#textencoder Suchergebnisse

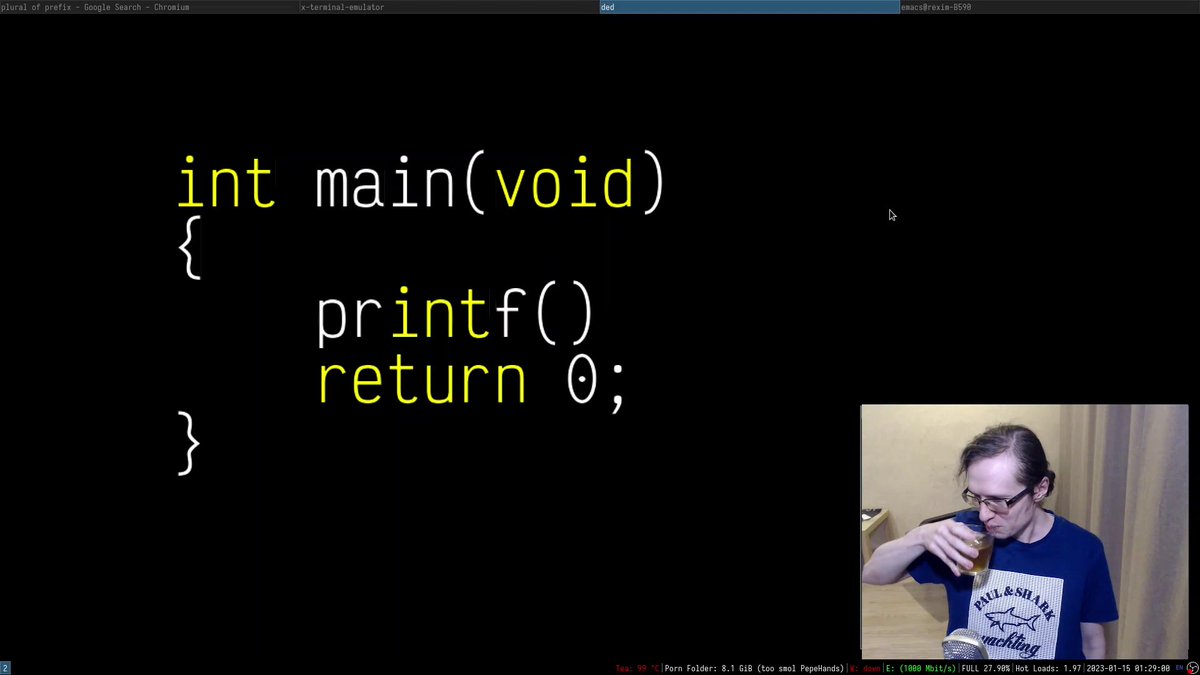

if i'm understanding this correctly, you can use a pure text encoder model to find text that lets you reconstruct an image from the text encoding. basically, the latent space of a text model is expressive enough to serve as a compilation target for images




Framer just got smarter. Meet TextEditor — the missing piece for SaaS, CMS, and writing tools. Your users can actually write like it’s Notion. ✍️ Grab this for your next client and smash your framer goals!! 👇 framer.com/marketplace/co…

Introducing Codestral Embed, the new state-of-the-art embedding model for code.


The code of Linux shown as 3D ASCII. Codeology uses information from GitHub to visualizes … ift.tt/1TDwBch

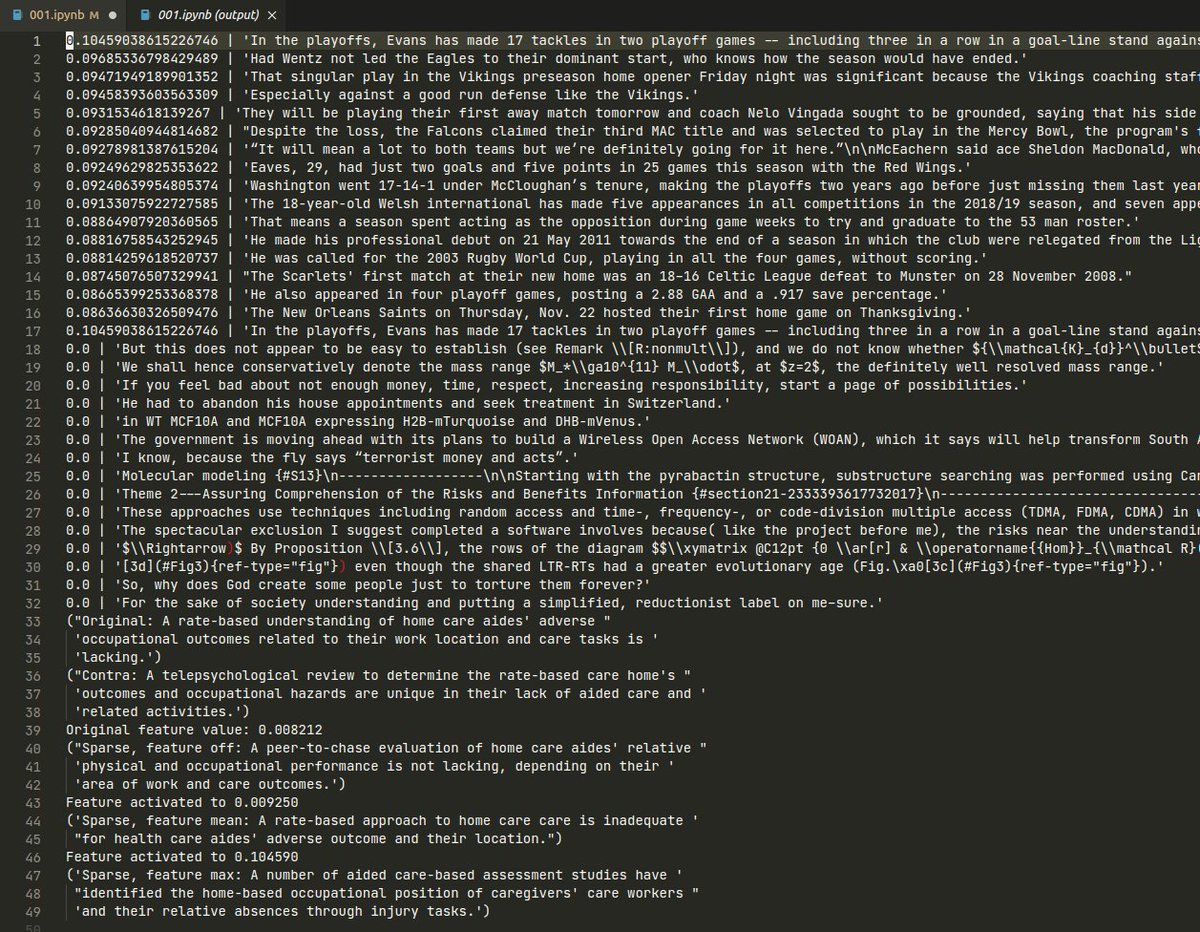
Wow, I just got @AnthropicAI's sparse autoencoder-based feature decomposition technique to work* for text embeddings 🎆 Screenshot below. In order, this output shows: 1. max-activating examples for that feature from the Minipile dataset 2. min-activating examples from the same…

Vector Database by Hand ✍️ Vector databases are revolutionizing how we search and analyze complex data. They have become the backbone of Retrieval Augmented Generation (#RAG). How do vector databases work? [1] Given ↳ A dataset of three sentences, each has 3 words (or tokens)…

Let's learn/revise byte pair encoding (BPE) in less than 10 mins! Let's say our corpus consists of these four words. we have appended </w> to all words which says its end of the word. The number denotes the number of times each word is seen in the corpus 1/N


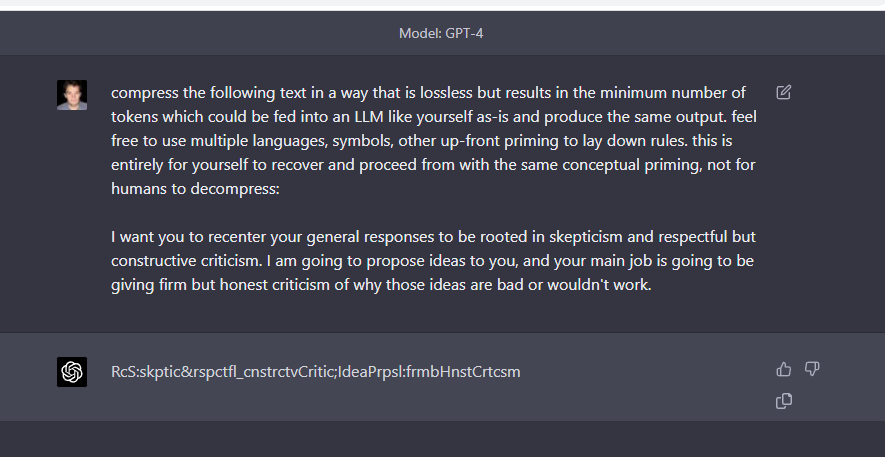
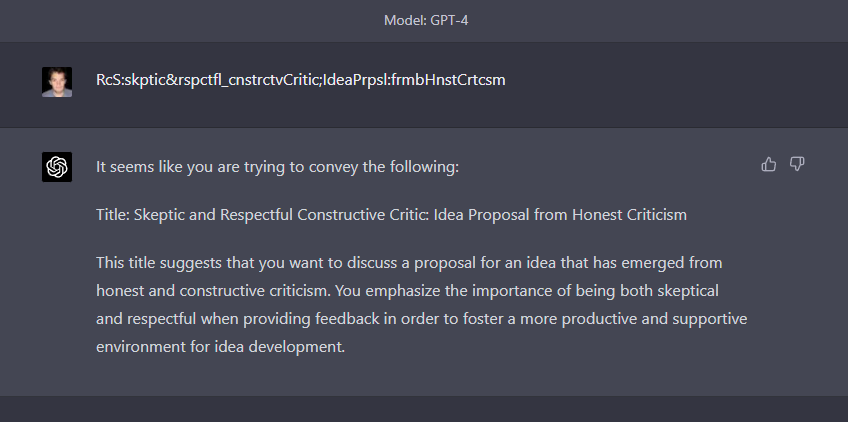
New prompt is good, which emphasizes token reduction not word reduction. what is this shoggoth langauge? it is spooky and weird. Compresed: RcS:skptic&rspctfl_cnstrctvCritic;IdeaPrpsl:frmbHnstCrtcsm Compressor: compress the following text in a way that fits in a tweet (ideally)…

You can easily get state of the art text embeddings from open source models, here's how along with some examples



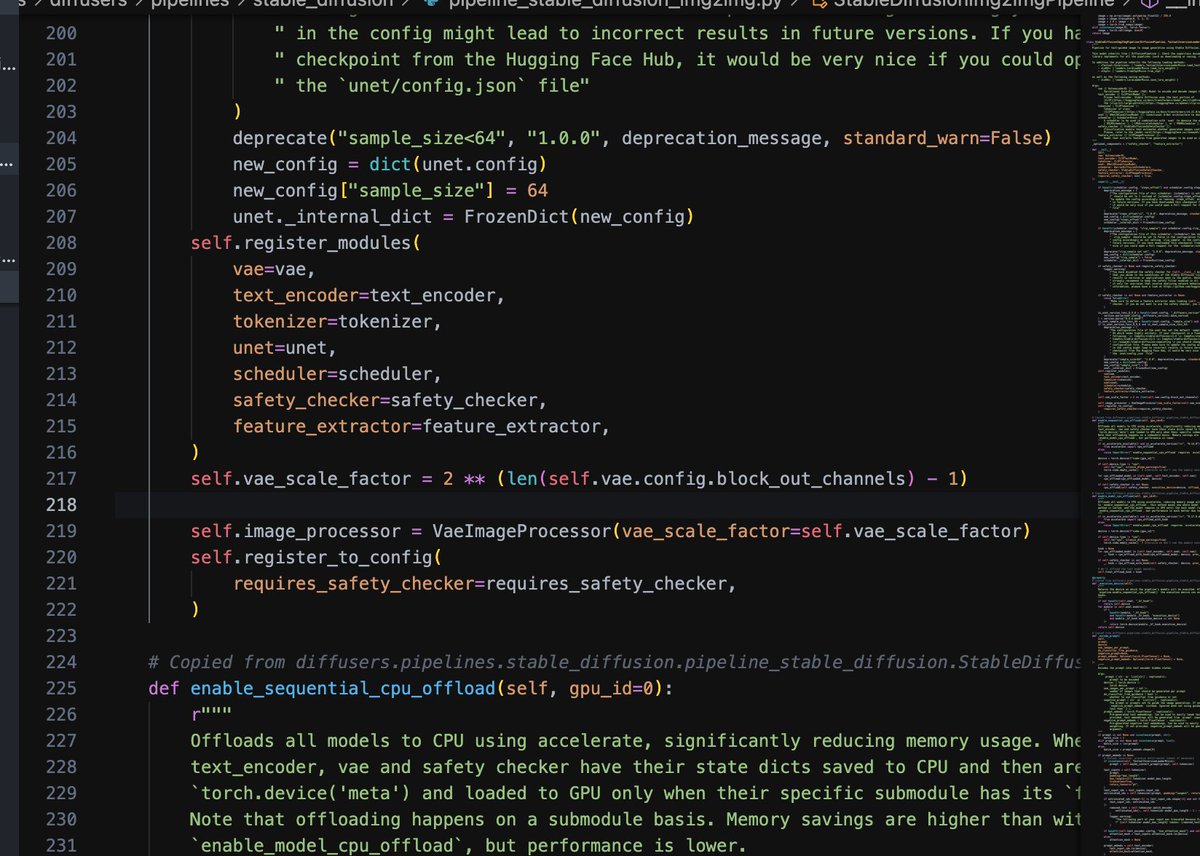
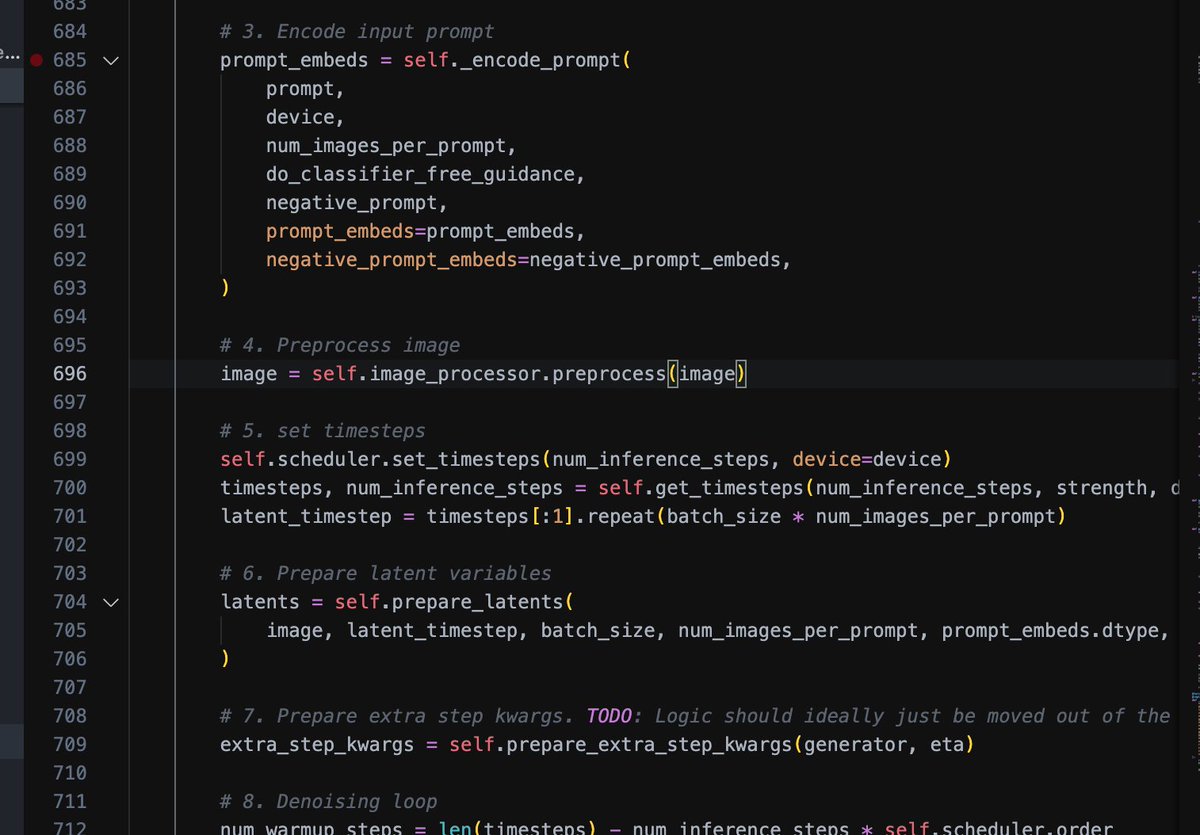
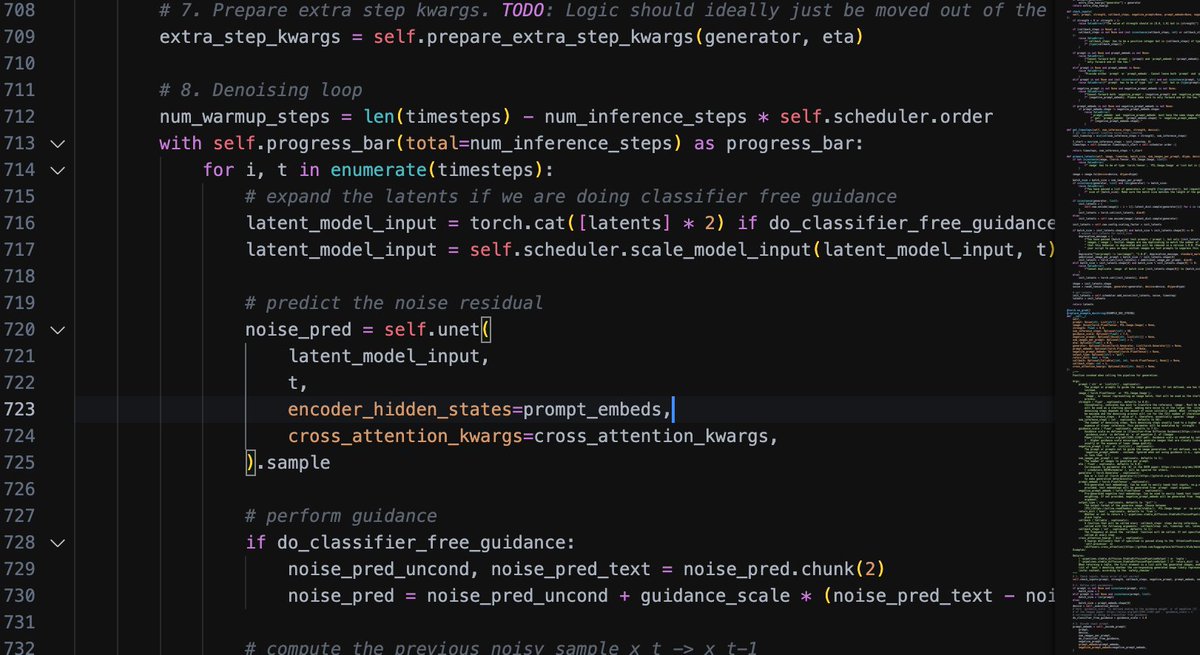
硬核科普:#stablediffusion 的img2img生成图片的时候种子图片只是先传递给了VAE用于提取“像素”信息,每次循环采样的时候并没有参考种子图片的语义信息,所有的语义信息依然是来自 #TextEncoder 处理过的 prompt 信息。所以开源还是很重要的,不要想当然,一定要看一遍源代码再去用。代码源 #diffusers

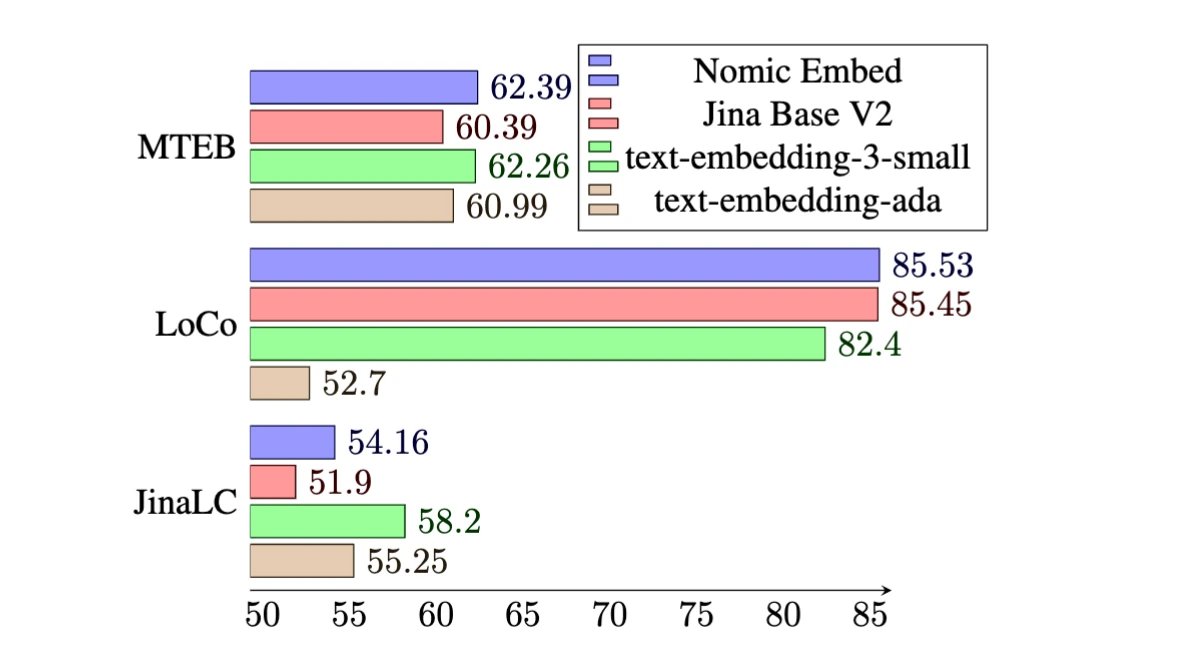
Announcing Nomic Embed 🧨 You can now train your own OpenAI quality text embedding model. - Open source, fully reproducible text embedding model that beats OpenAI and Jina on long context tasks. - 235M text pairs openly released for training 💰 - Apache 2 License

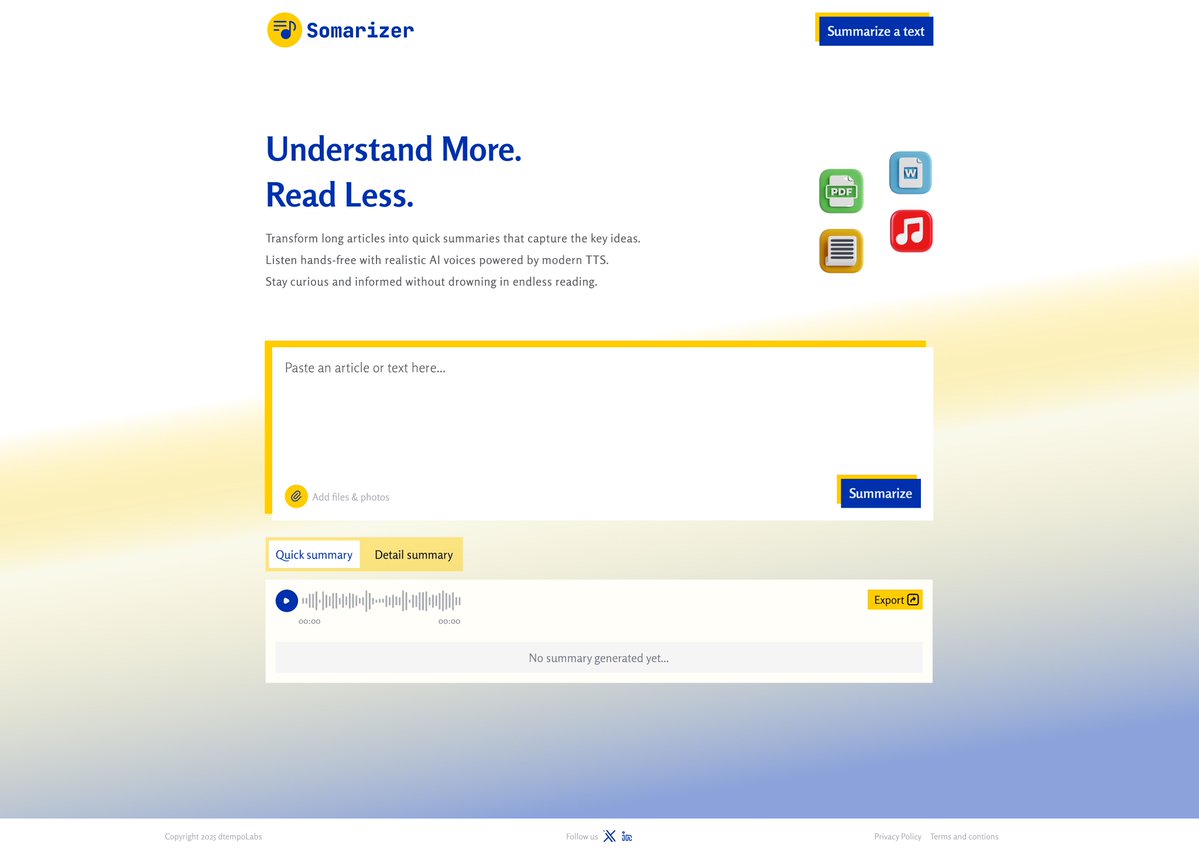
Initial design for one of my vibe coded tool which summarize your texts and generate a voice note for it. This was the first iteration design screen

We’ve developed TransCoder, the first self-supervised neural transcompiler system for migrating code between programming languages. Transcoder can translate code from Python to C++, for example, and it outperforms rule-based translation programs. ai.facebook.com/blog/deep-lear…

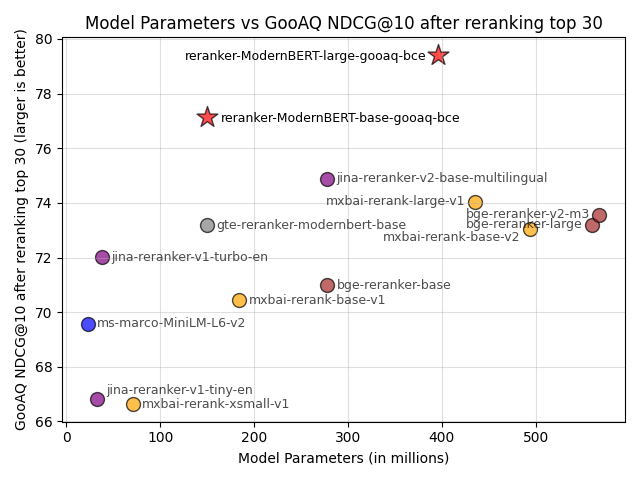
‼️Sentence Transformers v4.0 is out! You can now train and finetune reranker (aka cross-encoder) models with multi-GPU training, bf16 support, loss logging, callbacks & much more. I also prove that finetuning on your domain helps much more than you might think. Details in 🧵

Create sentence embeddings in your browser with transformers.js! My guide walks you through generating embeddings and applying UMAP dimension reduction + more - all in JavaScript, no server needed observablehq.com/@huggingface/s…

Autoregressive language models (LLaMA, Mistral, etc) are fundamentally limited for text embeddings since they don’t encode information bidirectionally. We provide an easy fix: just repeat your input! We are the #1 fully-open-source model on MTEB! arxiv.org/abs/2402.15449 1/6


Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5

Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5
硬核科普:#stablediffusion 的img2img生成图片的时候种子图片只是先传递给了VAE用于提取“像素”信息,每次循环采样的时候并没有参考种子图片的语义信息,所有的语义信息依然是来自 #TextEncoder 处理过的 prompt 信息。所以开源还是很重要的,不要想当然,一定要看一遍源代码再去用。代码源 #diffusers

Şifreli mesajlaşmak ister misiniz? İşte basit ve kullanışlı bir metin şifreleyici Python betiği. #python #metinsifreleyici #textencoder #encoder #decoder #pythonprojects Python | Metin Şifreleyici youtu.be/SRo5IjRS_18 @YouTube aracılığıyla

Le décodage binaire facilité grâce à #TextDecoder et #TextEncoder #html5 #html5rocks #EncodingApi updates.html5rocks.com/2014/08/Easier…

硬核科普:#stablediffusion 的img2img生成图片的时候种子图片只是先传递给了VAE用于提取“像素”信息,每次循环采样的时候并没有参考种子图片的语义信息,所有的语义信息依然是来自 #TextEncoder 处理过的 prompt 信息。所以开源还是很重要的,不要想当然,一定要看一遍源代码再去用。代码源 #diffusers
Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5
Something went wrong.
Something went wrong.
United States Trends
- 1. Giants 77.6K posts
- 2. Eagles 89.6K posts
- 3. Falcons 33K posts
- 4. Skattebo 36.3K posts
- 5. Andy Dalton 7,971 posts
- 6. Myles Garrett 4,795 posts
- 7. Caleb 31K posts
- 8. Dolphins 24.7K posts
- 9. 49ers 26.9K posts
- 10. Drake Maye 9,305 posts
- 11. Bears 58.5K posts
- 12. James Cook 5,204 posts
- 13. Raheem 6,353 posts
- 14. #Browns 3,897 posts
- 15. Dillon Gabriel 3,621 posts
- 16. Ravens 40.6K posts
- 17. Josh Allen 6,710 posts
- 18. Niners 3,638 posts
- 19. Bills 122K posts
- 20. Texans 21.9K posts