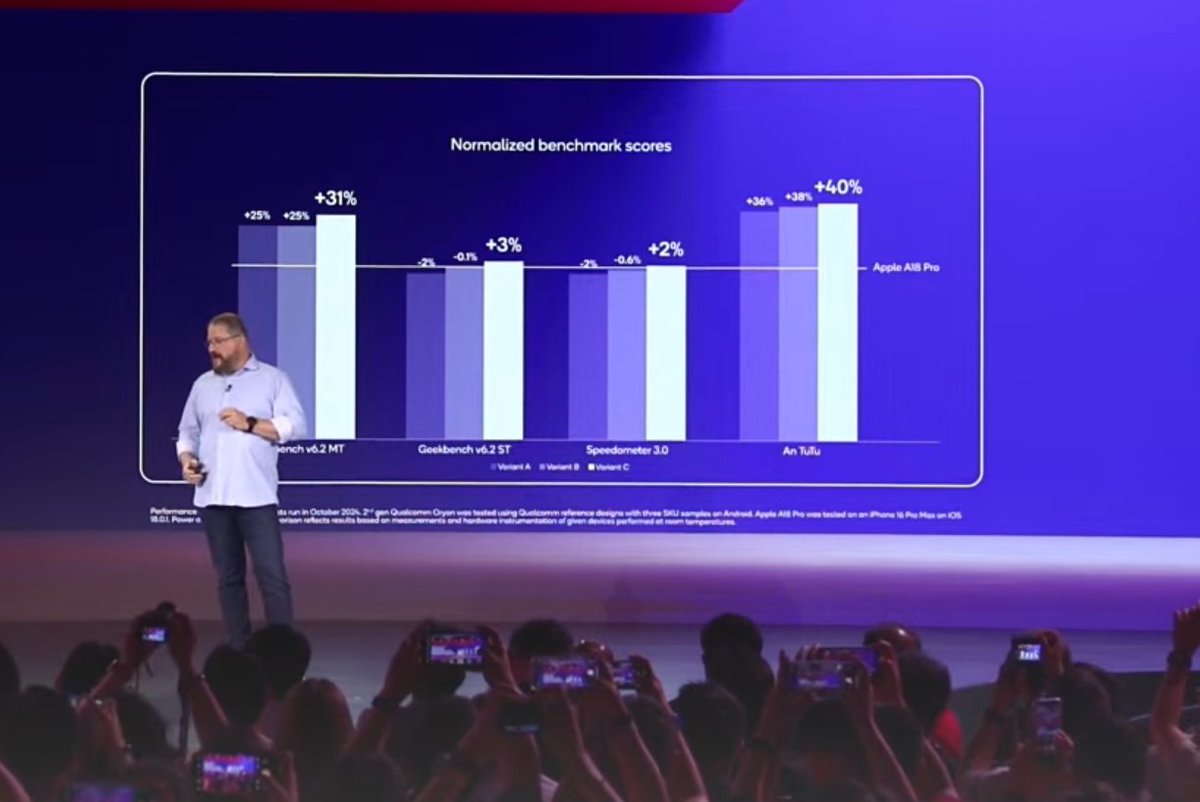
Pixel 10 Pro XL pulls a 95% stability on Wild Life Extreme Stress Test 🔥 Best loop: 3252 | Lowest loop: 3094 Google finally nailed thermal performance – no wild throttling here. 💪📱 #Pixel10Pro #Benchmarks





The district ELA team is at Pine testing students @PalmyraSchools #benchmarks #meetingstudentswheretheyareat #ThisIsPalmyra #ThisIsPine










Open Deep Search (ODS) isn’t theory. It’s already outperforming closed labs: - FRAMES: 75.3% - SimpleQA: 88.3% That’s Sentient’s power: research that’s open, benchmarked, and winning. @SentientAGI @sentient_chat #SentientAGI #Benchmarks


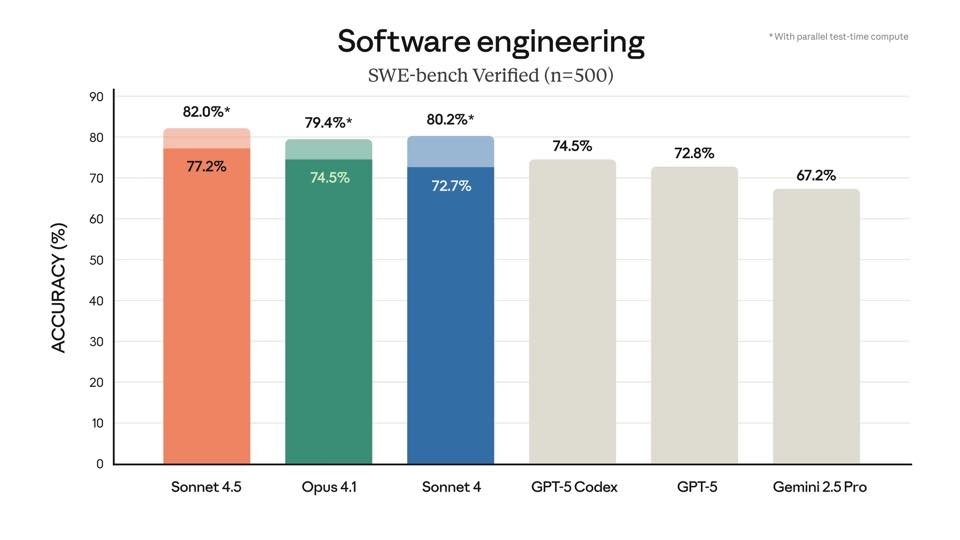
Claude Sonnet 4.5 just topped SWE-bench Verified (n=500) with 82% accuracy — outperforming Opus 4.1, Sonnet 4, GPT-5 Codex, GPT-5, and Gemini 2.5 Pro. Software engineering benchmark results are clear: Sonnet 4.5 leads. #AI #SoftwareEngineering #Benchmarks #Craftvideo



I camped overnight outside of Microcenter and got my hands on an #RTX5080 #ffxiv #benchmarks #ff14
I camped overnight outside of Microcenter to get an RTX 5080! Here's how it runs on #FFXIV youtu.be/D_CgrIaw1nU?si…


#OpenAI says AI hallucinations aren’t bugs, they’re built into how chatbots think. Because models predict words by probability, mistakes pile up the longer they talk. And since users and #benchmarks reward confidence over accuracy, #AIs are trained to sound sure, even when…


The fastest open-source LLM #inference stack just landed. Check out our latest #benchmarks that leave vLLM and Fireworks in the dust. 🏎️💨 Our blog has all the juicy details—but here's the 30-sec version: ⚡ Up to 4× lower P50/P95 latency on the same #H100 & L40S GPUs 📈…


GPT-5 vs Grok 4 - SkateBench → GPT-5: 98.6% accuracy | $0.07 cost → Grok 4: 79% accuracy | $4.86 cost GPT-5 is: → 14× cheaper → More accurate → Much faster This is precision at scale. That is burn rate with lag. #GPT5 #LLM #Benchmarks


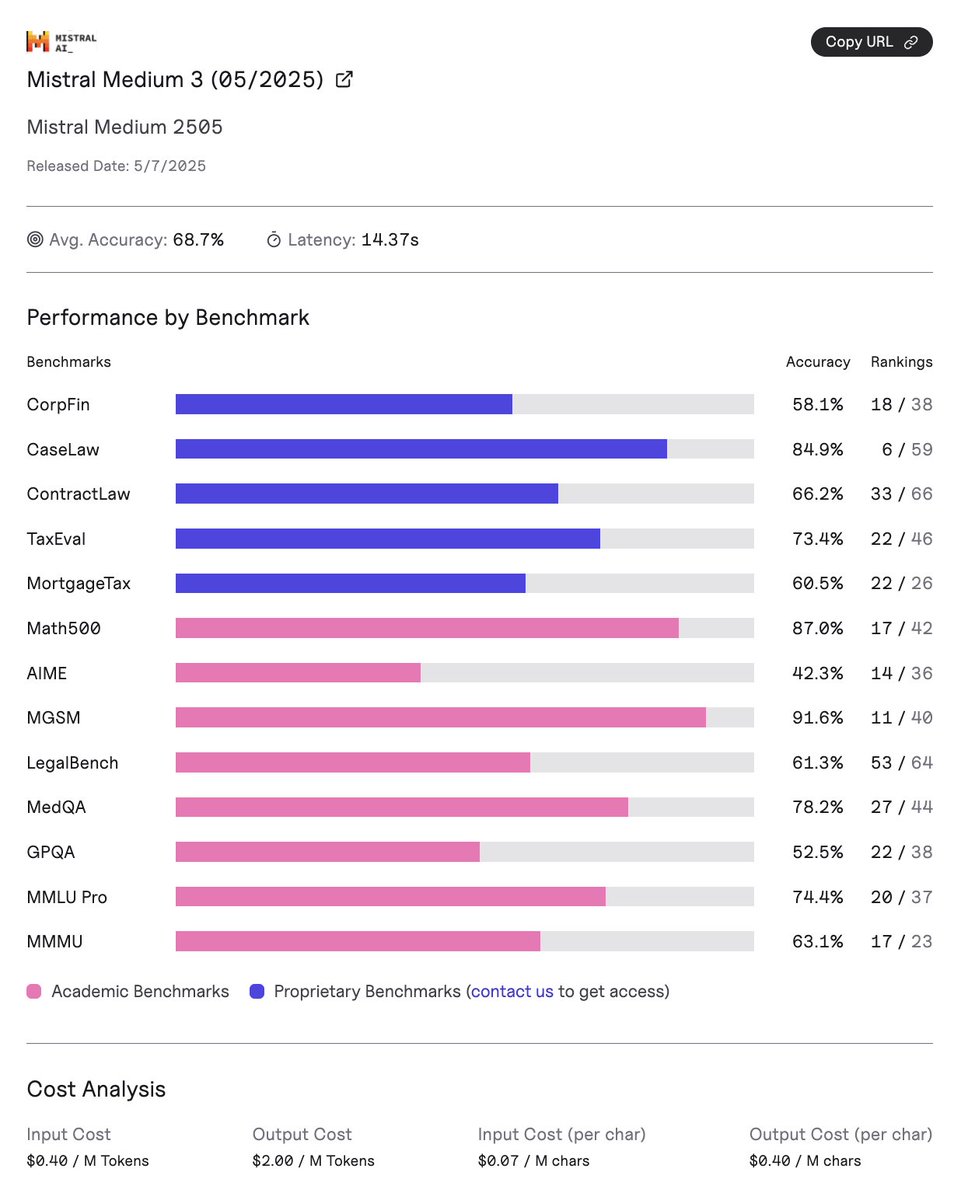
We just released our evaluation of @MistralAI Medium 3 across all of our benchmarks! 🧵(1/6) #AI #LLM #Benchmarks
You can now filter the LLM benchmark list by size. Here's the top XS models (< 2B parameters) furukama.com/llm-bob/?size=… #benchmarks #artificialintelligence


#safety #Reliability #Benchmarks #aiprl_lir #aiprl_llm_intelligence_report #llm #hostingproviders #llmcompanies #researchhighlights #report #monthly #ai #analysis #aiparivartanresearchlab #january2025

Even if #Tesla only achieves the first 2 #benchmarks, #Musk himself will have earned $26 billion – more than the #total #lifetime #pay of the #Meta’s #MarkZuckerberg, #Apple’s #TimCook & #Nvidia’s #JensenHuang combined, nypost.com/2025/11/06/bus…

#aiprl_lir #LLMs #Benchmarks #hostingproviders #llmcompanies #researchhighlights #report #aiparivartanresearchlab #january2025 #analysis #ai #artificial_intelligence

WE ARE NOW LIVE! #RTX5060Ti #gaming #benchmarks #KingGslickTV #tech #pcparts #GPU #RTX #RTXOn #raytracing #DLSS4 youtube.com/watch?v=v6H8be…

youtube.com
YouTube
👀🫡✨👑 HELL IS US: First Look with RTX 5060 Ti Ray Tracing! | Is...

Honoring Indigenous cultures this #NativeAmericanHeritageMonth 🌿 At #Destination2025, we celebrated the Eastern Band of Cherokee Indians through learning, gratitude, and tradition. #Benchmarks

Oppo Reno15 runs Geekbench: 16GB RAM, Android 16, and Dimensity 8450 revealed 📱🔥🚩💻 #Oppo #Android #benchmarks

PrismBench: Dynamic and Flexible Benchmarking of LLMs Code Generation with Monte Carlo Tree Search openreview.net/forum?id=O0bsC… #benchmarking #benchmarks #coding
Over 12,000 children in North Carolina alone are waiting to be adopted. This #NationalAdoptionMonth, let’s shine a light on their resilience and renew our commitment to helping every child find a forever home. #ForeverFamilies #Benchmarks


@abaxx_exchange provides a 24mo forward futures pricing curve on the only three #LNG #benchmarks available globally - Abaxx.exchange/marketdata




















































✨ Taking the stage, @Jared_Spataro here to share his thoughts and insights about “A New Frontier: Building the Future Firm with #AI” #BenchMarks 📈📉📊 #M365Con Day Three Keynote

#DiabloIV #Benchmarks - 38 GPUs tested✅(yesterday) - 14 CPUs tested✅(today) Enjoy! computerbase.de/2023-06/diablo…




#benchmarks Places of worship across the island of Ireland bear a tangible link to the legacy of the Ordnance Survey which mapped Ireland nearly 200 years ago. The OS was the completion of the world’s first large scale mapping of an entire country.






We just released our evaluation of @MistralAI Medium 3 across all of our benchmarks! 🧵(1/6) #AI #LLM #Benchmarks
Do you know how Google PaLM2 model powering Bard compares to other LLMs? 🤔 Tomorrow at GitHub SF I will compare publicly available benchmarks for PaLM2, GPT-4, GPT-3.5 and Llama2 representing open source! RSVP now! Last seats 👉🏻 meetup.com/graphql-sf/eve… #ai #benchmarks ✨🚀


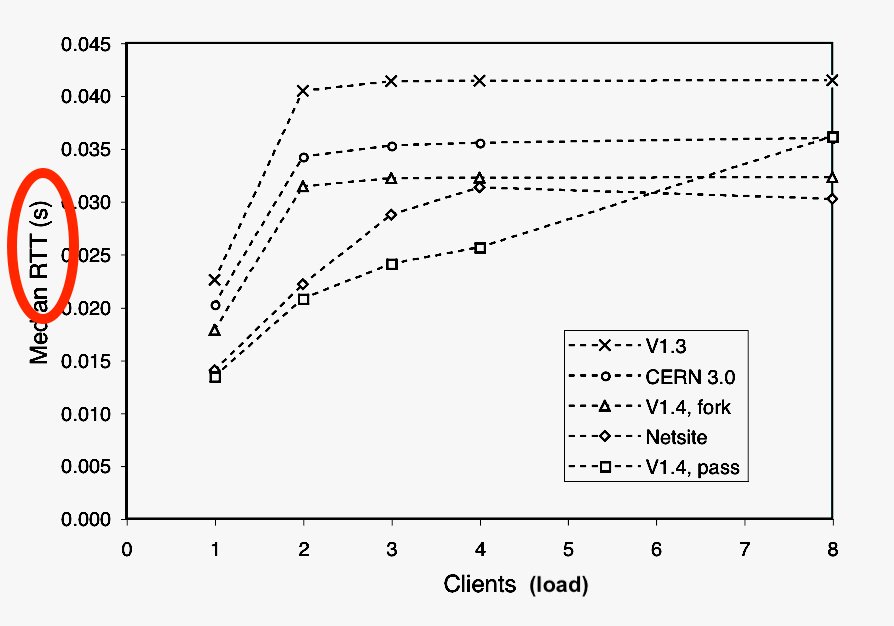
Gaphorism 1.14: Not even wrong !!! perfdynamics.com/Manifesto/gcap… #latency #performance #benchmarks
Claude Sonnet 4.5 just topped SWE-bench Verified (n=500) with 82% accuracy — outperforming Opus 4.1, Sonnet 4, GPT-5 Codex, GPT-5, and Gemini 2.5 Pro. Software engineering benchmark results are clear: Sonnet 4.5 leads. #AI #SoftwareEngineering #Benchmarks #Craftvideo
#OpenAI says AI hallucinations aren’t bugs, they’re built into how chatbots think. Because models predict words by probability, mistakes pile up the longer they talk. And since users and #benchmarks reward confidence over accuracy, #AIs are trained to sound sure, even when…
The fastest open-source LLM #inference stack just landed. Check out our latest #benchmarks that leave vLLM and Fireworks in the dust. 🏎️💨 Our blog has all the juicy details—but here's the 30-sec version: ⚡ Up to 4× lower P50/P95 latency on the same #H100 & L40S GPUs 📈…
GPT-5 vs Grok 4 - SkateBench → GPT-5: 98.6% accuracy | $0.07 cost → Grok 4: 79% accuracy | $4.86 cost GPT-5 is: → 14× cheaper → More accurate → Much faster This is precision at scale. That is burn rate with lag. #GPT5 #LLM #Benchmarks

📢 Excited to share that COBIAS has been accepted at #WebSci25! 🎉 Our work aims to quantify the contextual #quality of LLM-bias #benchmarks. w/ @priyanshul1202 @jain_hemang112 @VictorKnox99 @i_amanchadha @manasgaur90 @DeySanorita 📜 arxiv.org/abs/2402.14889 Findings 🧵⬇️


The TikTok ban grace period expires this week. A new study shows Meta ad prices soared during the previous brief TikTok outage – hurting small businesses the most. go.tigerpistol.com/3R2xihZ #FranchiseMarketing #TikTok #Benchmarks #LocalAdvertising #DigitalMarketing


It's important to use proper #benchmarks and #evaluation methods to validate your #models, especially for time series


Day 1 of The @ITPressTour w/ @MLCommons and @Hammerspace_Inc - a pretty good day in perspective dedicated to Performance, #Benchmarks and #DataGovernance #MultiCloud #FileStorage #ParallelFS #pNFS #NAS #AI #HPC #FastIO #MLPerf #DataManagement #ITPT

What a good Day 1 for The @ITPressTour w/ @MLCommons and @Hammerspace_Inc around #FastIO, #Benchmarks and #DataGovernance #MultiCloud #FileStorage #ParallelFS #pNFS #NAS #AI #HPC #FastIO #MLPerf #DataManagement #ITPT

Something went wrong.
Something went wrong.
United States Trends
- 1. Texas Tech 9,051 posts
- 2. Obamacare 159K posts
- 3. St. John 4,287 posts
- 4. Gameday 15.6K posts
- 5. #SaturdayVibes 5,431 posts
- 6. Mississippi State 3,571 posts
- 7. Shapen N/A
- 8. #Caturday 5,569 posts
- 9. Sesko 49.1K posts
- 10. Insurance 212K posts
- 11. Sunderland 70K posts
- 12. Parker Kingston N/A
- 13. Trump Stadium 3,348 posts
- 14. Calen Bullock N/A
- 15. Beaver Stadium N/A
- 16. #BYUFOOTBALL N/A
- 17. Ugarte 17.1K posts
- 18. Good Saturday 35.2K posts
- 19. #SUNARS 3,426 posts
- 20. #sjubb N/A