
You might like
















> scaling UMI data to O(100k) hours with 10k hours of data added per week. > harmonic reasoning model that think & act jointly. > emerging behavior as model sizes scale. Very interesting work. More details please!

Introducing GEN-0, our latest 10B+ foundation model for robots ⏱️ built on Harmonic Reasoning, new architecture that can think & act seamlessly 📈 strong scaling laws: more pretraining & model size = better 🌍 unprecedented corpus of 270,000+ hrs of dexterous data Read more 👇

黄仁勋:“我一生最大的启发,来自于日本园丁” 在加工理工学院2024届毕业班的演讲 1. 一生只做一件大事:有足够的时间精雕细刻 祝大家找到自己的GPU,创建自己的英伟达! 2. 每天早晨先做完最重要的3件事: 甚至在动工之前,这天我已先赢了 (因为我有极其明确的优先次序)。 3.…

其实你还可以写得更长一些。 黄仁勋讲他有一次到日本京都一个公园去旅游,遇到一个修理苔藓的老人,这个老人说了一句话让他感觉醍醐灌顶,老人说的是我有的是时间,我已经干了25年了。 黄仁勋觉得英伟达也不外乎如是。 同理,穷人有的是时间。就算是日理万机的国家领导人,也有的是时间。…

💡From speculative decoding → to speculative verdict VLMs break when visuals get information-dense: charts, infographics, high-resolution complex images, etc. 📊 Like speculative decoding speeds up text gen by verifying fast drafts, our Speculative Verdict speeds up and…


How can Vision-Language Models (VLMs) reason over information-intensive images that densely interleave textual annotations with fine-grained graphical elements? 🤯 Introducing Speculative Verdict🎯 (SV), a training‑free, cost-efficient framework that synthesizes reasoning paths…


🚀 Thrilled to introduce Seed3D 1.0, a foundation model that generates High-Fidelity, Simulation-Ready 3D Assets directly from a Single Image! ✨ Key Capabilities: 1️⃣ High-fidelity Assets: Generates assets with accurate geometry, well-aligned textures, and physically-based…

This feature has finally been merged into the main branch. The team has been battling the PyTorch memory allocator and CUDA stream management for ages to iron out all the dependencies and race conditions.

⚡ Zero-overhead scheduler for speculative decoding ⚡ When your GPUs are running LLM inference, unoptimized software will waste a huge amount of time on CPU overhead - such as kernel launch and metadata bookkeeping. SGLang has been pioneering the zero-overhead CPU runtime for…


"Recent work like Barbarians at the Gate from Berkeley and demonstrations from Google’s AlphaEvolve show they can make a difference in a wider range of real-world problems from data center scheduling to AI training itself." 🙌

Wrote a 1-year retrospective with @a1zhang on KernelBench and the journey toward automated GPU/CUDA kernel generations! Since my labmates (@anneouyang, @simran_s_arora, @_williamhu) and I first started working towards this vision around last year’s @GPU_mode hackathon, we have…


我们团队开源了 Multi-Agent 强化学习的框架 MrlX,它能够让你同时训练多个 Agent 模型。 当我们试图让大模型变得更聪明时,大多数人都在做同样的事:训练一个模型,让它自己跟自己对话,希望它能学会反思验证,能学会使用工具。 但如果你仔细想想,这其实很奇怪。…




Launching MrlX: a multi-agent RL framework for LLM agents. It adopts asynchronous co-evolution—pairing an on-policy Adapter with an off-policy Adapter—to enable rapid, stable mutual improvement. Case studies (doctor-patient co-training; multi-agent research) show gains over…

💥Stop letting your GPUs nap while you pay full price. Check out kvcached, our first step toward a practical GPU "OS" for efficient, shared LLM serving. Proud collaboration between @BerkeleySky, @RiceUniversity, and @UCLA, with guidance from @istoica05 and @profjoeyg!! ❤️

🚀 End the GPU Cost Crisis Today!!! Headache with LLMs lock a whole GPU but leave capacity idle? Frustrated by your cluster's low utilization? We launch kvcached, the first library for elastic GPU sharing across LLMs. 🔗 github.com/ovg-project/kv… 🧵👇 Why it matters:


🤔 Can AI optimize the systems it runs on? 🚀 Introducing FlashInfer-Bench, a workflow that makes AI systems self-improving with agents: - Standardized signature for LLM serving kernels - Implement kernels with your preferred language - Benchmark them against real-world serving…



写了又删、删了又写的一段文字,想了想还是决定发出来。 杨振宁教授的成就,于社会、于民族、于吾等文明之贡献,在这里毋需篇章。漏夜不得昧时的一些思绪,在此写下,纪恩师杨振宁教授。 1938年,战火蔓延,山河动荡。我的太爷爷随校西迁昆明,在西南联大任教。…


🤯 We are releasing a ✨ robotics course ✨ on @huggingface -> huggingface.co/robotics-course Start the course *today* to learn: 🔴 The basics of classical robotics 🔴 RL for real-world robots 🔴 Generative models for imitation learning 🔴 The latest in generalist Robot Policies

杨振宁先生今日中午仙逝,享年103岁 他是在青少年成长路径和学习方法上给我最大启发的创造力大师,他深谙中国和美国教育的差异和各自长短,对于培养前沿人才(不仅仅是科学家)有极深的洞见。 昨晚22:28还有推友说他走了,我核查看到饶毅否认 没想到刚才看到新闻。 强烈推荐关于他的两本传记…

杨振宁:直觉先于逻辑 不断地修正自己的逻辑,你就能成为顶级高手 杨振宁先生多次强调过直觉在科学探索中的先导作用, 他提出,直觉和灵感这类非逻辑思维的"触角可以伸得非常远",往往在没完全看清时就抓住了其精神。 这种对物理现象的直觉感知和洞察力, 是推动科学创造的重要力量。 Susan警句:…


WorldVLA: Towards Autoregressive Action World Model Paper: arxiv.org/abs/2506.21539 Code: github.com/alibaba-damo-a… Work from Alibaba to integrate VLA model and world model into one single autoregressive framework. The resulting action world model can predict both future images…
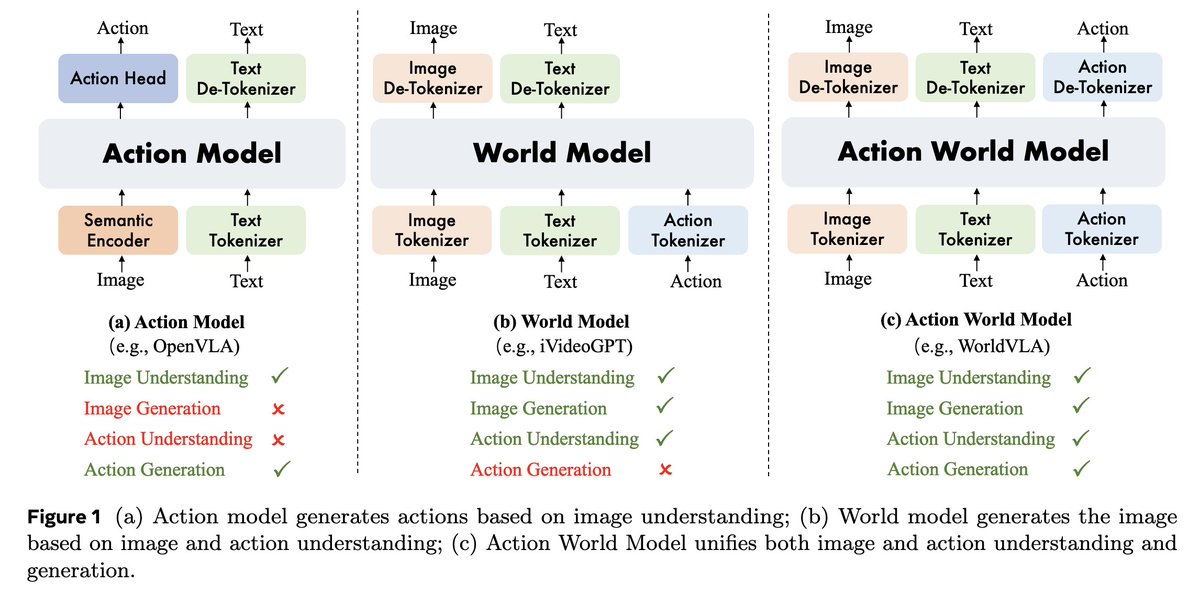
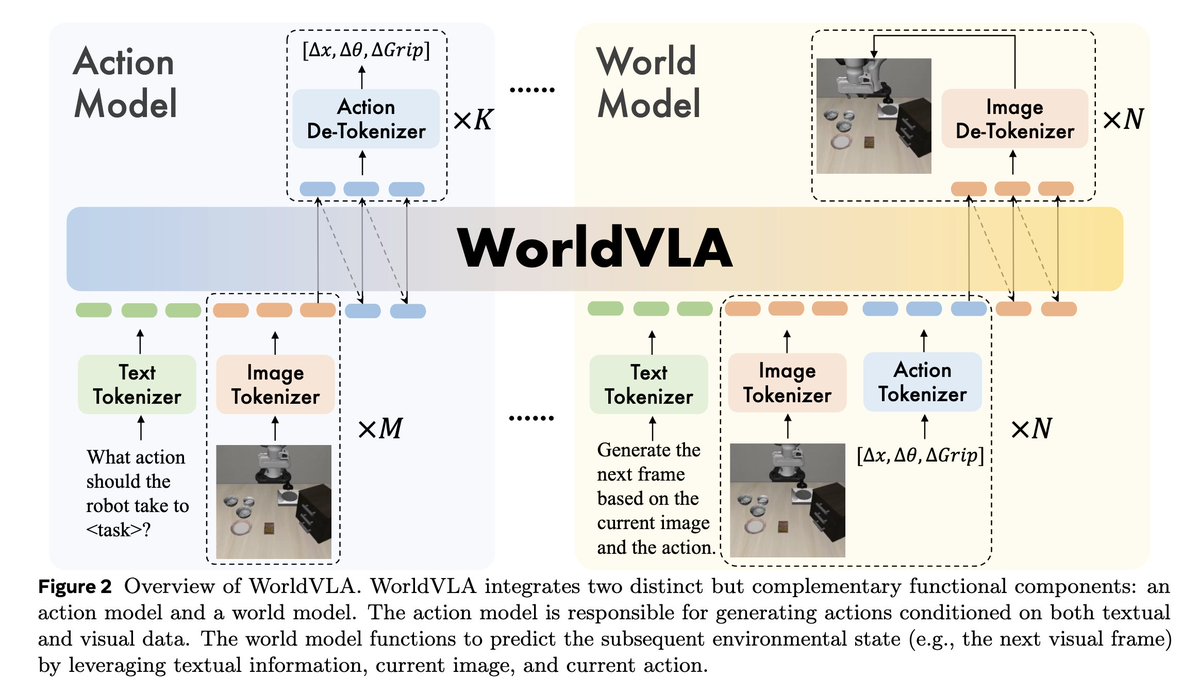

Awesome project by jinhui! Bridging from Qwen-VL to classic VLA models!

We are pleased to share a solution for quickly building many classic VLA architectures on Qwen2.5-VL and Qwen3-VL. It currently supports Qwen + FAST, Qwen + OFT, Qwen + PI, and Qwen + GR00T, and the results show great potential. Follow the project here github.com/starVLA/starVLA





"真正的进步,不在于你记住了多少知识,而在于你的直觉发生了怎样的变化。" ——杨振宁 Intuition is Knowledge Distillation 直觉,就是知识蒸馏 系统二对某类问题的深度思考,经过反复训练,最终被"蒸馏"内化成系统一的快速反应——从费力推理,变成瞬间"看出"答案。…


Wow, what an extraordinary tribute. Goodbye and Godspeed Professor Yang 🕊️

The passing of the physicist Chen-Ning Yang (nytimes.com/2025/10/18/sci…) saddens me. He has been a long-time hero and role model for me. Below is a short essay I wrote yesterday about Yang that I shared with many of my friends. I translated it into English using Gemini: ``` The…





40 分钟到50分钟,华彩,RL is terrible。 太好了!

The @karpathy interview 0:00:00 – AGI is still a decade away 0:30:33 – LLM cognitive deficits 0:40:53 – RL is terrible 0:50:26 – How do humans learn? 1:07:13 – AGI will blend into 2% GDP growth 1:18:24 – ASI 1:33:38 – Evolution of intelligence & culture 1:43:43 - Why self…

Prof. Chen Ning Yang, a world-renowned physicist, Nobel Laureate in Physics, Academician of the Chinese Academy of Sciences, Professor at Tsinghua University, and Honorary Director of the Institute for Advanced Study at Tsinghua University, passed away in Beijing due to illness…


Do you really need RL/verifiers/CoT to unlock reasoning in language models? Excited to share our new work showing how test-time sampling on the base language distribution enables us to get the same performance as GRPO! No training needed and works on non-verifiable domains!

We found a new way to get language models to reason. 🤯 No RL, no training, no verifiers, no prompting. ❌ With better sampling, base models can achieve single-shot reasoning on par with (or better than!) GRPO while avoiding its characteristic loss in generation diversity.

























































































United States Trends
- 1. Broncos 28.7K posts
- 2. Raiders 40K posts
- 3. #911onABC 19.4K posts
- 4. GTA 6 80.1K posts
- 5. AJ Cole N/A
- 6. eddie 40.9K posts
- 7. #WickedOneWonderfulNight 1,919 posts
- 8. Bo Nix 5,345 posts
- 9. #TNFonPrime 2,435 posts
- 10. Ravi 15K posts
- 11. Cynthia 32.9K posts
- 12. tim minear 2,059 posts
- 13. #RaiderNation 2,357 posts
- 14. Al Michaels N/A
- 15. GTA VI 27.6K posts
- 16. Rockstar 63.2K posts
- 17. Chip Kelly N/A
- 18. Jeanty 3,945 posts
- 19. Geno Smith 1,407 posts
- 20. IDINA 1,677 posts
You might like
-
 Yuxuan Jiang
Yuxuan Jiang
@_MattJiang_ -
 Xinyu Yang
Xinyu Yang
@Xinyu2ML -
 Yichuan Wang
Yichuan Wang
@YichuanM -
 Muyang Li
Muyang Li
@lmxyy1999 -
 youming.deng
youming.deng
@denghilbert -
 xyjixyjixyji
xyjixyjixyji
@jxyintheflesh -
 Seer_Eeyore
Seer_Eeyore
@EeyoreSeer -
 Xudong Sun
Xudong Sun
@xu_dong_sun -
 xuefen
xuefen
@xuefen19 -
 Lei Wang
Lei Wang
@Lei_Wang_1999 -
 WANGZINING
WANGZINING
@wznmickey -
 Ikumisaurus Rex
Ikumisaurus Rex
@LaithozBit -
 sher
sher
@Sher202364 -
 Zhuohao Li
Zhuohao Li
@garricklzh -
 crisps
crisps
@crisps14761463
Something went wrong.
Something went wrong.