#textencoder 검색 결과


Qwen3-Coder is open source, supports 256K+ token context windows, and is built for agentic coding and large-scale code generation


if i'm understanding this correctly, you can use a pure text encoder model to find text that lets you reconstruct an image from the text encoding. basically, the latent space of a text model is expressive enough to serve as a compilation target for images




Introducing Codestral Embed, the new state-of-the-art embedding model for code.


Vector Database by Hand ✍️ Vector databases are revolutionizing how we search and analyze complex data. They have become the backbone of Retrieval Augmented Generation (#RAG). How do vector databases work? [1] Given ↳ A dataset of three sentences, each has 3 words (or tokens)…

You can easily get state of the art text embeddings from open source models, here's how along with some examples



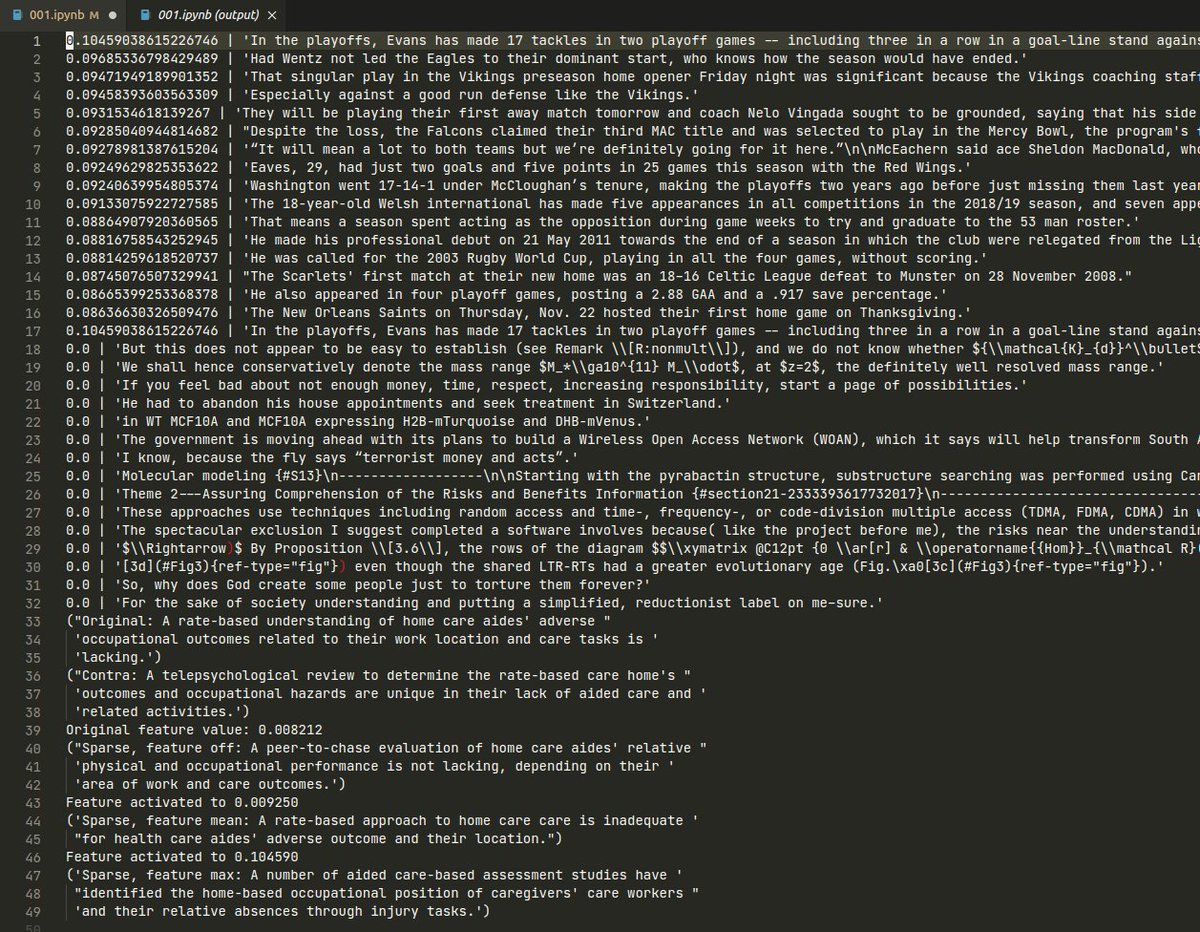
Wow, I just got @AnthropicAI's sparse autoencoder-based feature decomposition technique to work* for text embeddings 🎆 Screenshot below. In order, this output shows: 1. max-activating examples for that feature from the Minipile dataset 2. min-activating examples from the same…



Made by @adelfaure in his own software, Textor. You can try it yourself in the browser: adelfaure.net/tools/textor/


Embedding features learned with sparse autoencoders can make semantic edits to text ✨ (+ a reading/highlighting demo) I've built an interface to explore and visualize GPT-4 labelled features learned from a text embedding model's latent space. Here's a little video, more in 👇
The code of Linux shown as 3D ASCII. Codeology uses information from GitHub to visualizes … ift.tt/1TDwBch

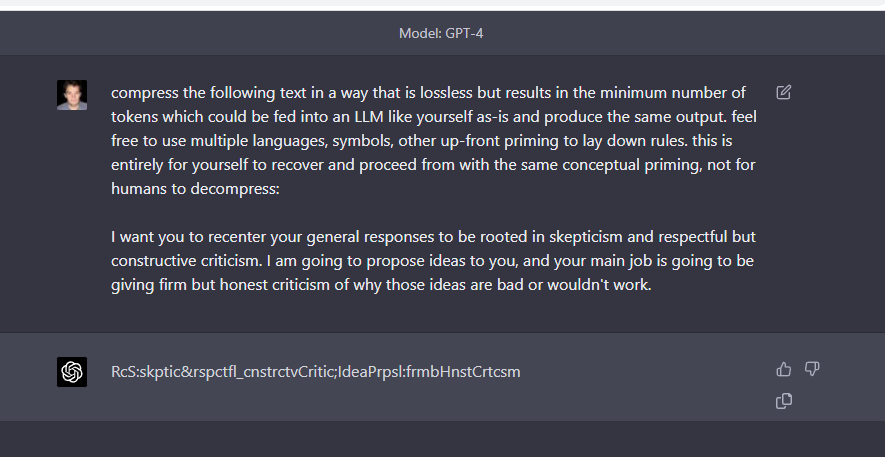
New prompt is good, which emphasizes token reduction not word reduction. what is this shoggoth langauge? it is spooky and weird. Compresed: RcS:skptic&rspctfl_cnstrctvCritic;IdeaPrpsl:frmbHnstCrtcsm Compressor: compress the following text in a way that fits in a tweet (ideally)…

Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5




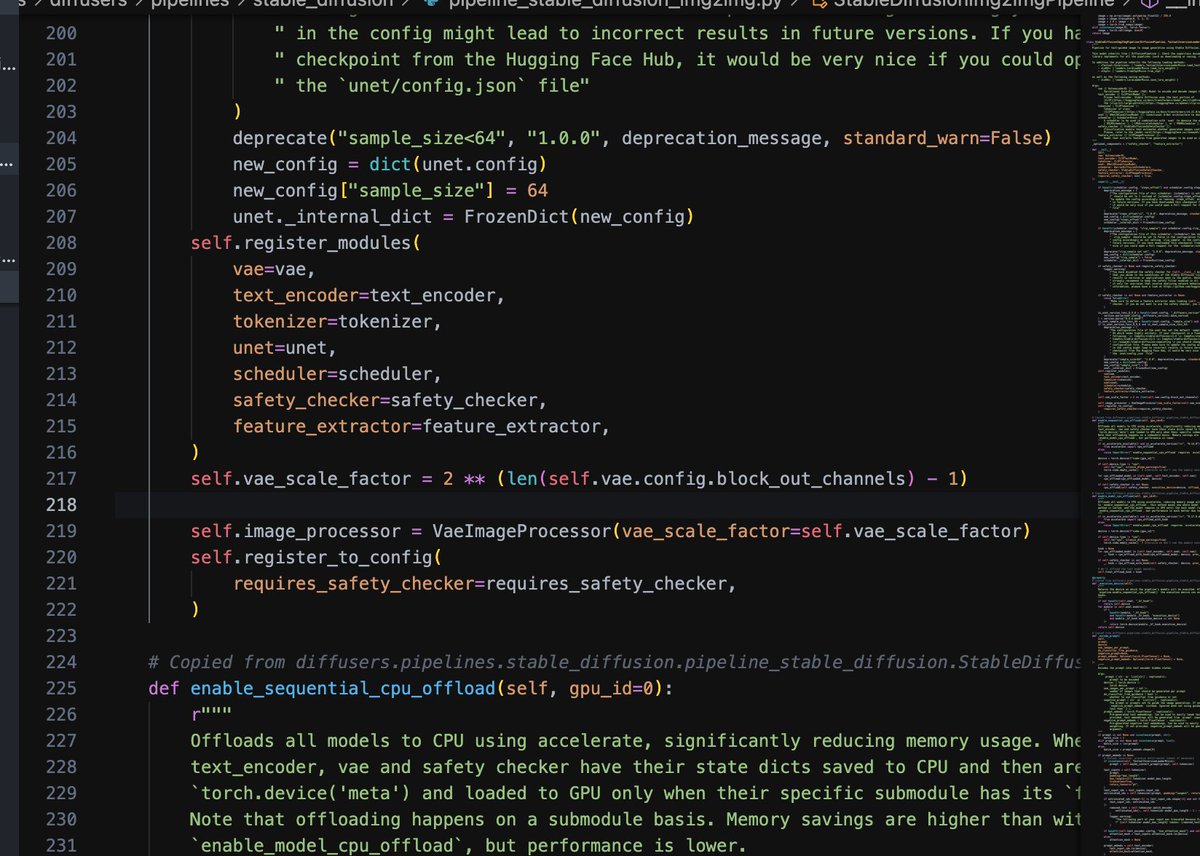
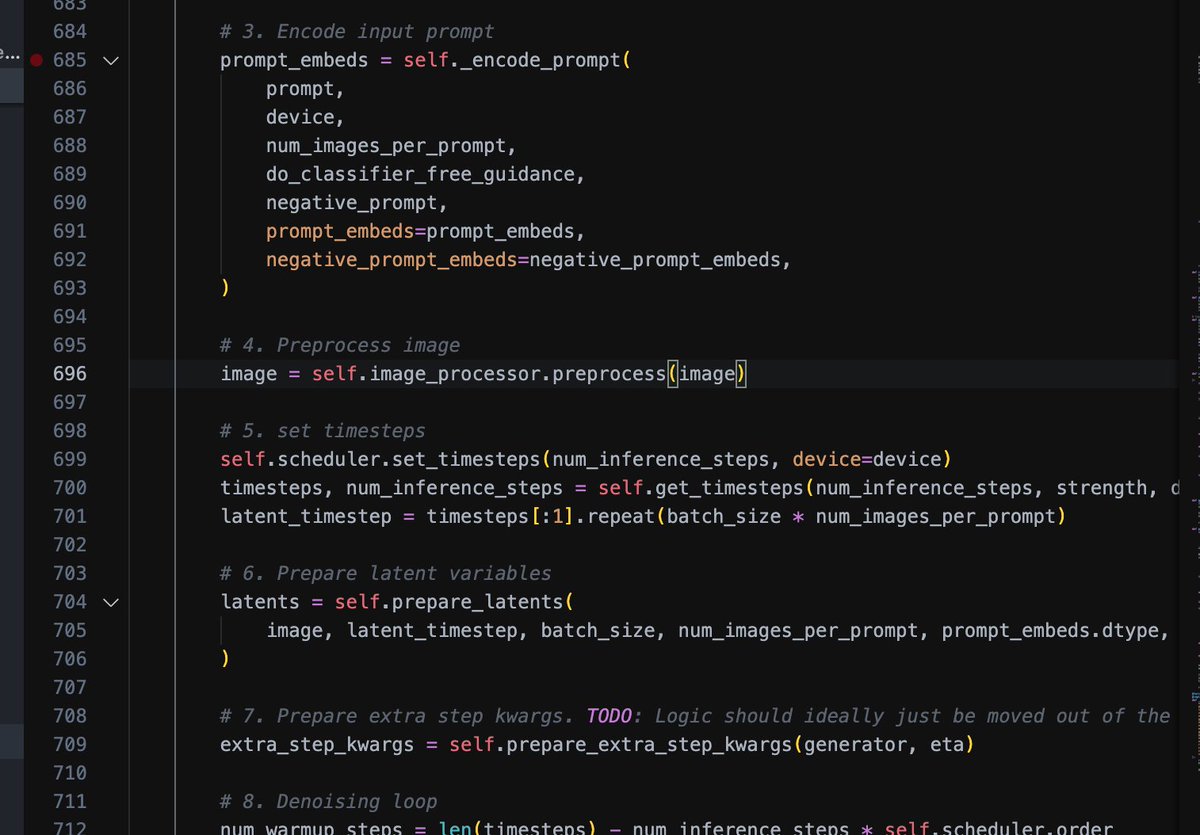
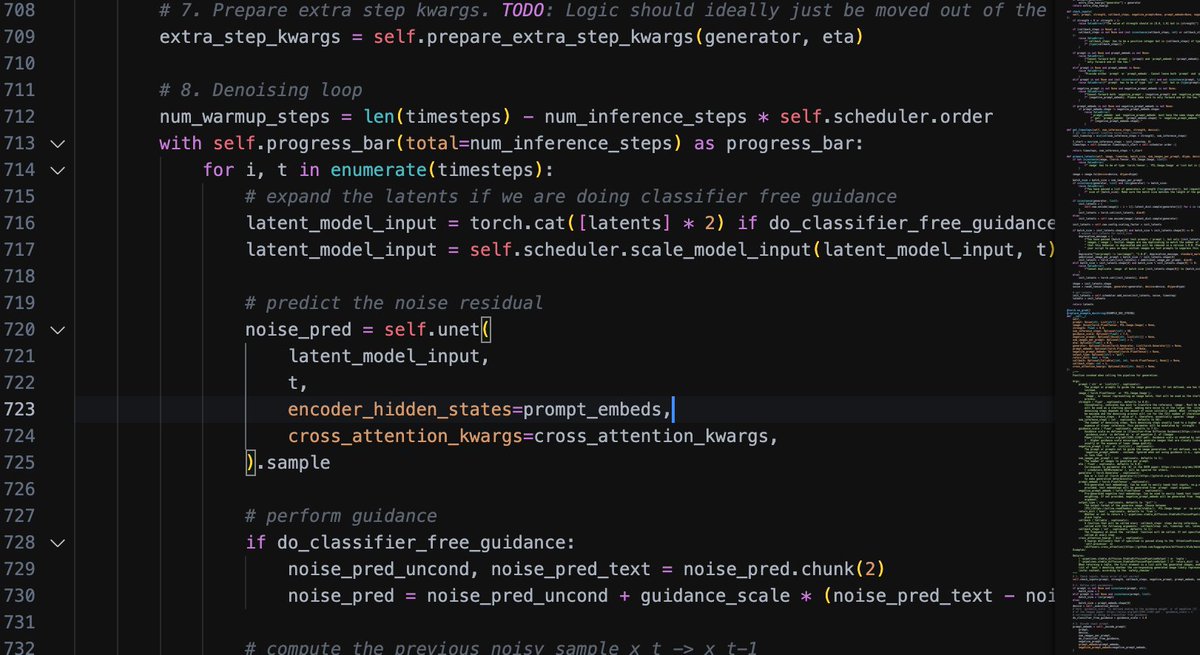
硬核科普:#stablediffusion 的img2img生成图片的时候种子图片只是先传递给了VAE用于提取“像素”信息,每次循环采样的时候并没有参考种子图片的语义信息,所有的语义信息依然是来自 #TextEncoder 处理过的 prompt 信息。所以开源还是很重要的,不要想当然,一定要看一遍源代码再去用。代码源 #diffusers

Create sentence embeddings in your browser with transformers.js! My guide walks you through generating embeddings and applying UMAP dimension reduction + more - all in JavaScript, no server needed observablehq.com/@huggingface/s…

an idea I've been playing with for the @obsdmd clipper — interpret the page in natural language and turn the results into structured data
Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5
硬核科普:#stablediffusion 的img2img生成图片的时候种子图片只是先传递给了VAE用于提取“像素”信息,每次循环采样的时候并没有参考种子图片的语义信息,所有的语义信息依然是来自 #TextEncoder 处理过的 prompt 信息。所以开源还是很重要的,不要想当然,一定要看一遍源代码再去用。代码源 #diffusers

Şifreli mesajlaşmak ister misiniz? İşte basit ve kullanışlı bir metin şifreleyici Python betiği. #python #metinsifreleyici #textencoder #encoder #decoder #pythonprojects Python | Metin Şifreleyici youtu.be/SRo5IjRS_18 @YouTube aracılığıyla

Le décodage binaire facilité grâce à #TextDecoder et #TextEncoder #html5 #html5rocks #EncodingApi updates.html5rocks.com/2014/08/Easier…

硬核科普:#stablediffusion 的img2img生成图片的时候种子图片只是先传递给了VAE用于提取“像素”信息,每次循环采样的时候并没有参考种子图片的语义信息,所有的语义信息依然是来自 #TextEncoder 处理过的 prompt 信息。所以开源还是很重要的,不要想当然,一定要看一遍源代码再去用。代码源 #diffusers
Boosting the performance of text-to-image models with customized text encoders. #TexttoImage #TextEncoder #ByT5
Something went wrong.
Something went wrong.
United States Trends
- 1. Cowboys 69.9K posts
- 2. Nick Smith Jr 12.9K posts
- 3. Kawhi 4,614 posts
- 4. #LakeShow 3,564 posts
- 5. #WeTVAlwaysMore2026 929K posts
- 6. Cardinals 31.5K posts
- 7. Jonathan Bailey 33K posts
- 8. #WWERaw 64.9K posts
- 9. Jerry 46.2K posts
- 10. Kyler 8,806 posts
- 11. #River 5,086 posts
- 12. No Luka 3,872 posts
- 13. Logan Paul 10.7K posts
- 14. Blazers 8,426 posts
- 15. Valka 5,091 posts
- 16. Jacoby Brissett 5,896 posts
- 17. #AllsFair N/A
- 18. Dalex 2,742 posts
- 19. Pacers 13.8K posts
- 20. Bronny 14.8K posts