
FunAI
@FunAILab
Research lab led by @y_m_asano at @utn_nuremberg. We conduct fundamental AI research and develop core technology for future Foundation Models.

@FunAILab + CVMP Lab of @EddyIlg retreat: ☑. From mountains to hackathon to good food, we've had some intense but good days with lots of new ideas 🎉.




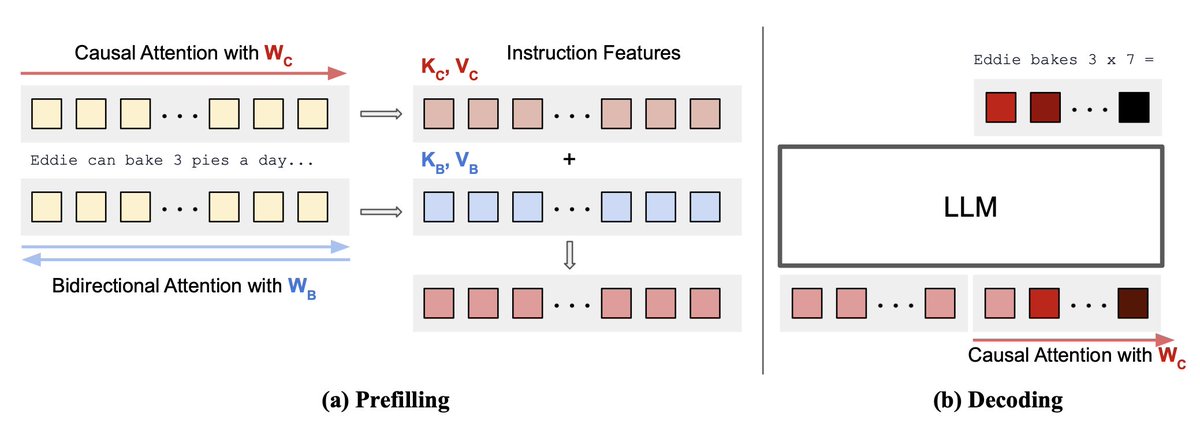
Now finally accepted at @emnlpmeeting! I think the technique and high-level ideas i) allow bidirectional attention for prompt & ii) (maybe) process input-query differently from answer generation will stick around.
Today we introduce Bidirectional Instruction Tuning (Bitune). It's a new way of adapting LLMs for the instruction->answering stage. It allows the model to process the instruction/question with bidirectional attention, while the answer generation remains causal.
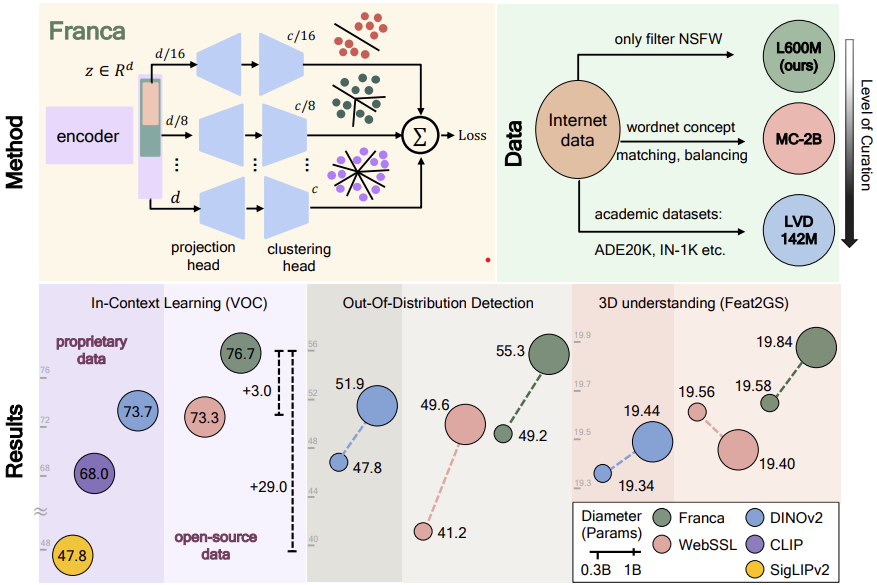
Today we release Franca, a new vision Foundation Model that matches and sometimes outperforms DINOv2. The data, the training code and the model weights (with intermediate checkpoints) are open-source, allowing everyone to build on this. Methodologically, we introduce two new…

Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research🧵

Hello FunAI Lab at UTN 👋 I’m excited to start a new chapter of my research journey here in Nuremberg as a visiting postdoc. Excited for inspiring collaborations and impactful research ahead with @y_m_asano and the amazing students😀


LoRA et al. enable personalised model generation and serving, which is crucial as finetuned models still outperform general ones in many tasks. However, serving a base model with many LoRAs is very inefficient! Now, there's a better way: enter Prompt Generation Networks,…

Is the community trying to surprise us today? 🤯 Because these benchmark-related papers from different research labs all dropped on the Daily Papers page at once! 🎉📑hf.co/papers ✨ LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal…

Today, we're introducing TVBench! 📹💬 Video-language evaluation is crucial, but are we doing it right? We find that current benchmarks fall short in testing temporal understanding. 🧵👇
First paper with our FunAI Lab affiliation :)
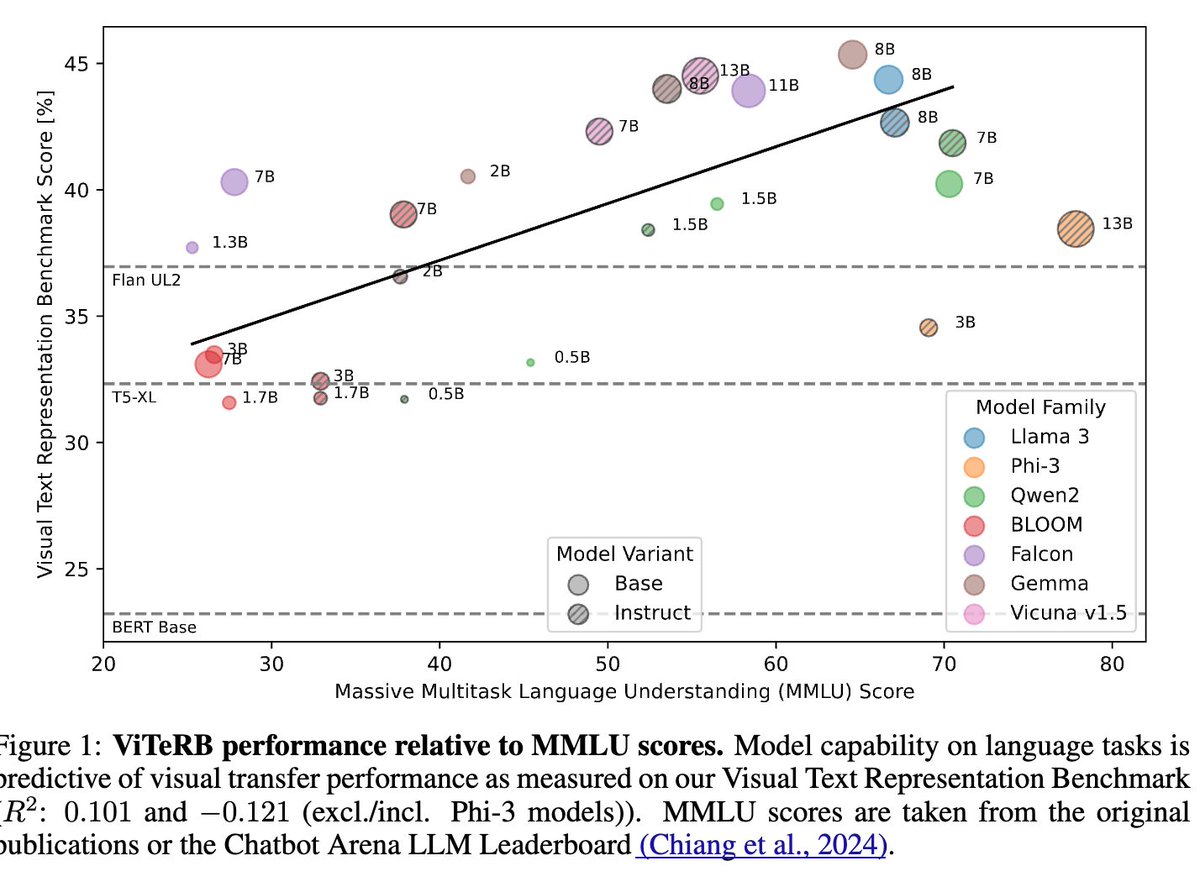
Ever wondered if better LLMs actually have a better understanding of the visual world? 🤔 As it turns out, they do! We find: An LLM's MMLU performance correlates positively with zero-shot performance in a CLIP-like case when using that LLM to encode the text. 🧵👇































































































United States Tendências
- 1. #TT_Telegram_sam11adel N/A
- 2. #hazbinhotelseason2 58.4K posts
- 3. Good Wednesday 19.7K posts
- 4. LeBron 87K posts
- 5. #hazbinhotelspoilers 3,636 posts
- 6. Peggy 20K posts
- 7. #DWTS 54.6K posts
- 8. #InternationalMensDay 25.1K posts
- 9. Baxter 2,303 posts
- 10. Kwara 180K posts
- 11. Dearborn 244K posts
- 12. Reaves 8,959 posts
- 13. Grayson 7,161 posts
- 14. Patrick Stump N/A
- 15. Whitney 16.4K posts
- 16. MC - 13 1,089 posts
- 17. Orioles 7,349 posts
- 18. Sewing 5,113 posts
- 19. Cory Mills 10.1K posts
- 20. Tatum 17.3K posts
Something went wrong.
Something went wrong.