
BigCode
@BigCodeProject
Open and responsible research and development of large language models for code. #BigCodeProject run by @huggingface + @ServiceNowRSRCH
Potrebbero piacerti















Introducing: StarCoder2 and The Stack v2 ⭐️ StarCoder2 is trained with a 16k token context and repo-level information for 4T+ tokens. All built on The Stack v2 - the largest code dataset with 900B+ tokens. All code, data and models are fully open! hf.co/bigcode/starco…


It’s so much fun working with the other 39 community members on this project! Start to try out various frontier models in BigCodeArena today.
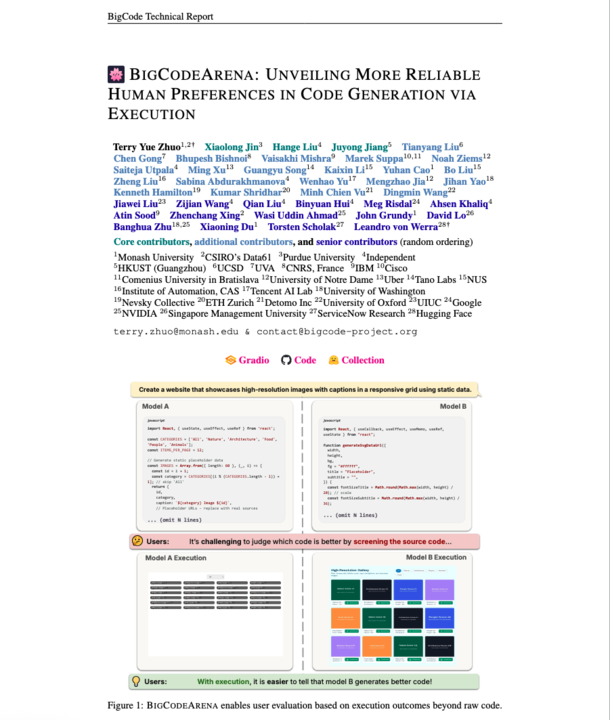
Introducing BigCodeArena, a human-in-the-loop platform for evaluating code through execution. Unlike current open evaluation platforms that collect human preferences on text, it enables interaction with runnable code to assess functionality and quality across any language.

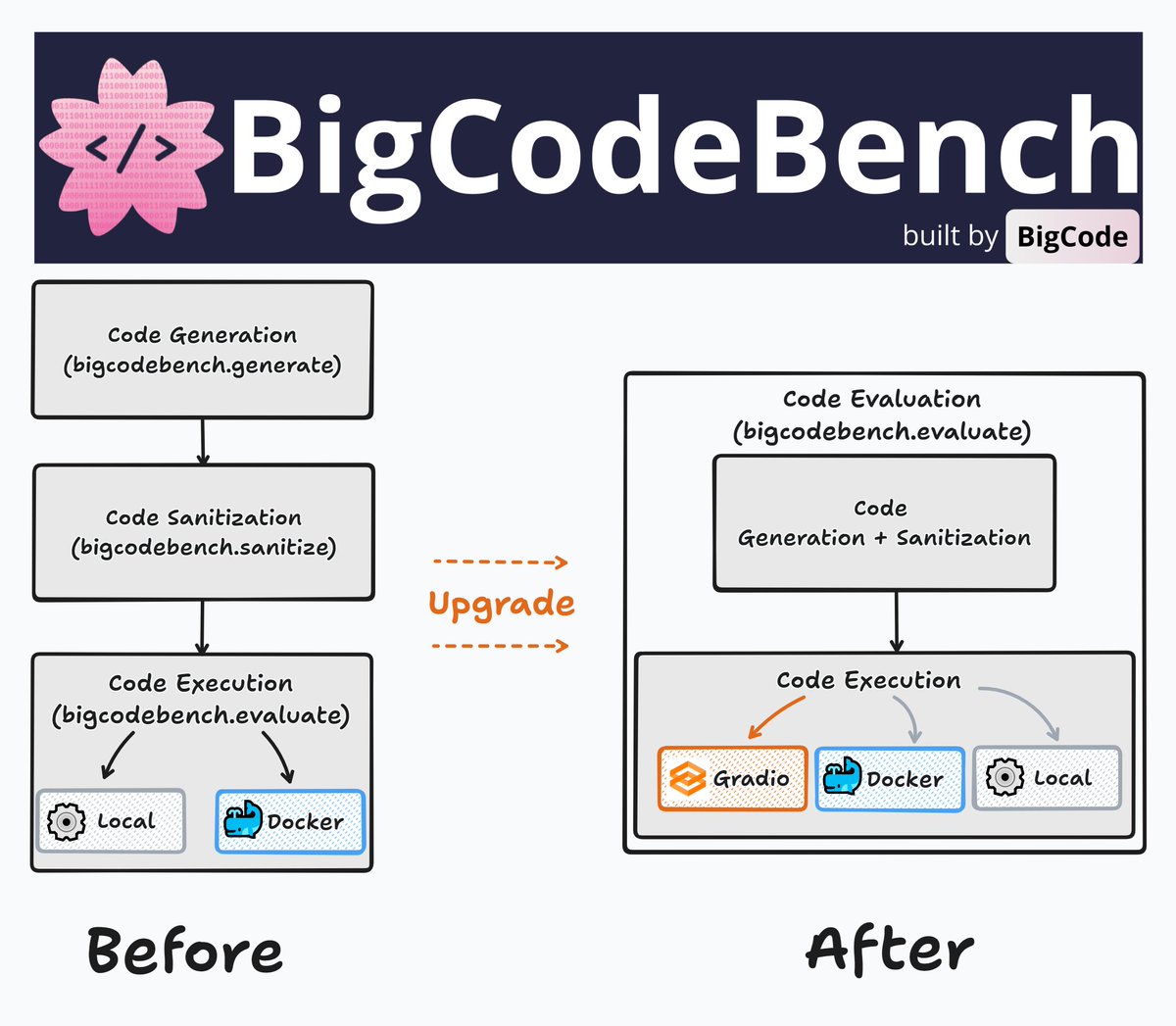
BigCodeBench @BigCodeProject evaluation framework has been fully upgraded! Just pip install -U bigcodebench With v0.2.0, it's now much easier to use compared to the previous v0.1.* versions. The new version adopts the @Gradio Client API interface from @huggingface Spaces by…
Evaluating LM agents has come a long way since gpt-4 released in March of 2023. We now have SWE-Bench, (Visual) Web Arena, and other evaluations that tell us a lot about how the best models + architectures do on hard and important tasks. There's still lots to do, though 🧵
People may think BigCodeBench @BigCodeProject is nothing more than a straightforward coding benchmark, but it is not. BigCodeBench is a rigorous testbed for LLM agents using code to solve complex and practical challenges. Each task demands significant reasoning capabilities for…

By popular demand, I have released the StarCoder2 code documentation dataset, please check it out ⬇️ hf.co/datasets/Sivil…


This work will appear at OOPSLA 2024. New since last year: the StarCoder2 LLM from @BigCodeProject uses MultiPL-T as part of its pretraining corpus.
LLMs are great at programming tasks... for Python and other very popular PLs. But, they are often unimpressive at artisanal PLs, like OCaml or Racket. We've come up with a way to significantly boost LLM performance of on low-resource languages. If you care about them, read on!
Today, we are happy to announce the beta mode of real-time Code Execution for BigCodeBench @BigCodeProject, which has been integrated into our Hugging Face leaderboard. We understand that setting up a dependency-based execution environment can be cumbersome, even with the…

In the past few months, we’ve seen SOTA LLMs saturating basic coding benchmarks with short and simplified coding tasks. It's time to enter the next stage of coding challenge under comprehensive and realistic scenarios! -- Here comes BigCodeBench, benchmarking LLMs on solving…

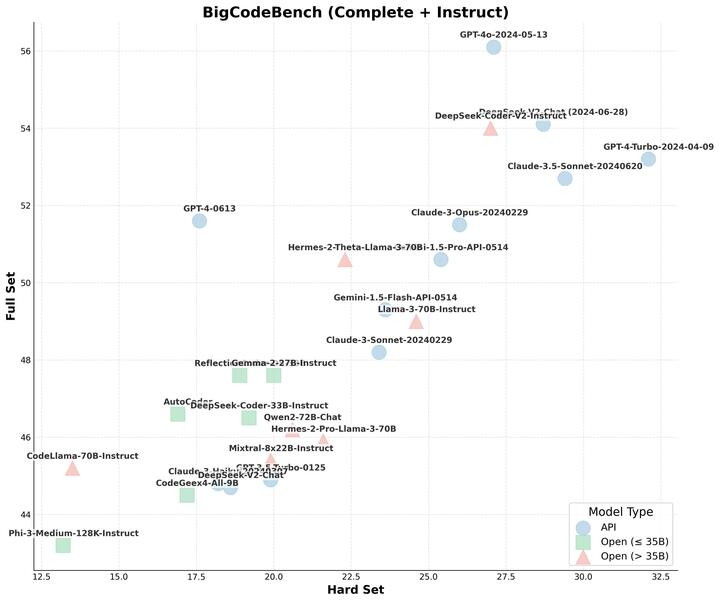
Releasing BigCodeBench-Hard: a subset of more challenging and user-facing tasks. BigCodeBench-Hard provides more accurate model performance evaluations and we also investigate some recent model updates. Read more: huggingface.co/blog/terryyz/b… Leaderboard: huggingface.co/spaces/bigcode…

BigCodeBench dataset🌸 Use it as inspiration when building your Generative AI evaluations. BigCodeBench h/t: @BigCodeProject @terryyuezhuo @lvwerra @clefourrier @huggingface (to name just a few of the people involved)
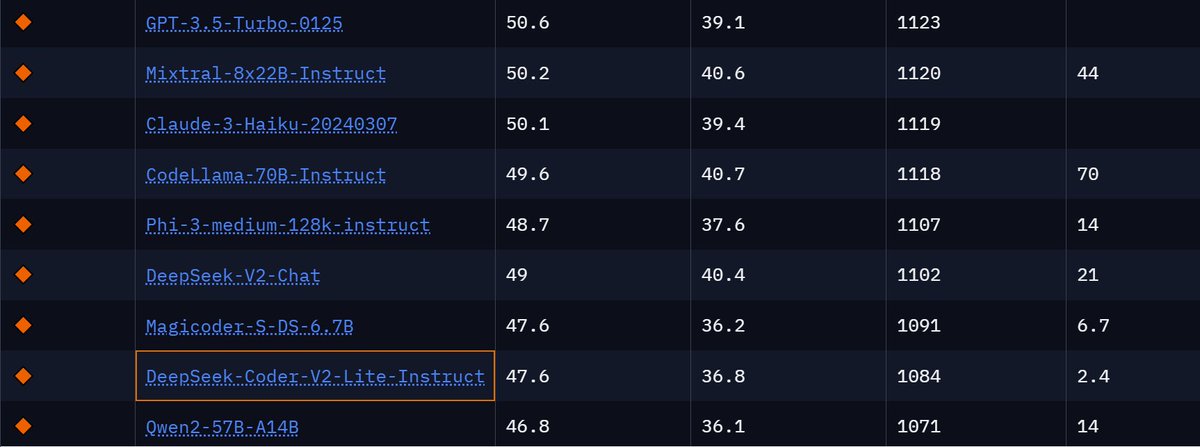
Ppl are curious about the performance of DeepSeek-Coder-V2-Lite on BigCodeBench. We've added its results, along with a few other models, to the leaderboard! huggingface.co/spaces/bigcode… DeepSeek-Coder-V2-Lite-Instruct is a beast indeed, similar to Magicoder-S-DS-6.7B, but with only…
Introducing 🌸BigCodeBench: Benchmarking Large Language Models on Solving Practical and Challenging Programming Tasks! BigCodeBench goes beyond simple evals like HumanEval and MBPP and tests LLMs on more realistic and challenging coding tasks.

It is time to deprecate HumanEval! 🧑🏻💻 @BigCodeProject just released BigCodeBench, a new benchmark to evaluate LLMs on challenging and complex coding tasks focused on realistic, function-level tasks that require the use of diverse libraries and complex reasoning! 👀 🧩 Contains…

In the past few months, we’ve seen SOTA LLMs saturating basic coding benchmarks with short and simplified coding tasks. It's time to enter the next stage of coding challenge under comprehensive and realistic scenarios! -- Here comes BigCodeBench, benchmarking LLMs on solving…
Introducing 🌸BigCodeBench: Benchmarking Large Language Models on Solving Practical and Challenging Programming Tasks! BigCodeBench goes beyond simple evals like HumanEval and MBPP and tests LLMs on more realistic and challenging coding tasks.


































































United States Tendenze
- 1. Columbus 100K posts
- 2. #WWERaw 43.8K posts
- 3. #IndigenousPeoplesDay 6,029 posts
- 4. Middle East 187K posts
- 5. $BURU N/A
- 6. Seth 38.5K posts
- 7. #IDontWantToOverreactBUT 1,117 posts
- 8. Darius Smith 1,011 posts
- 9. Marc 40.3K posts
- 10. Thanksgiving 47.5K posts
- 11. #SwiftDay 9,620 posts
- 12. The Vision 90.6K posts
- 13. Flip 49.8K posts
- 14. Egypt 189K posts
- 15. Knesset 151K posts
- 16. THANK YOU PRESIDENT TRUMP 55.9K posts
- 17. Victory Monday 2,885 posts
- 18. #MondayMorning 2,350 posts
- 19. Bronson 8,165 posts
- 20. Heyman 6,239 posts
Potrebbero piacerti
-
 Hugging Face
Hugging Face
@huggingface -
 Geoffrey Hinton
Geoffrey Hinton
@geoffreyhinton -
 Anthropic
Anthropic
@AnthropicAI -
 clem 🤗
clem 🤗
@ClementDelangue -
 Jim Fan
Jim Fan
@DrJimFan -
 Stability AI
Stability AI
@StabilityAI -
 Tri Dao
Tri Dao
@tri_dao -
 lmarena.ai
lmarena.ai
@arena -
 Gradio
Gradio
@Gradio -
 Aran Komatsuzaki
Aran Komatsuzaki
@arankomatsuzaki -
 Nous Research
Nous Research
@NousResearch -
 Harrison Chase
Harrison Chase
@hwchase17 -
 Piotr Nawrot
Piotr Nawrot
@p_nawrot -
 Zekun Wang (ZenMoore) 🔥
Zekun Wang (ZenMoore) 🔥
@ZenMoore1 -
 Yi Tay
Yi Tay
@YiTayML
Something went wrong.
Something went wrong.