#visionlanguagemodel 搜索结果

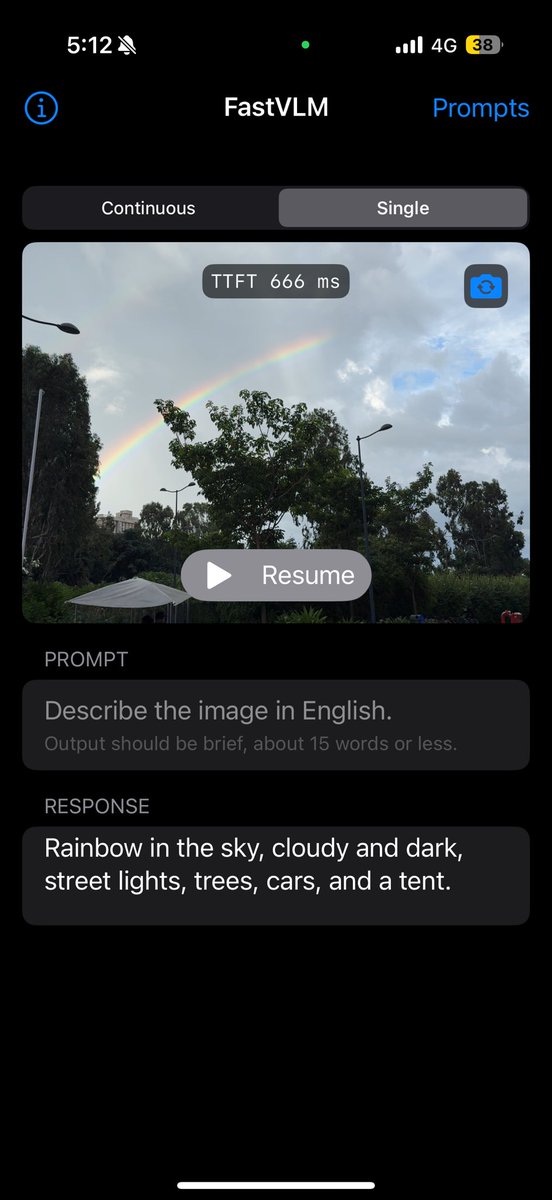
We are excited to be among the very first groups selected by @NVIDIARobotics to test the new @NVIDIA #Thor. We have managed to run a #VisionLanguageModel (Qwen 2.5 VL) for semantic understanding of the environment, along with a monocular depth model (#DepthAnything v2), for safe…


The 32×32 Patch Grid Why does ColPali “see” so well? Each page is divided into patch grids—so it knows exactly where an image ends and text begins. That local + global context means no detail is missed, from small icons to big headers. #colpali #visionlanguagemodel


#UITARS Desktop: The Future of Computer Control through Natural Language 🖥️ 🎯 #ByteDance introduces GUI agent powered by #VisionLanguageModel for intuitive computer control Code: lnkd.in/eNKasq56 Paper: lnkd.in/eN5UPQ6V Models: lnkd.in/eVRAwA-9 #ai 🧵 ↓

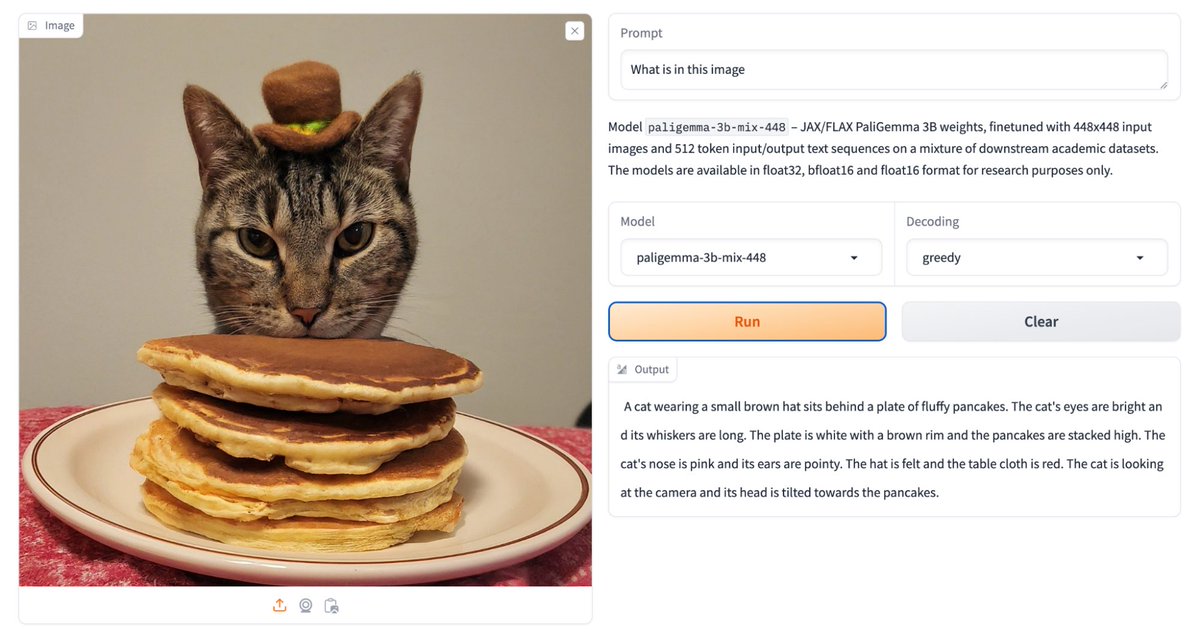
Google 发布了新的视觉语言模型 PaliGemma,它可以接收图像和文本输入,并输出文本。PaliGemma 包含预训练模型、混合模型和微调模型三种类型,具有图像字幕、视觉问答、目标检测、指代分割等多种能力。 #GoogleAI #PaliGemma #VisionLanguageModel huggingface.co/blog/paligemma

2/ 🎯 MiniGPT-4 empowers image description generation, story writing, problem-solving, and more! 💻 Open source availability fuels innovation and collaboration. ✨ The future of vision-language models is here! minigpt-4.github.io #AI #MiniGPT4 #VisionLanguageModel



5/ 🚀 MiniGPT-4 is a game-changer in the field of vision-language models. 🔥 Its impressive performance and advanced multi-modal capabilities are propelling AI to new frontiers. #MiniGPT4 #VisionLanguageModel #AI #innovation nobraintech.com/2023/06/minigp…
nobraintech.com
MiniGPT-4: Empowering Vision and Language with Open Source Brilliance
In the ever-evolving landscape of artificial intelligence (AI) , the latest advancements have taken us into uncharted territory. The release...
Read the full article: hubs.li/Q03F78zL0 #MedicalAI #VisionLanguageModel #RadiologyAI #HealthcareAI #GenerativeAI #MedicalImaging #NLPinHealthcare #JohnSnowLabs

4/ ⏱️ MiniGPT-4 is highly computationally efficient! 💪 With just approximately 5 million aligned image-text pairs, the model's projection layer provides impressive performance. #MiniGPT4 #VisionLanguageModel #Efficiency youtu.be/__tftoxpBAw
Explore the model on AWS Marketplace: hubs.li/Q03mQ5qT0 #MedicalAI #VisionLanguageModel #HealthcareAI #ClinicalDecisionSupport #RadiologyAI #GenerativeAI #JohnSnowLabs #LLM #RAG #MedicalImaging #NLPinHealthcare


従来のAIモデル(VLM)は、画像全体のキャプションは得意でも、指定された「部分」の詳細な説明は苦手でした。 ズームすると文脈が失われ、質の高い学習データも不足していました📉。#VisionLanguageModel #VLM #AI課題

buff.ly/41bdyNy New, open-source AI vision model emerges to take on ChatGPT — but it has issues #AIImpactTour #NousHermes2Vision #VisionLanguageModel

See how domain specialization transforms medical reasoning: hubs.li/Q03nRpCk0 #MedicalAI #VisionLanguageModel #HealthcareAI #ClinicalDecisionSupport #GenerativeAI #RadiologyAI #LLM #NLPinHealthcare


Discover #GPT4RoI, the #VisionLanguageModel that supports multi-region spatial instructions for detailed region-level understanding. #blogger #bloggers #bloggingcommunity #WritingCommunity #blogs #blogposts #LanguageModels #AI #MachineLearning #AIModel socialviews81.blogspot.com/2023/07/gpt4ro…


Seeing #VisionLanguageModel with Qwen 2.5 VL + DepthAnything v2 running live on Jetson Thor is next-level for robotics. Fusing semantic/context with real-time depth makes agile, adaptive bots possible. What benchmarks should we watch for? #AI
We are excited to be among the very first groups selected by @NVIDIARobotics to test the new @NVIDIA #Thor. We have managed to run a #VisionLanguageModel (Qwen 2.5 VL) for semantic understanding of the environment, along with a monocular depth model (#DepthAnything v2), for safe…

Save your time QCing label quality with @Labellerr1 new feature and do it 10X faster. See the demo below- #qualitycontrol #imagelabeling #visionlanguagemodel #visionai

ByteDance Unveils Seed3D 1.0 for AI-Driven 3D Simulation Read More: lnkd.in/gd7CG6HM @BytedanceTalk #VisionLanguageModel #RoboticManipulation #MagicArticulate #DigitalTwinSystems

Seeing #VisionLanguageModel with Qwen 2.5 VL + DepthAnything v2 running live on Jetson Thor is next-level for robotics. Fusing semantic/context with real-time depth makes agile, adaptive bots possible. What benchmarks should we watch for? #AI
We are excited to be among the very first groups selected by @NVIDIARobotics to test the new @NVIDIA #Thor. We have managed to run a #VisionLanguageModel (Qwen 2.5 VL) for semantic understanding of the environment, along with a monocular depth model (#DepthAnything v2), for safe…
We are excited to be among the very first groups selected by @NVIDIARobotics to test the new @NVIDIA #Thor. We have managed to run a #VisionLanguageModel (Qwen 2.5 VL) for semantic understanding of the environment, along with a monocular depth model (#DepthAnything v2), for safe…
Read the full article: hubs.li/Q03F78zL0 #MedicalAI #VisionLanguageModel #RadiologyAI #HealthcareAI #GenerativeAI #MedicalImaging #NLPinHealthcare #JohnSnowLabs

This 6 hours video from Umar Jamil @hkproj, has to be the finest video on VLM from scratch. Next Goal, Fine-tuning on image segmentation or object detection. youtube.com/watch?v=vAmKB7… #LargeLanguageModel #VisionLanguageModel

youtube.com
YouTube
Coding a Multimodal (Vision) Language Model from scratch in PyTorch...

Want to run powerful multimodal AI on your own computer? Try Qwen2.5-VL 7B! Check out our step-by-step guide👇 #Qwen #VisionLanguageModel #OpenSource #AI #Labellerr labellerr.com/blog/run-qwen2…

1/ ⚙️ Efficient training with only a single linear projection layer. 🌐 Promising results from finetuning on high-quality, well-aligned datasets. 📈 Comparable performance to the impressive GPT-4 model. #MiniGPT4 #VisionLanguageModel #MachineLearning
Read the full article: hubs.li/Q03F78zL0 #MedicalAI #VisionLanguageModel #RadiologyAI #HealthcareAI #GenerativeAI #MedicalImaging #NLPinHealthcare #JohnSnowLabs
Discover #GPT4RoI, the #VisionLanguageModel that supports multi-region spatial instructions for detailed region-level understanding. #blogger #bloggers #bloggingcommunity #WritingCommunity #blogs #blogposts #LanguageModels #AI #MachineLearning #AIModel socialviews81.blogspot.com/2023/07/gpt4ro…
Explore the model on AWS Marketplace: hubs.li/Q03mQ5qT0 #MedicalAI #VisionLanguageModel #HealthcareAI #ClinicalDecisionSupport #RadiologyAI #GenerativeAI #JohnSnowLabs #LLM #RAG #MedicalImaging #NLPinHealthcare

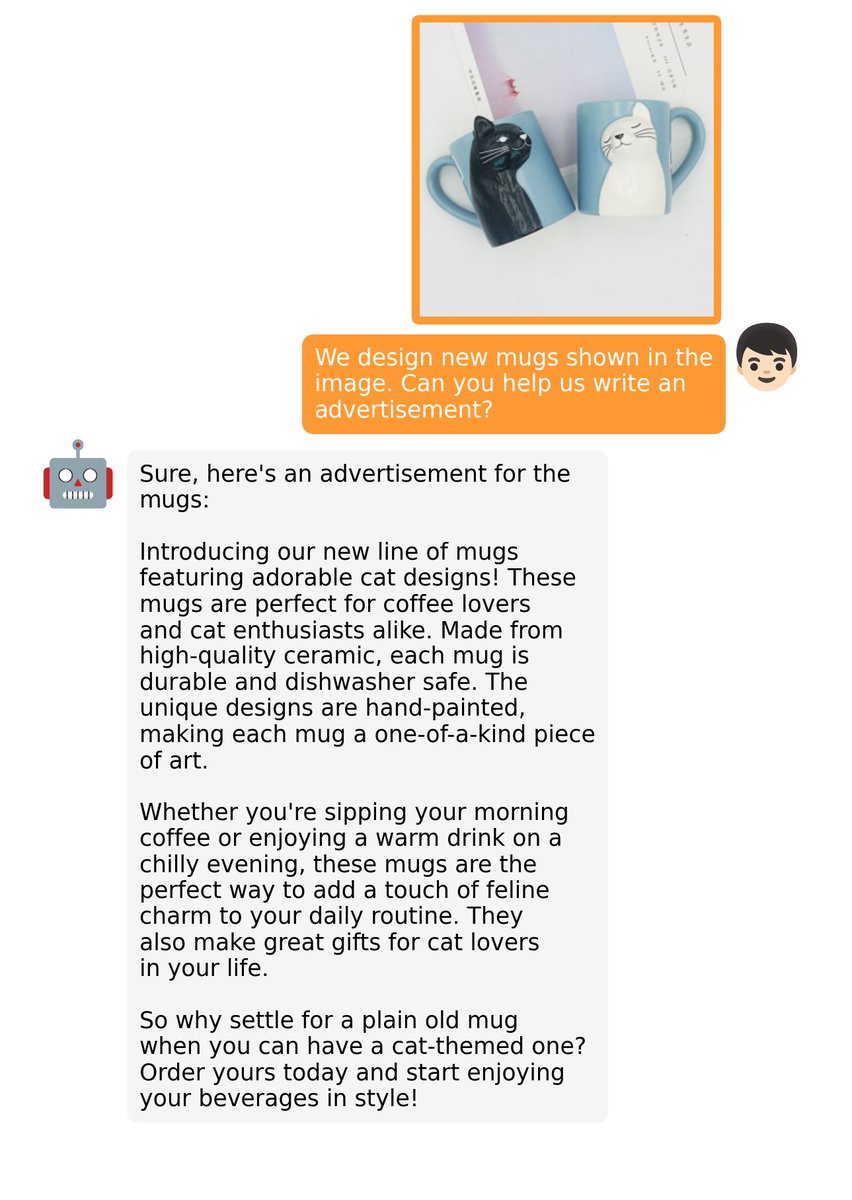
Had a fantastic time at the event where @ritwik_raha delivered an insightful session on PaliGemma! It was very interactive and informative. #Paligeema #google #visionlanguagemodel #AI

2/ 🎯 MiniGPT-4 empowers image description generation, story writing, problem-solving, and more! 💻 Open source availability fuels innovation and collaboration. ✨ The future of vision-language models is here! minigpt-4.github.io #AI #MiniGPT4 #VisionLanguageModel
The 32×32 Patch Grid Why does ColPali “see” so well? Each page is divided into patch grids—so it knows exactly where an image ends and text begins. That local + global context means no detail is missed, from small icons to big headers. #colpali #visionlanguagemodel
Google 发布了新的视觉语言模型 PaliGemma,它可以接收图像和文本输入,并输出文本。PaliGemma 包含预训练模型、混合模型和微调模型三种类型,具有图像字幕、视觉问答、目标检测、指代分割等多种能力。 #GoogleAI #PaliGemma #VisionLanguageModel huggingface.co/blog/paligemma
ByteDance Unveils Seed3D 1.0 for AI-Driven 3D Simulation Read More: lnkd.in/gd7CG6HM @BytedanceTalk #VisionLanguageModel #RoboticManipulation #MagicArticulate #DigitalTwinSystems

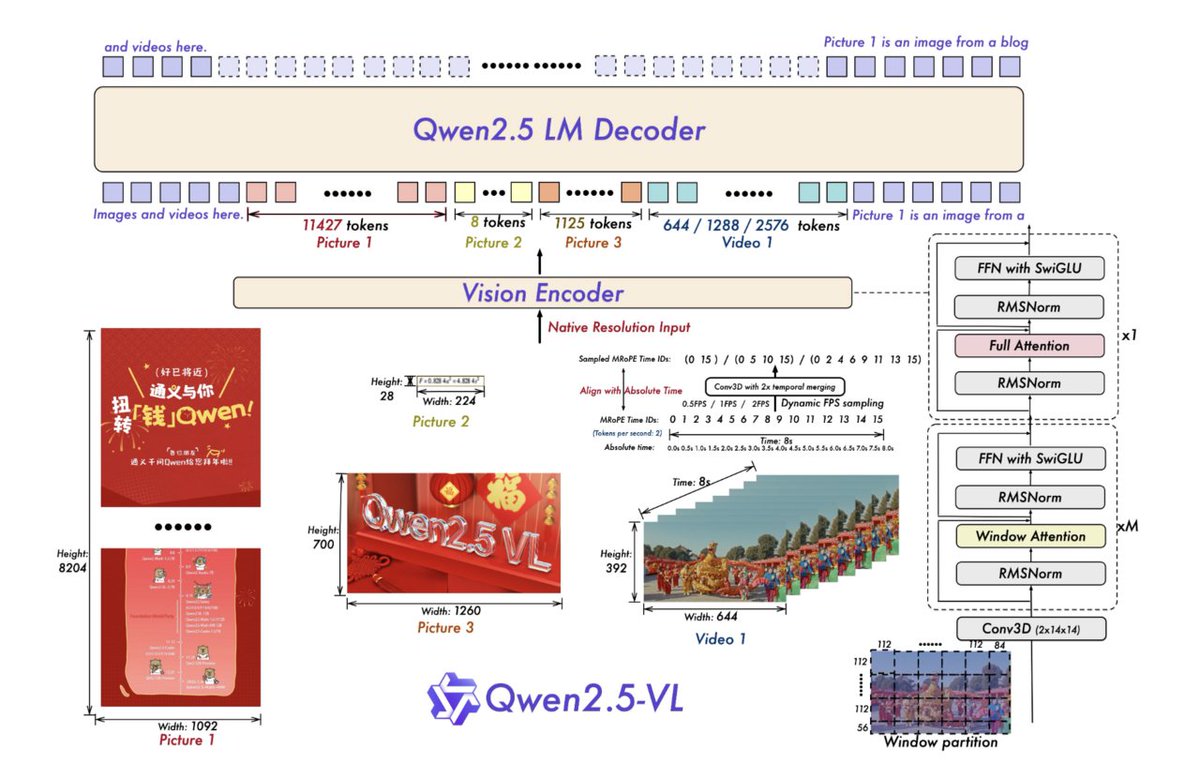
Alibaba's QWEN 2.5 VL: A Vision Language Model That Can Control Your Computer #alibaba #qwen #visionlanguagemodel #AI #viral #viralvideos #technology #engineering #trending #tech #engineer #reelsvideo contentbuffer.com/issues/detail/…


Qwen AI Releases Qwen2.5-VL: A Powerful Vision-Language Model for Seamless Computer Interaction #QwenAI #VisionLanguageModel #AIInnovation #TechForBusiness #MachineLearning itinai.com/qwen-ai-releas…
See how domain specialization transforms medical reasoning: hubs.li/Q03nRpCk0 #MedicalAI #VisionLanguageModel #HealthcareAI #ClinicalDecisionSupport #GenerativeAI #RadiologyAI #LLM #NLPinHealthcare
buff.ly/41bdyNy New, open-source AI vision model emerges to take on ChatGPT — but it has issues #AIImpactTour #NousHermes2Vision #VisionLanguageModel
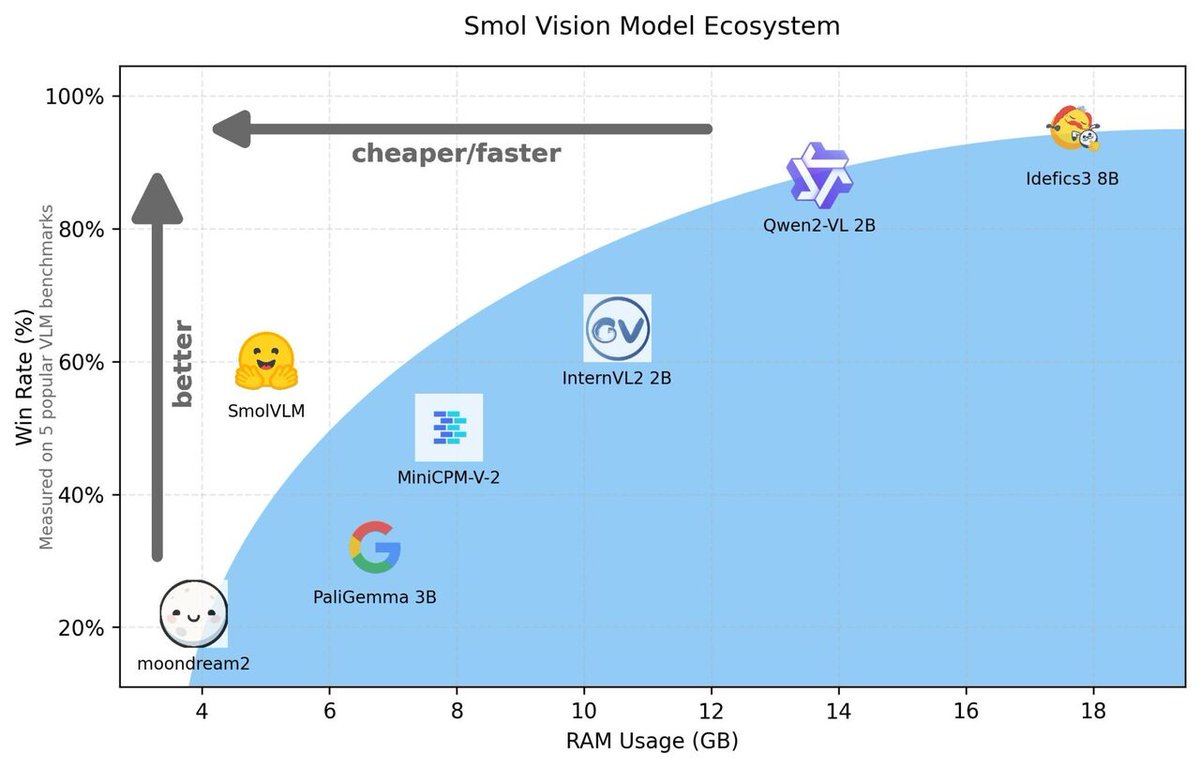
Hugging Face Releases SmolVLM: A 2B Parameter Vision-Language Model for On-Device Inference itinai.com/hugging-face-r… #SmolVLM #VisionLanguageModel #AIAccessibility #MachineLearning #HuggingFace #ai #news #llm #ml #research #ainews #innovation #artificialintelligence #machinele…

SpatialRGPT.com available for sale #SpatialRGPT is an advanced region-level #VisionLanguageModel (#VLM) designed to comprehend both two-dimensional and three-dimensional spatial configurations. It has the capability to analyze any form of region proposal, such as…

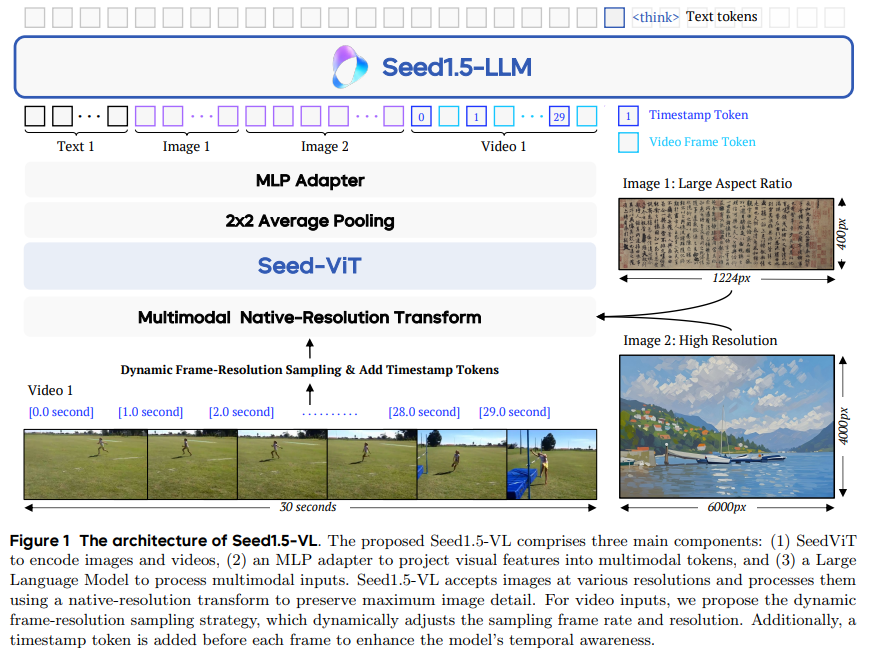
ByteDance Launches Seed1.5-VL: Advanced Vision-Language Model for Multimodal Understanding #ByteDance #Seed15VL #VisionLanguageModel #AIInnovation #MultimodalUnderstanding itinai.com/bytedance-laun…
Clinical notes, X-rays, charts—our new VLM interprets them all. See the model in AWS Marketplace: 🔗 hubs.li/Q03sfVDZ0 #VisionLanguageModel #RadiologyAI #ClinicalAI #MedicalImaging #GenerativeAI

Something went wrong.
Something went wrong.
United States Trends
- 1. Walt Weiss 2,071 posts
- 2. Braves 10.6K posts
- 3. Harvey Weinstein 5,618 posts
- 4. Snit N/A
- 5. Diane Ladd 5,271 posts
- 6. Cardinals 13.5K posts
- 7. #warmertogether N/A
- 8. Ben Shapiro 34.5K posts
- 9. $PLTR 20.1K posts
- 10. Schwab 4,582 posts
- 11. Teen Vogue 2,371 posts
- 12. Hamburger Helper 2,304 posts
- 13. Monday Night Football 5,819 posts
- 14. #OTGala7 151K posts
- 15. Gold's Gym 58.2K posts
- 16. Laura Dern 2,708 posts
- 17. Jaidyn N/A
- 18. McBride 3,756 posts
- 19. #FINEST2025 N/A
- 20. Blueface 5,567 posts