#scalablemachinelearning kết quả tìm kiếm

1/n) Scaling across massive datasets can be achieved via hierarchical or federated approaches. Localized models process partitioned subsets, updating global baselines incrementally.

Learn how to scale AI with confidence: Schedule a demo: hubs.li/Q03YJcZX0 #ScalableAI #HealthcareAI #AIAdoption #LLM #ClinicalAI #JohnSnowLabs

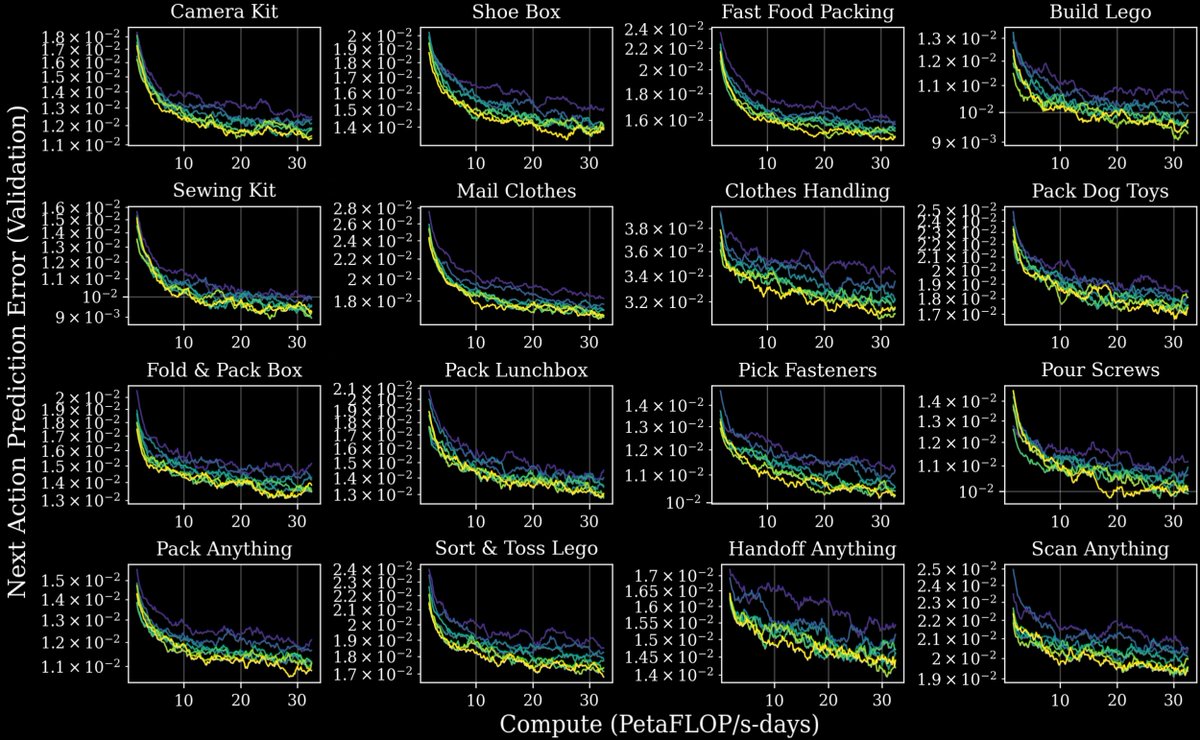
They find power-law scaling between pretraining data and downstream manipulation error. Meaning you can now predict robot performance from data scale. That’s normal for LLMs. It’s new for robots.

They derive a interesting scaling law for the method where the failure rate drops exponentially as you scale candidates N and/or comparisons per match K. This is under two assumptions: the LLM generates a correct solution with non-zero probability and ...
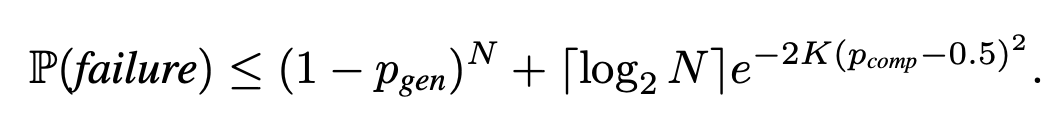

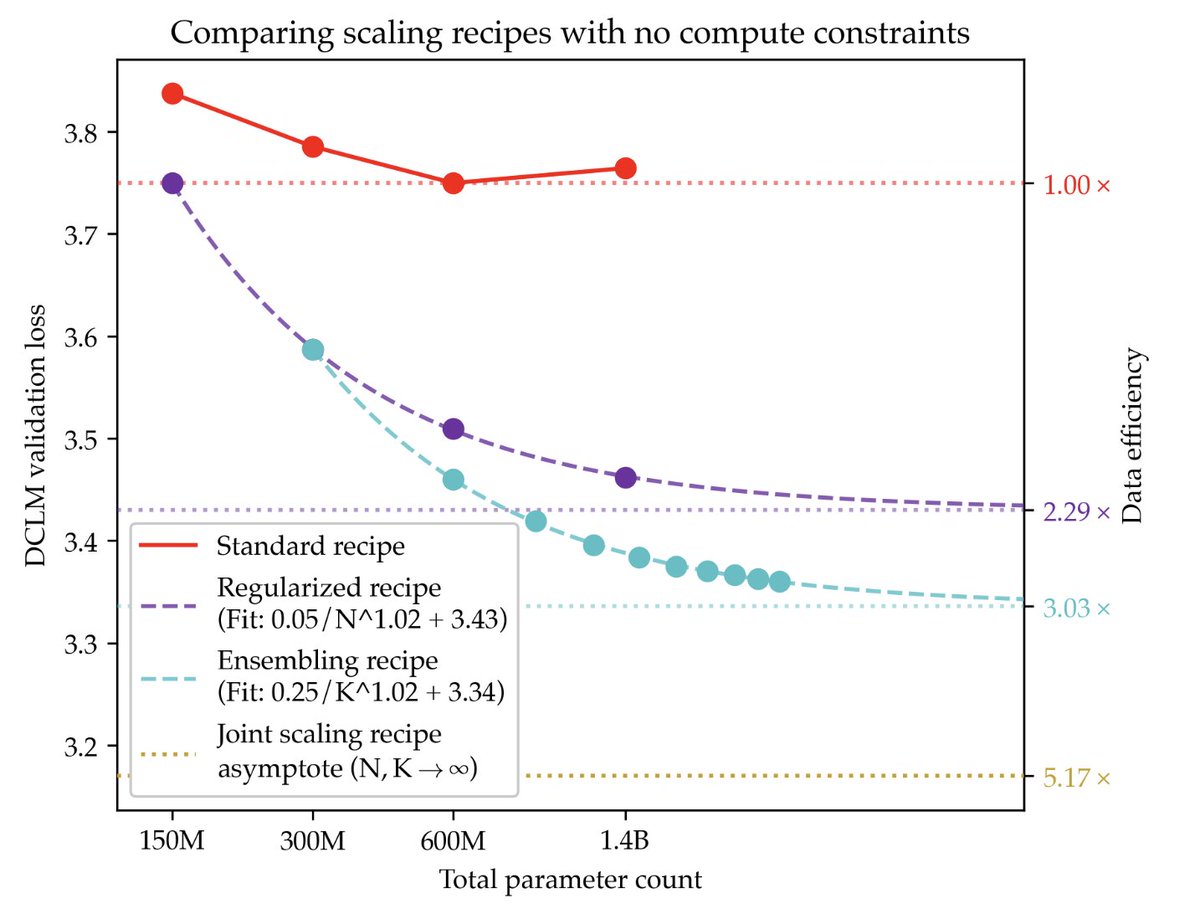
Pre-training under infinite compute • Data, not compute, is the new bottleneck • Standard recipes overfit → fix with strong regularization (30× weight decay) • Scaling laws: loss decreases monotonically, best measured by asymptote not fixed budget

This is the best public resource on scaling hardware for AI, and its free. "How to Scale Your Model" is the bible from Google DeepMind that covers the math, systems and scaling laws for LLM training and inference workloads. Approachable yet thorough. Absolute Must-read.

Large Language Models are getting smarter AND smaller. This video breaks down how AI researchers have made this possible. 00:00 Overview 00:20 Scaling Law 1.0 01:48 Using smaller weights 03:44 Increasing model training 06:05 Google Titans 07:40 What's after Transformers? 08:45…

Scaling is incredibly hard and demanding and leaves very little room for error in every little part of the training stack But once it works, it's beautiful to see it


We’ve answered the three remaining open questions @kellerjordan0 posted at kellerjordan.github.io/posts/muon/: - Yes, Muon scales to larger compute. - Yes, Muon can be trained on a large cluster. - Yes, Muon works for SFT. RL probably works too, leave it to the audience as exercise :)
🚀 Introducing our new tech report: Muon is Scalable for LLM Training We found that Muon optimizer can be scaled up using the follow techniques: • Adding weight decay • Carefully adjusting the per-parameter update scale ✨ Highlights: • ~2x computational efficiency vs AdamW…



This may be the most important figure in LLM research since the OG Chinchilla scaling law in 2022. The key insight is 2 curves working in tandem. Not one. People have been predicting a stagnation in LLM capability by extrapolating the training scaling law, yet they didn't…


📢New research on mechanistic architecture design and scaling laws. - We perform the largest scaling laws analysis (500+ models, up to 7B) of beyond Transformer architectures to date - For the first time, we show that architecture performance on a set of isolated token…


Simple and Scalable Strategies to Continually Pre-train Large Language Models Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually

MosaicML announces Beyond Chinchilla-Optimal Accounting for Inference in Language Model Scaling Laws paper page: huggingface.co/papers/2401.00… Large language model (LLM) scaling laws are empirical formulas that estimate changes in model quality as a result of increasing parameter…

Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws Modifies the scaling laws to calculate the optimal LLM parameter count and pre-training data size to train and deploy a model of a given quality and inference demand arxiv.org/abs/2401.00448


Can we predict the future capabilities of AI? . @ilyasut, co-founder and chief scientist of OpenAI, on the scaling law and an interesting area of research: (1) The scaling law relates the input of the neural network to simple-to-evaluate performance measures like next-word…

A counterintuitive implication of scale: trying to solve a more general version of the problem is an easier way to solve the original problem than directly tackling it. Attempting a more general problem encourages you to come up with a more general and simpler approach. This…

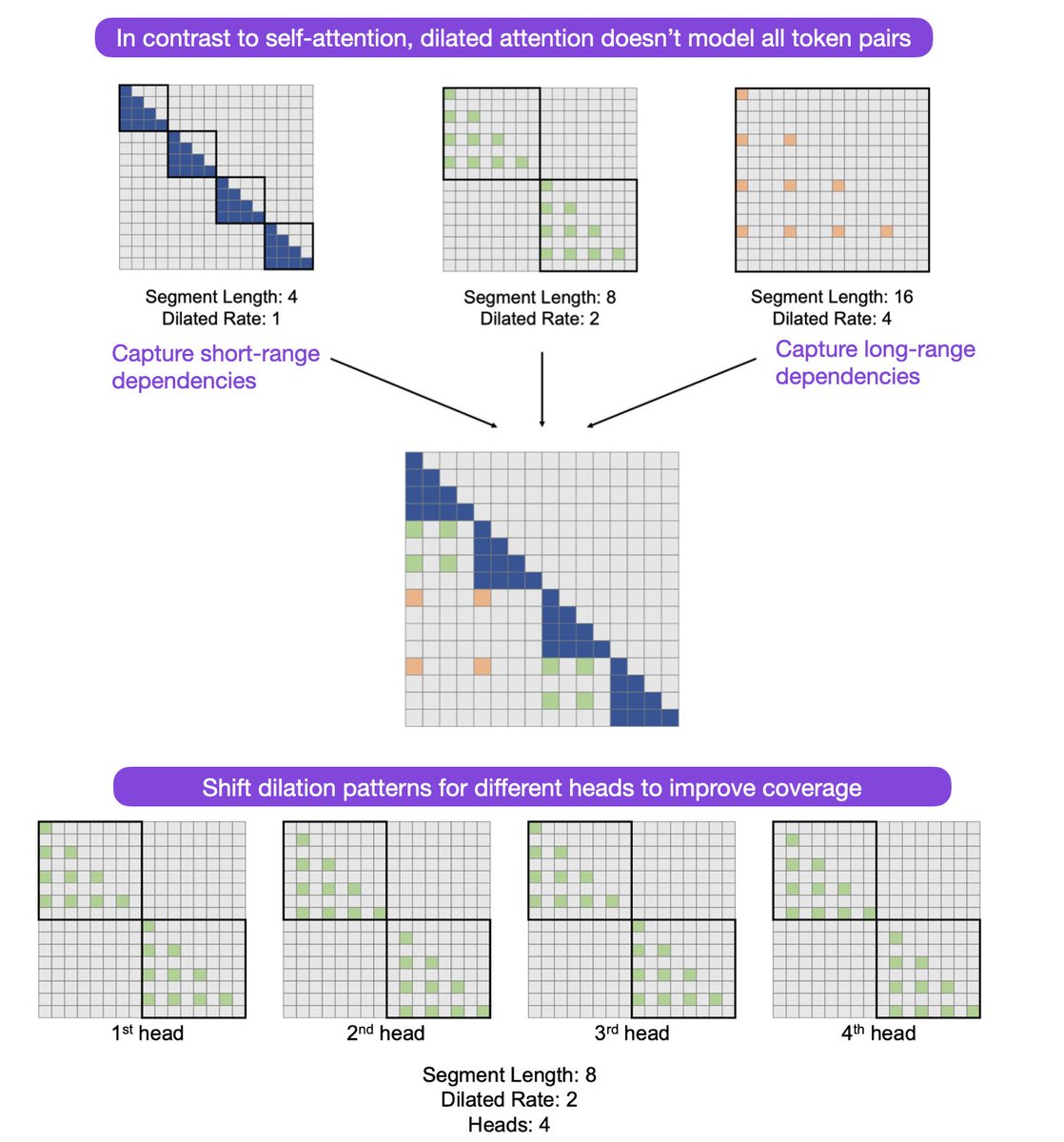
We had 1) the RMT paper on scaling Transformers to 1M tokens, and 2) the convolutional Hyena LLM for 1M tokens. How about 3) LONGNET: Scaling Transformers to 1 Billion Tokens (arxiv.org/abs/2307.02486)!? It achieves linear (vs quadratic) scaling via dilated (vs self) attention.

RT Machine Learning on Graphs, Part 3 dlvr.it/S8lLdv #graphmachinelearning #scalablemachinelearning #graphkernels


Training large models demands a lot of GPU memory and a long training time. With several training parallelism strategies and a variety of memory saving designs, it is possible to train very large neural networks across many GPUs. lilianweng.github.io/lil-log/2021/0…
RT Explicit feature maps for non-linear kernel functions dlvr.it/S6t26D #scikitlearn #machinelearning #scalablemachinelearning #kerneltrick
Something went wrong.
Something went wrong.
United States Trends
- 1. Steelers 75.9K posts
- 2. Mark Andrews 3,884 posts
- 3. Lamar 20.1K posts
- 4. Ravens 32.1K posts
- 5. Lions 85.9K posts
- 6. #Married2Med 3,131 posts
- 7. Derrick Henry 3,944 posts
- 8. Drake Maye 7,487 posts
- 9. Toya 5,310 posts
- 10. Jags 15.8K posts
- 11. #RHOP 5,573 posts
- 12. Henderson 11.5K posts
- 13. Broncos 37K posts
- 14. #HereWeGo 9,284 posts
- 15. #BaddiesUSA 5,317 posts
- 16. Goff 9,001 posts
- 17. Contreras 10.8K posts
- 18. Nicki Minaj 143K posts
- 19. Teslaa 3,293 posts
- 20. #Patriots 3,138 posts