#webcrawler 検索結果

We've created an alpha version of LLM based web crawler so you can ask it to extract information for a target audience in mind. 💻💡 #LLMWebCrawler #webcrawler #search #searchengine #scraper #AIWebCrawler

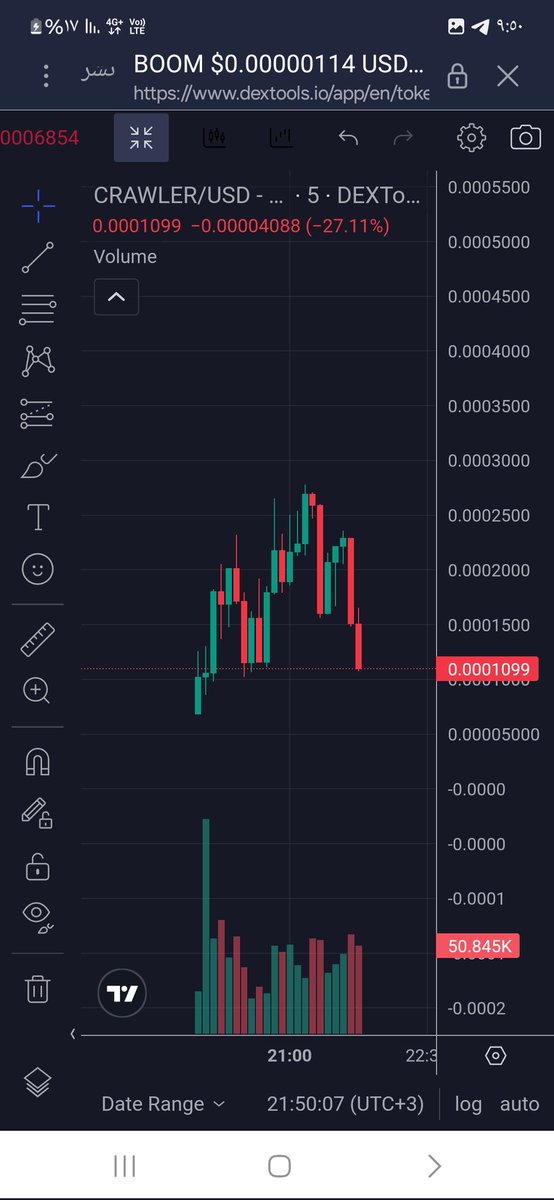
#WEBCRAWLER 100%🔥🔥1X💎💎اول دبل مرتب ✍️تاجر😎الmem✍️

Was ist denn da seit ein paar Tagen für ein #Crawler auf meiner Webseite unterwegs? So viele Connections vom Webserver sehe ich nicht immer. Mal schauen, wann der durch ist. Laut Check der IPs: CHINANET, 21ViaNet(China),Inc., Tencent cloud computing (Beijing) #China #Webcrawler

Step back in time with this intriguing fact about web directories. Click to reveal! #webdirectories #yahoo #webcrawler #onlinedirectory #fridayfacts #didyouknow


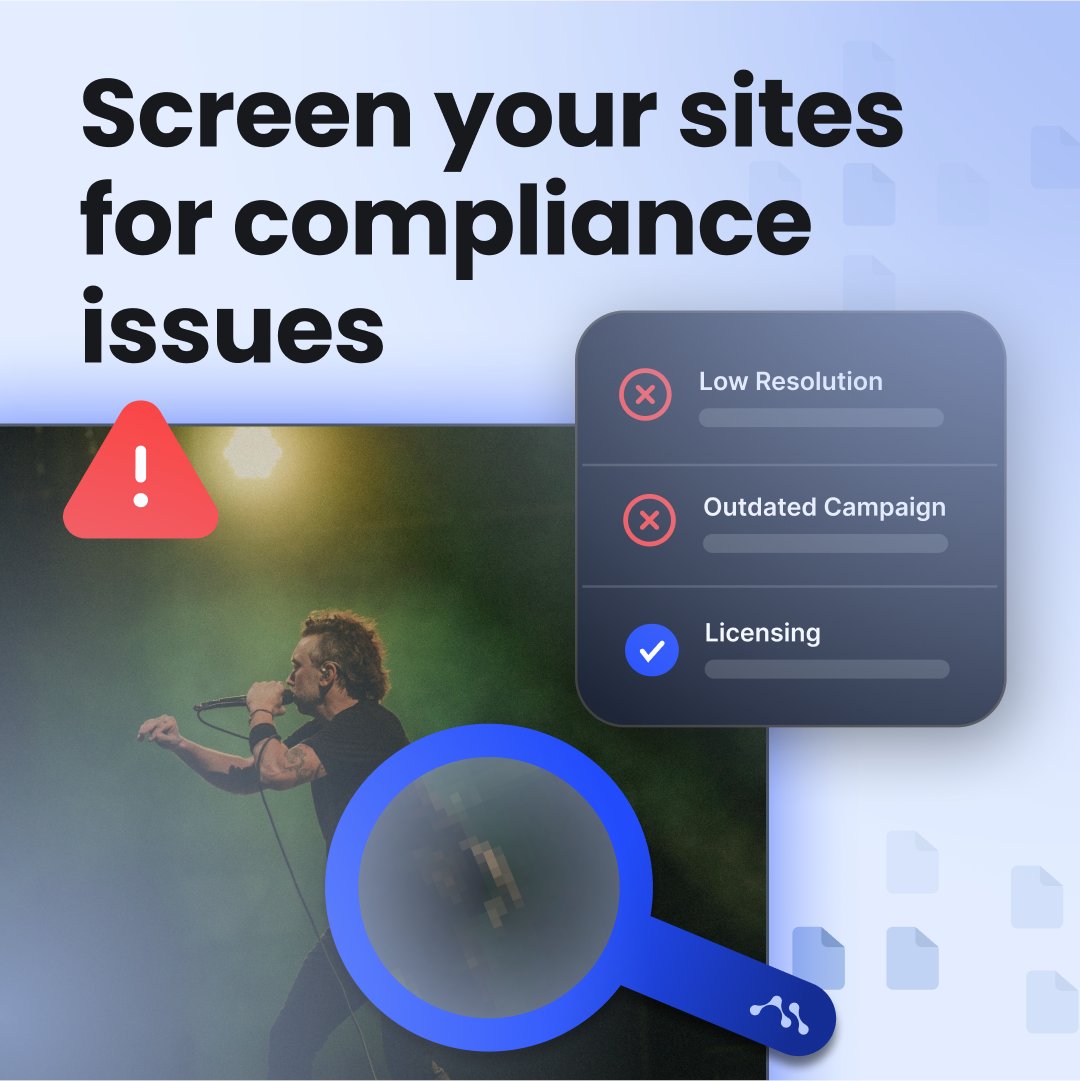
Want to streamline your marketing workflow and seamlessly handle compliance? 🌟 Web Crawler 🕸️ has you covered! Book a demo now—visit our website through the link in bio. 🌐 #medialake #webcrawler #compliance

#100daysofchatgpt loaded #webcrawler #mysql tables to search engine, created constraints No ads, no pop up ad sites, up to date examples. Computer programming and #ai search engine only.. Gonna put some eye candy on the front end #python

#100daysofcode #100dayschatgpt search results, #webcrawler only crawls computer programming and #ai sites. no ads, no pop ups or the site gets deleted from the #mysql db #homelab. Im going to connect my chatbot, chat_history to the search results.

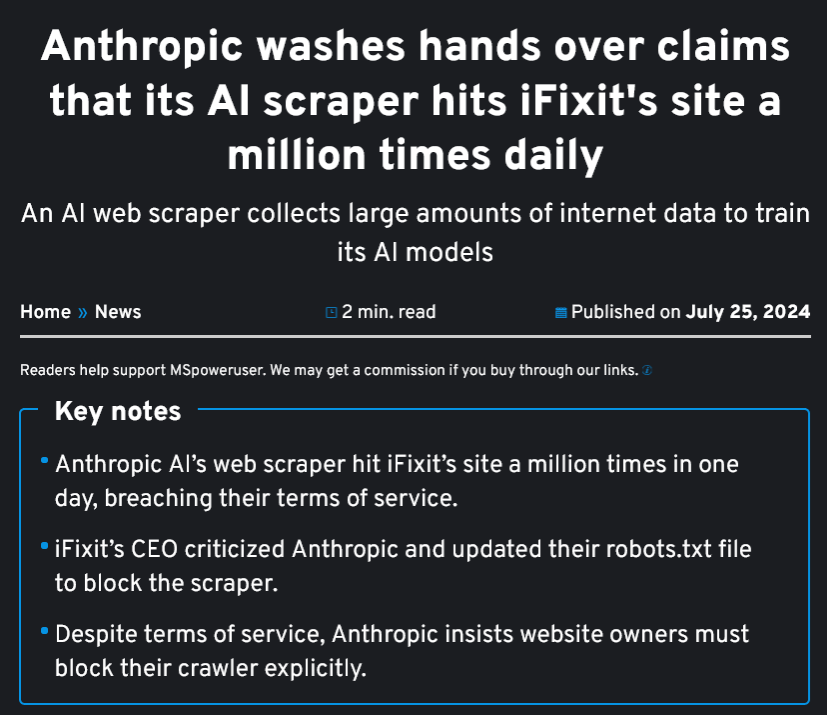
Anthropic washes hands over claims that its AI scraper hits iFixit's site a million times daily mspoweruser.com/anthropic-wash… #ai #webcrawler #webscraper #llm #web #Anthropic
Just connected my #webcrawler and #searchengine to my #chatbot powered by #ChatGPT. Now my #chatbot can provide search results and #webdev content on the fly. Excited to see how this will enhance user experience! #AI #NLP #100daysofcode


The robots.txt file is a text file that defines which parts of a domain can be crawled by a #Webcrawler, and which parts can't be: en.ryte.com/wiki/Robots.txt #SEO
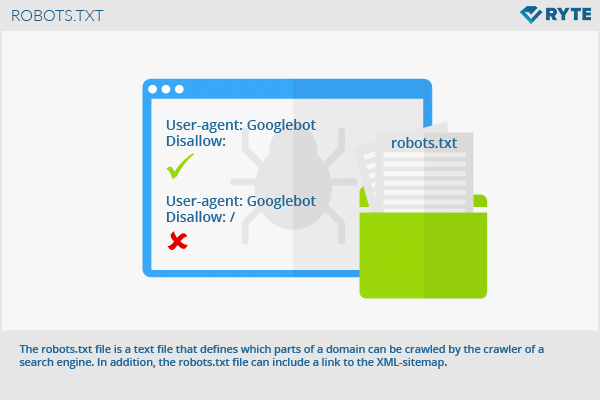

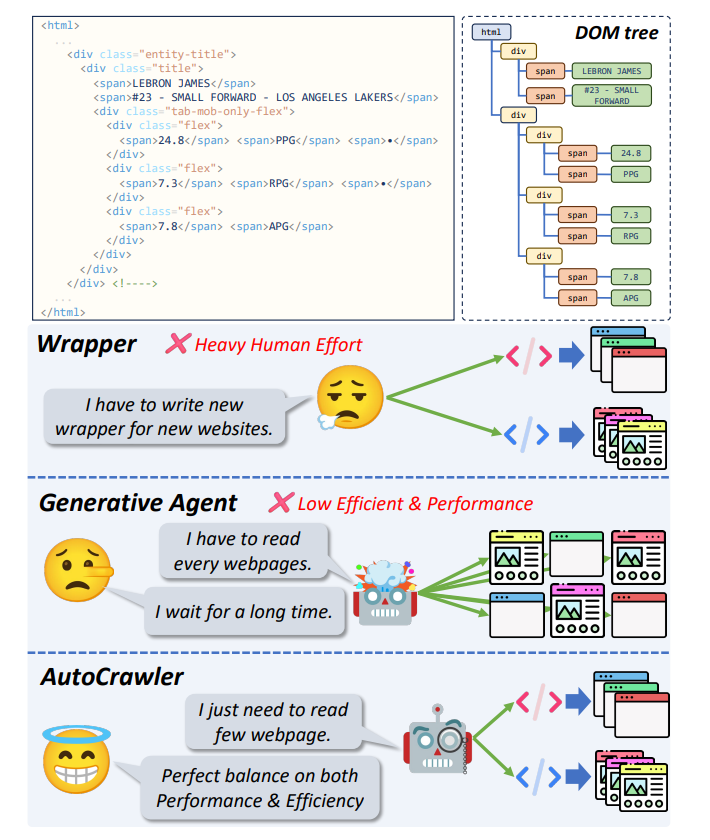
推出了AutoCrawler,这是一个两阶段框架,通过利用HTML的层次结构来逐步深入理解网页内容。 详见论文:arxiv.org/abs/2404.12753 #WebCrawler #AI #技术创新
My rendering of a web robot created by Common Sense Machines' Chat to 3D. 3d.csm.ai I'm planning to make Grow My Search into a 3D interactive web crawler starting with this. ☺️🤖🚀 #GrowMySearch #webcrawler #3D


Google has recently introduced a new web crawler called “GoogleOther,” designed to alleviate strain on Googlebot, its primary search index crawler. buff.ly/3oBD4w5 #Google #WebCrawler #GoogleOther #Googlebot

Como o Google acha sites tão rápido? Web Crawlers (Googlebots) mapeiam a web seguindo links. Daí, algoritmos mostram os mais relevantes em ms!⚡️ Site rápido e estável? Hospede na Square Cloud (squarecloud.app)! #google #seo #webcrawler #tecnologia #indexação #hospedagem


Mix work and play! Bringing you fun and informative brain teasers every week with #GuessTheWord #WebCrawler #Web #IA #Extentia #DoMoreBeMore

New web crawler source code on GitHub! This widens the net by using nltk. github.com/stingraze/wide… #webcrawler #sourcecode
github.com
GitHub - stingraze/wide-cast-crawler: Wide Cast Crawler (as in net) that crawls widely.
Wide Cast Crawler (as in net) that crawls widely. Contribute to stingraze/wide-cast-crawler development by creating an account on GitHub.

Google has lately launched a brand new net crawler referred to as “GoogleOther,” designed to alleviate pressure on Googlebot, its main search index crawler. #Googlebot #Googleother #Webcrawler #Searchindex
Was ist denn da seit ein paar Tagen für ein #Crawler auf meiner Webseite unterwegs? So viele Connections vom Webserver sehe ich nicht immer. Mal schauen, wann der durch ist. Laut Check der IPs: CHINANET, 21ViaNet(China),Inc., Tencent cloud computing (Beijing) #China #Webcrawler

#WebCrawler #BatchDownloader #FileDownloader #BulkDownload #LinkCrawler #Productivity #Automation #DataTools #ResearchTools #DigitalArchiving #WindowsApp #DesktopApp #MicrosoftStore #EthicalCrawling #RespectRobotsTxt #SaveForLater #WorkSmarter apps.microsoft.com/detail/9nrz937…

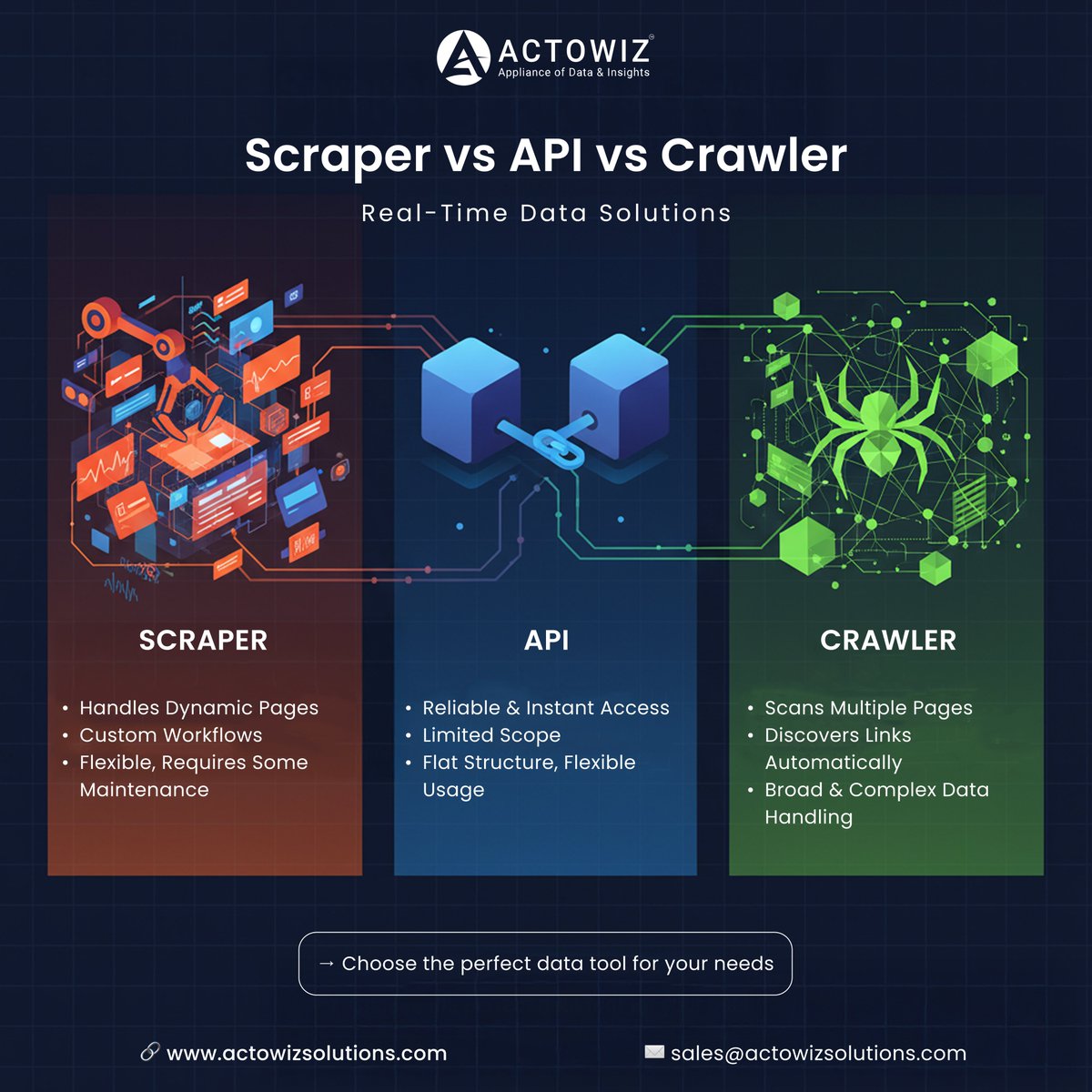
💡 Scraper vs API vs Crawler — which one powers your data game? ⚙️ Scraper → Handles dynamic pages 🔗 API → Instant & reliable data 🕷️ Crawler → Scans massive sites automatically 👉 actowizsolutions.com #WebScraping #APIs #WebCrawler #DataExtraction #Automation

Crawl4AI menyederhanakan proses scraping data web dengan output yang dirancang khusus untuk kebutuhan LLM. Sangat berguna untuk membangun dataset pelatihan model atau memperkaya knowledge base pada sistem RAG. github.com/unclecode/craw… #AI #LLM #WebCrawler #OpenSource

🐸 Try Ultra Frog SEO Crawler your free & open-source alternative to Screaming Frog! Crawl websites, map internal links, and uncover SEO insights instantly. ⚡️ Built for speed. Made for SEOs. 🔗 Try it free: ultra-frog.streamlit.app #SEO #WebCrawler #OpenSource #UltraFrog
ultra-frog.streamlit.app
Streamlit
is a powerful, fast, and professional SEO crawler designed for deep technical analysis of websit...

AI is using web content for training, but is it killing creativity? We dive into the future of AI, copyright, and content ownership. Listen now! bit.ly/likelymktg_ep47 #website #webcrawler #seo #AI #chatgpt #googlegemini #gemini #bing #GenerativeAI #digitalmarketing #podcast

Deduplication stops your web crawler from hitting the same URL twice. In-memory is fast but RAM-limited. Persistent (DB) scales & survives restarts. Pick wisely for efficient crawling! #WebCrawler #SystemDesign




I’m excited to share that #Darkweb_Crawler has introduced a Graphical User Interface (GUI) that will significantly enhance how security professionals approach dark web intelligence. #OSINT #Cybersecurity #ThreatInteliigence
AI development may be slowing due to increased website data restrictions, leading to less accurate data for AI systems. Tune in to explore the implications for marketers! bit.ly/likelymktg_ep47 #website #webcrawler #seo #seostrategy #AI #chatgpt #googlegemini #gemini #bing

AI crawlers playing on nightmare difficulty. Web admins need a serious power-up! Boss fight for content just got real. #webcrawler

AI web crawlers are destroying websites in their never-ending hunger for any and all content! search.app/BL2cV #webcrawler #LLMs #LLM #GPT #GenAI #GenerativeAI #AI #artificial_intelligence @anand_narang @antgrasso @chidambara09 @CurieuxExplorer @Eli_Krumova…


Stop wasting hours hunting socials. Our AI crawler visits any site → finds every profile in seconds. No scraping. No manual grind. Just instant results. 🚀 Comment "ai" and we'll reach out to you. #aiworkflow #autoagentifyco #webcrawler #leadgen #marketing
The crawler reel drops tomorrow. Stay tuned!! This one changes how you find socials forever. #aiworkflow #autoagentifyco #webcrawler #socials #marketing #leadgen

🫵 Join the Pirates.BZ 🏴☠️ #Firecrawl, an #opensource #webcrawler for #developers and #AIagents, raised $14.5 million in a Series A round led by Nexus Venture Partners. The company, which is already profitable, plans to use the funds to expand its team and develop …























💡 Scraper vs API vs Crawler — which one powers your data game? ⚙️ Scraper → Handles dynamic pages 🔗 API → Instant & reliable data 🕷️ Crawler → Scans massive sites automatically 👉 actowizsolutions.com #WebScraping #APIs #WebCrawler #DataExtraction #Automation


Deduplication stops your web crawler from hitting the same URL twice. In-memory is fast but RAM-limited. Persistent (DB) scales & survives restarts. Pick wisely for efficient crawling! #WebCrawler #SystemDesign
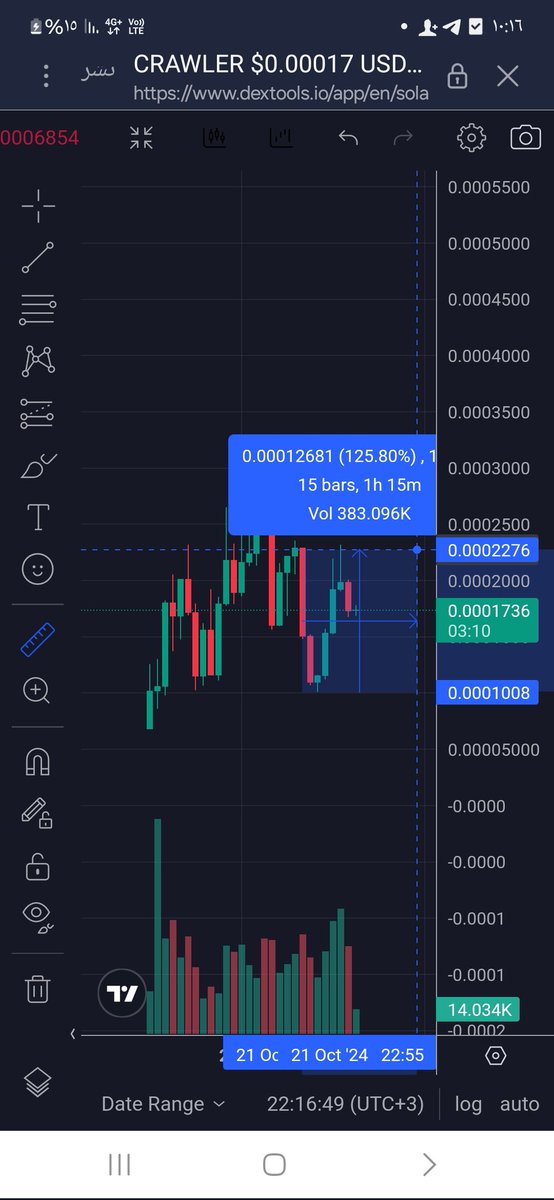
#WEBCRAWLER 100%🔥🔥1X💎💎اول دبل مرتب ✍️تاجر😎الmem✍️

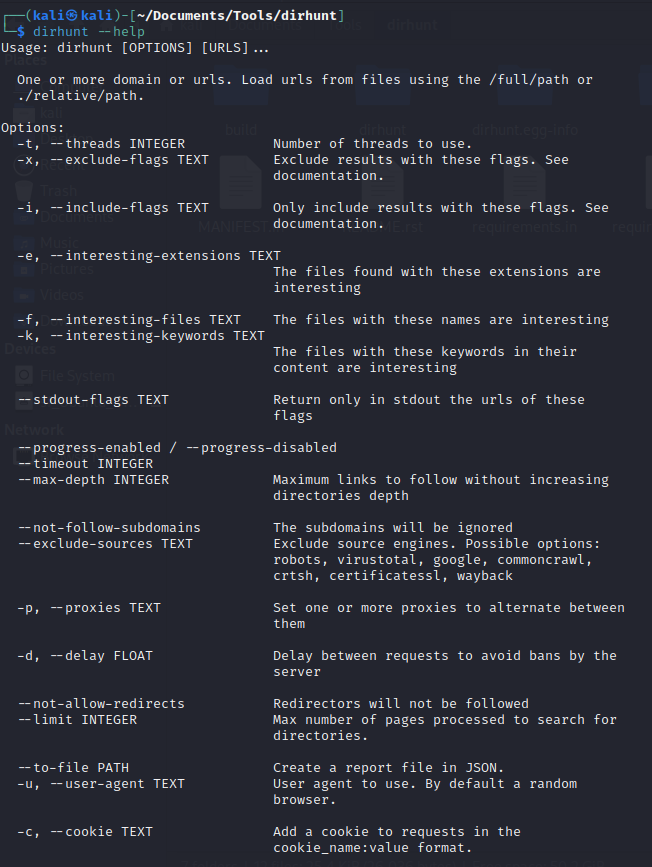
🕷️Dirhunt: Ultimate Directory Crawler for Discovering Hidden! Dirhunt is a web crawler optimize for search and analyze directories. This tool can find interesting things if the server has the "index of" mode enabled.🥷 🚀#Dirhunt #WebCrawler #WebDiscovery #Cybersecurity #Finstein

Here's the front-end for my project named Web Crawler It simply extracts all the links from a given web page. Originally, it was a Command Line Interface (CLI) tool, but I’ve now made it accessible to the public with a user-friendly web interface. 🌐✨ #webcrawler #frontend

Step back in time with this intriguing fact about web directories. Click to reveal! #webdirectories #yahoo #webcrawler #onlinedirectory #fridayfacts #didyouknow
Run reports from lifecycle audits to compliance using our latest feature, web crawler 🧑💻 #webcrawler #newfeature #reporting
Google has recently introduced a new web crawler called “GoogleOther,” designed to alleviate strain on Googlebot, its primary search index crawler. buff.ly/3oBD4w5 #Google #WebCrawler #GoogleOther #Googlebot
推出了AutoCrawler,这是一个两阶段框架,通过利用HTML的层次结构来逐步深入理解网页内容。 详见论文:arxiv.org/abs/2404.12753 #WebCrawler #AI #技术创新
Mix work and play! Bringing you fun and informative brain teasers every week with #GuessTheWord #WebCrawler #Web #IA #Extentia #DoMoreBeMore
🆕 Looking to effortlessly upload files from your websites to Medialake? Wish all assets could be visible with automated meta-data? 📊 Learn more about our brand new feature, Web Crawler 🕸️ #webcrawler #medialake #newfeature



Sites scramble to #block #ChatGPT #webcrawler after instructions emerge buff.ly/3YzLWAo #AI #artificialintelligence


¿Es realmente legal el scraping de datos? ¿El web scraping sólo es posible con python? ¿Podemos obtener los datos que queramos con el data scraping? ...... Lea los 10 mitos más comunes sobre el web scraping: octoparse.es/blog/10-mitos-… #webscraping #webcrawler #python #octoparse

The robots.txt file is a text file that defines which parts of a domain can be crawled by a #Webcrawler, and which parts can't be: en.ryte.com/wiki/Robots.txt #SEO
Anthropic washes hands over claims that its AI scraper hits iFixit's site a million times daily mspoweruser.com/anthropic-wash… #ai #webcrawler #webscraper #llm #web #Anthropic

What Are Web Crawlers and How Do They Work? medium.com/@nandbox/what-… #webcrawler #webcrawling #mobileapp #blog #SaaS #software #nocode #native #nandbox #AppBuilder

Something went wrong.
Something went wrong.
United States Trends
- 1. Cheney 80.3K posts
- 2. Sedition 156K posts
- 3. Lamelo 4,450 posts
- 4. First Take 46.3K posts
- 5. Seditious 86.1K posts
- 6. Jeanie 1,814 posts
- 7. Constitution 109K posts
- 8. Mark Walter 1,339 posts
- 9. Coast Guard 21.1K posts
- 10. Seager N/A
- 11. Commander in Chief 49.3K posts
- 12. Trump and Vance 36.1K posts
- 13. Elon Musk 278K posts
- 14. Cam Newton 4,229 posts
- 15. UNLAWFUL 74.5K posts
- 16. Shayy 13.2K posts
- 17. Nano Banana Pro 23.4K posts
- 18. #WeekndTourLeaks 1,447 posts
- 19. UCMJ 9,721 posts
- 20. Dameon Pierce N/A