내가 좋아할 만한 콘텐츠







🎉 ¡No te pierdas el Asunción AI & Deep Learning Meetup 2025-01 ! 🤖 📅 22/01/2025 ⏰ 18:30-20:30 📍 Táva Comedor maps.app.goo.gl/uD43n382G1VxjE… 📝 Confirma aquí: meetup.com/asuncion-artif… Auspicia @h2oai #IA #DeepLearning #DataScience
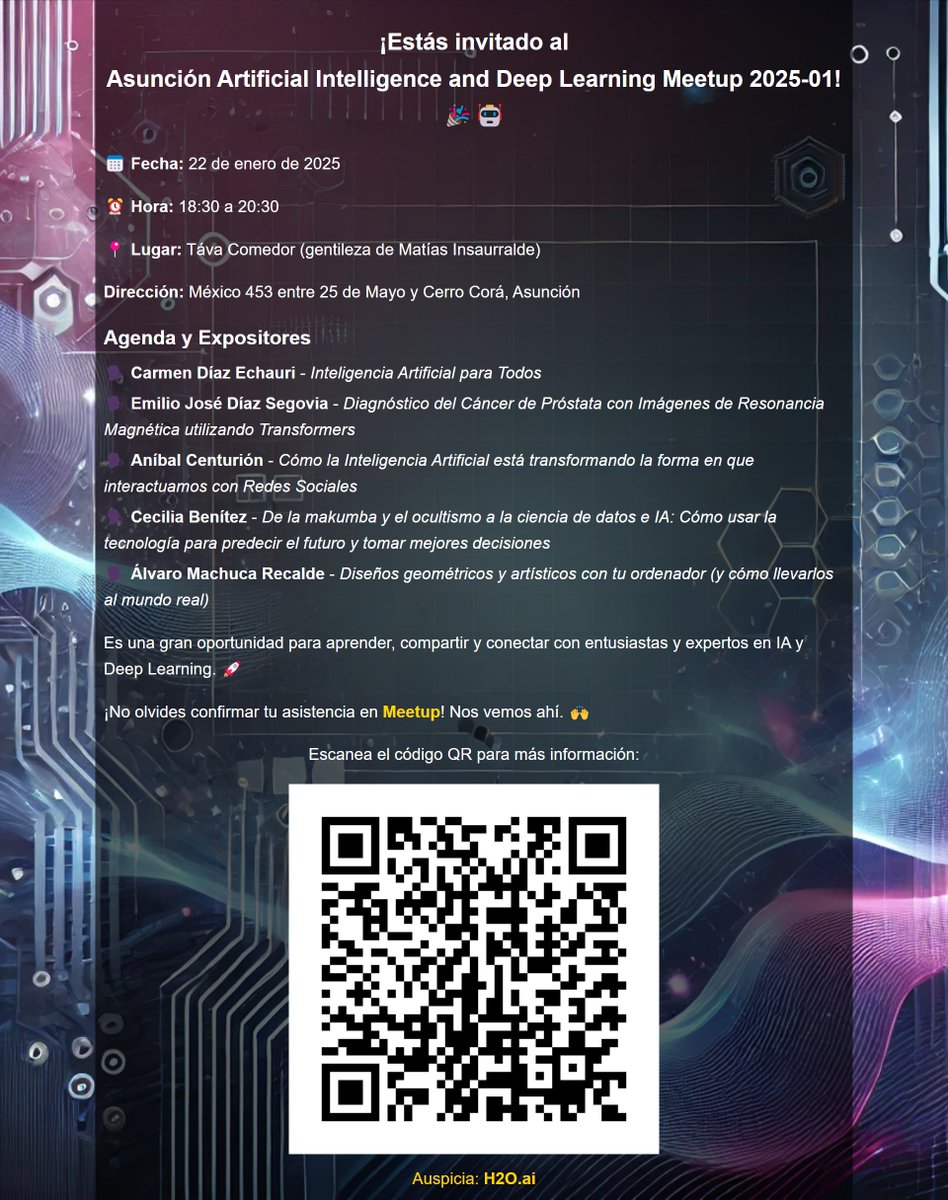


Asunción Artificial Intelligence and Deep Learning Meetup meetup.com/asuncion-artif… #Meetup via @Meetup


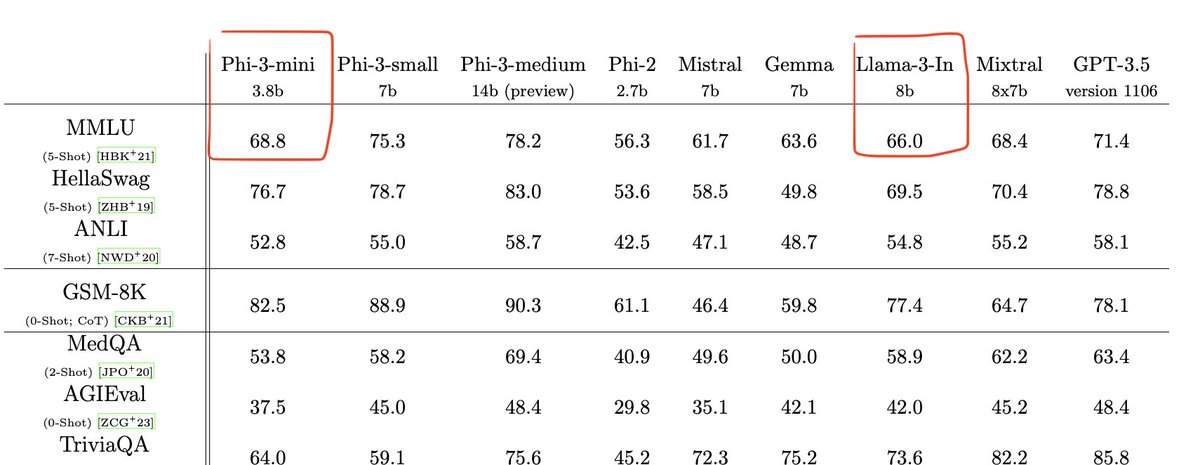
Phi-3 has "only" been trained on 5x fewer tokens than Llama 3 (3.3 trillion instead of 15 trillion) Phi-3-mini less has "only" 3.8 billion parameters, less than half the size of Llama 3 8B. Despite being small enough to be deployed on a phone (according to the technical…
I can't believe microsoft just dropped phi-3 less than a week after llama 3 arxiv.org/abs/2404.14219. And it looks good!

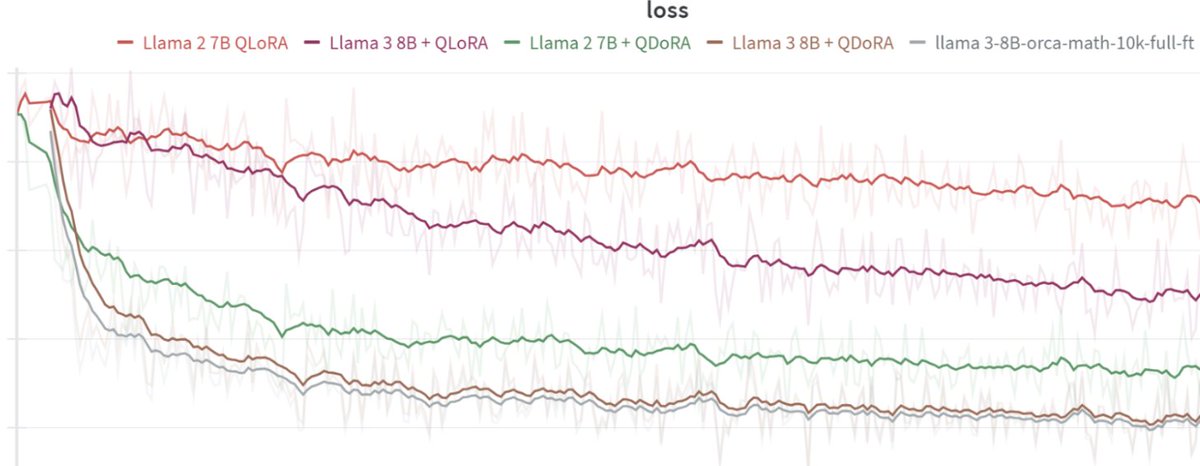
Today at @answerdotai we've got something new for you: FSDP/QDoRA. We've tested it with @AIatMeta Llama3 and the results blow away anything we've seen before. I believe that this combination is likely to create better task-specific models than anything else at any cost. 🧵
Buenas, si hablan Guarani-Jopara les pido el favor de completar las preguntas que puedan del Google Form para un trabajo Tesis de Maestria en Ciencia de Datos de manera a validar un dataset para un modelo de lenguage Guarani. Favor compartir. forms.gle/xYQRHonhVHcF8Z…

Had a look through @Grok's code: 1. Attention is scaled by 30/tanh(x/30) ?! 2. Approx GELU is used like Gemma 3. 4x Layernoms unlike 2x for Llama 4. RMS Layernorm downcasts at the end unlike Llama - same as Gemma 5. RoPE is fully in float32 I think like Gemma 6. Multipliers are 1…


Exciting News from Open-Sora! 🚀 They've just made the ENTIRE suite of their video-generation model open source! Dive into the world of cutting-edge AI with access to model weights, comprehensive training source code, and detailed architecture insights. Start building your dream…
Grok weights are out under Apache 2.0: github.com/xai-org/grok It's more open source than other open weights models, which usual come with usage restrictions. It's less open source than Pythia, Bloom, and OLMo, which come with training code and reproducible datasets.
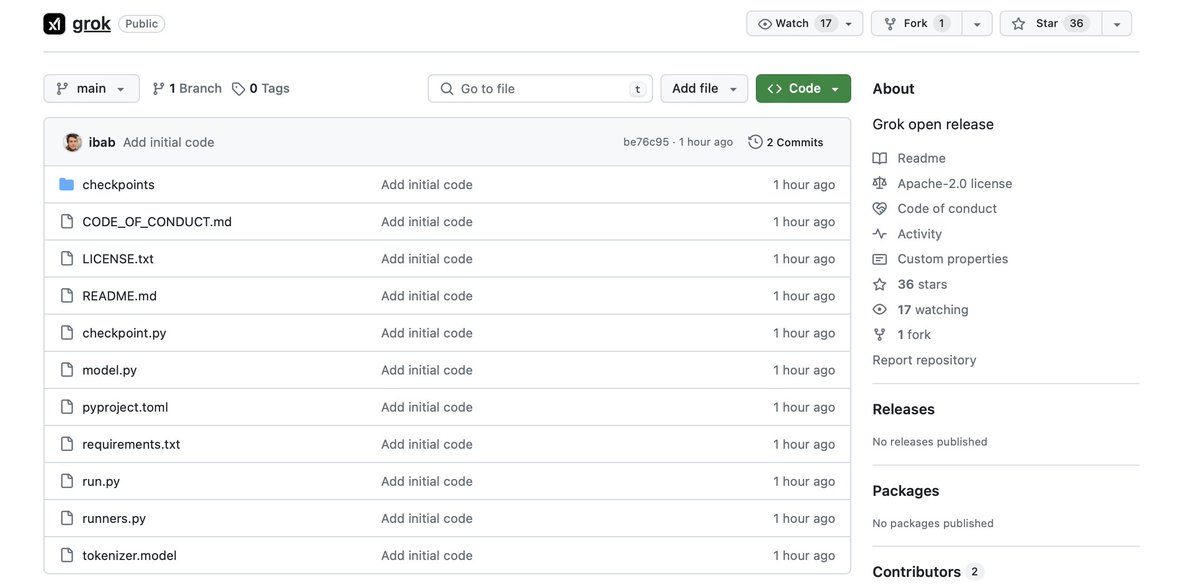
Nice, I hope this truly means open source, not just open weights. OLMo (arxiv.org/abs/2402.00838) was a great example of open sourcing, releasing - weights - training and inference code - data - evaluation - adaptation - logs

The Top ML Papers of the Week (March 11 - March 17): - SIMA - Multimodal LLM Pre-training - Knowledge Conflicts for LLMs - Retrieval Augmented Thoughts - LLMs Predict Neuroscience Results - LMs Can Teach Themselves to Think Before Speaking ...

A library of Machine Learning models for Stock price forecasting A mixture of Deep Learning, Reinforcement Learning and Stacked Models: - LSTM - Q-learning agent - Auto-Encoder + Gradient Boosting Get it here👇 github.com/huseinzol05/St…


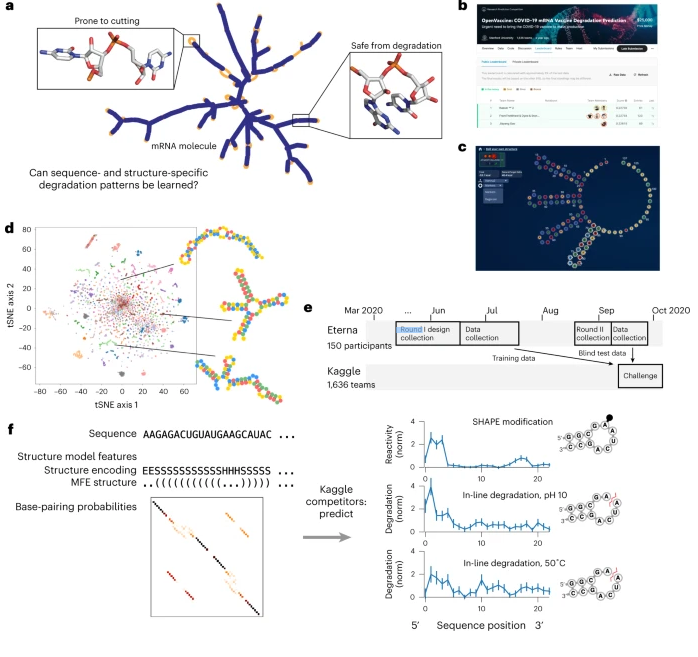
I am very pleased to announce that our paper "Deep learning models for predicting RNA degradation via dual crowdsourcing" has been published in Nature Machine Intelligence! 1/7

Today on the blog, we’re excited to announce the release of @MLCommons Croissant, a metadata format to make ML datasets more easily discoverable and usable across a wide array of tools and platforms. Learn more and try it today →goo.gle/4335P4V #ml #datasets


New short course: Open Source Models with Hugging Face 🤗, taught by @mariaKhalusova, @_marcsun, and Younes Belkada! @huggingface has been a game changer by letting you quickly grab any of hundreds of thousands of already-trained open source models to assemble into new…

I recorded a step-by-step tutorial on building a RAG application from scratch. It's a 1-hour YouTube video where I show you how to use Langchain, Pinecone, and OpenAI. You'll learn how to build a simple application to answer questions from YouTube videos using an LLM. But the…

Pytorch released GPT-fast!⚡️ This is a simple and efficient implementation of pytorch-native transformer text generation: Here are some key features: - Very low latency - <1000 lines of python - No dependencies other than PyTorch and sentencepiece - int8/int4 quantization -…

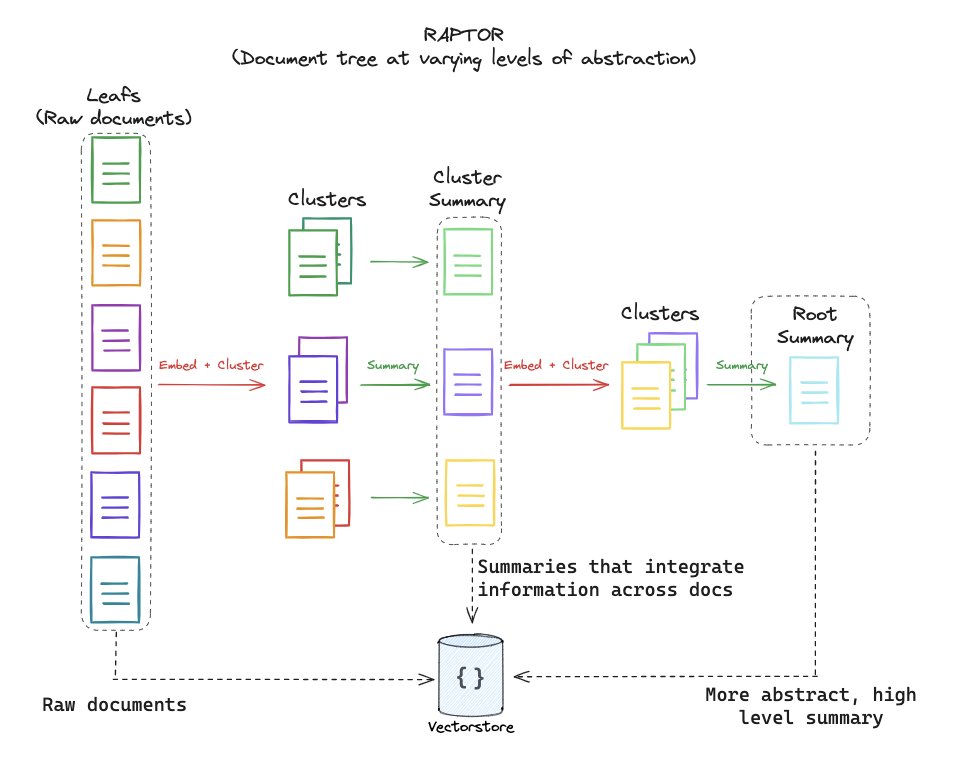
Building long context RAG from scratch with RAPTOR + Claude3 (Video) The rise of long context LLMs + embeddings will change RAG design. Instead of splitting docs + indexing doc chunks, it's feasible to index full docs. But, there is a challenge to flexibly answer lower-level…

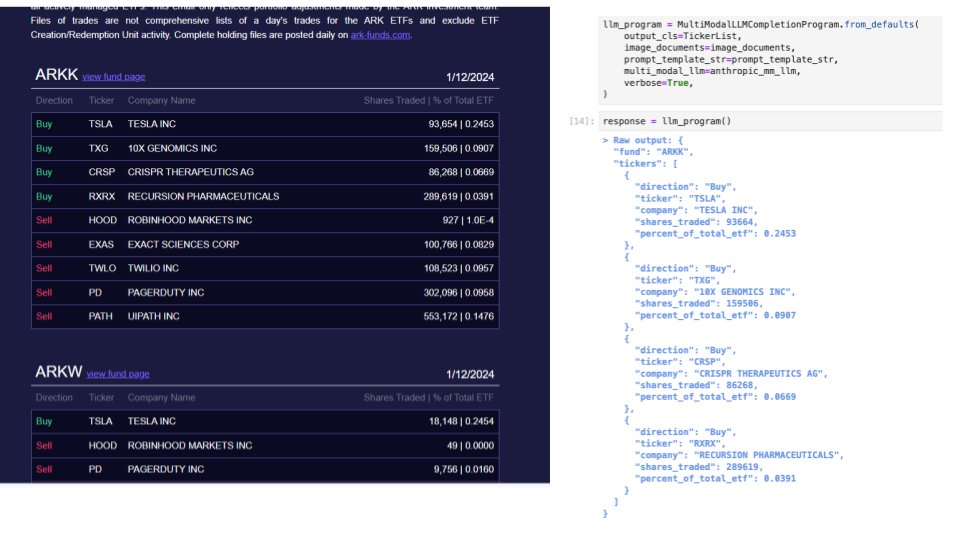
Claude 3 Multimodal Cookbook 🧑🍳 Claude is not only good at text, it is very good at visual reasoning. We’ve created a comprehensive guide to using Claude for various multi-modal applications: ✅ Structured Data Extraction ✅ RAG Claude 3 is able to extract an entire list of…
🏓Chain-of-Table This paper from Google proposes a new framework to do question answering over tabular data This framework involves a series of prompts, flows, and tool calling... perfect for LangGraph! s/o @HrubyOnRails for the implementation! Code: github.com/CYQIQ/MultiCoT













































































































United States 트렌드
- 1. Inside the NBA 3,811 posts
- 2. East Wing 153K posts
- 3. Hamburger Helper 1,879 posts
- 4. Wirtz 62.9K posts
- 5. $TSLA 48.5K posts
- 6. Elander 3,701 posts
- 7. Shaq 9,158 posts
- 8. Jashanpreet Singh 1,552 posts
- 9. 5sos 5,608 posts
- 10. Rosneft 6,222 posts
- 11. SNAP 664K posts
- 12. Charles Barkley N/A
- 13. Goodell 4,935 posts
- 14. Talus 16.5K posts
- 15. Danny White 3,182 posts
- 16. Tony Vitello 13.3K posts
- 17. Without the 2nd 1,028 posts
- 18. Fetterman 21.8K posts
- 19. Thimbles N/A
- 20. Surviving Mormonism N/A






Something went wrong.
Something went wrong.