
Lianmin Zheng
@lm_zheng
Member of technical staff @xAI | Prev: Ph.D. @UCBerkeley, Co-founder @lmsysorg
Вам может понравиться
















(1/N) 🚀 We converted a high quality Wan2.2-MoE into an autoregressive model. Preview checkpoint: huggingface.co/FastVideo/Caus… - First autoregressive version of Wan2.2-A14B MoE - I2V compatible - 8-step distilled - Potential backbone for streaming generation and world modeling Try…


🚀 Introducing Miles — an enterprise-facing RL framework for large-scale MoE training & production, forked from slime. Slime is a lightweight, customizable RL framework that already powers real post-training pipelines and large MoE runs. Miles builds on slime but focuses on new…
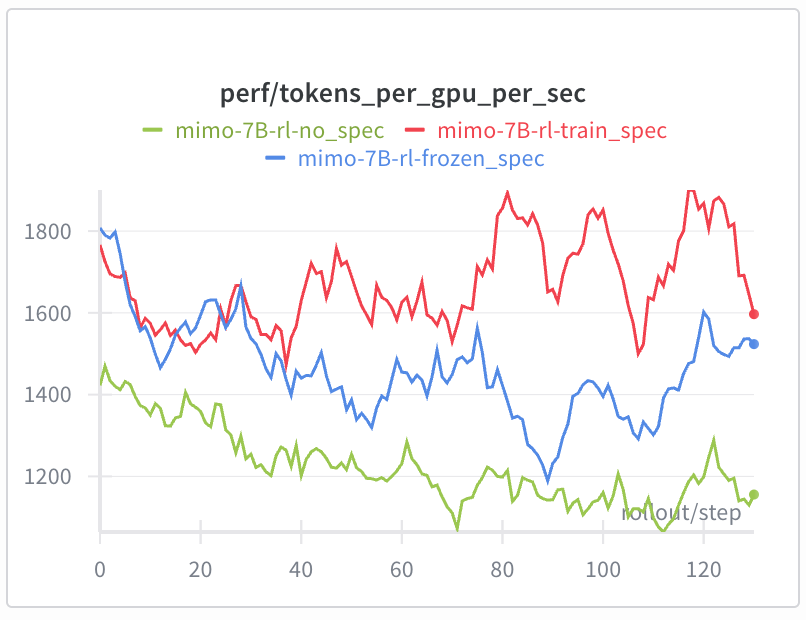
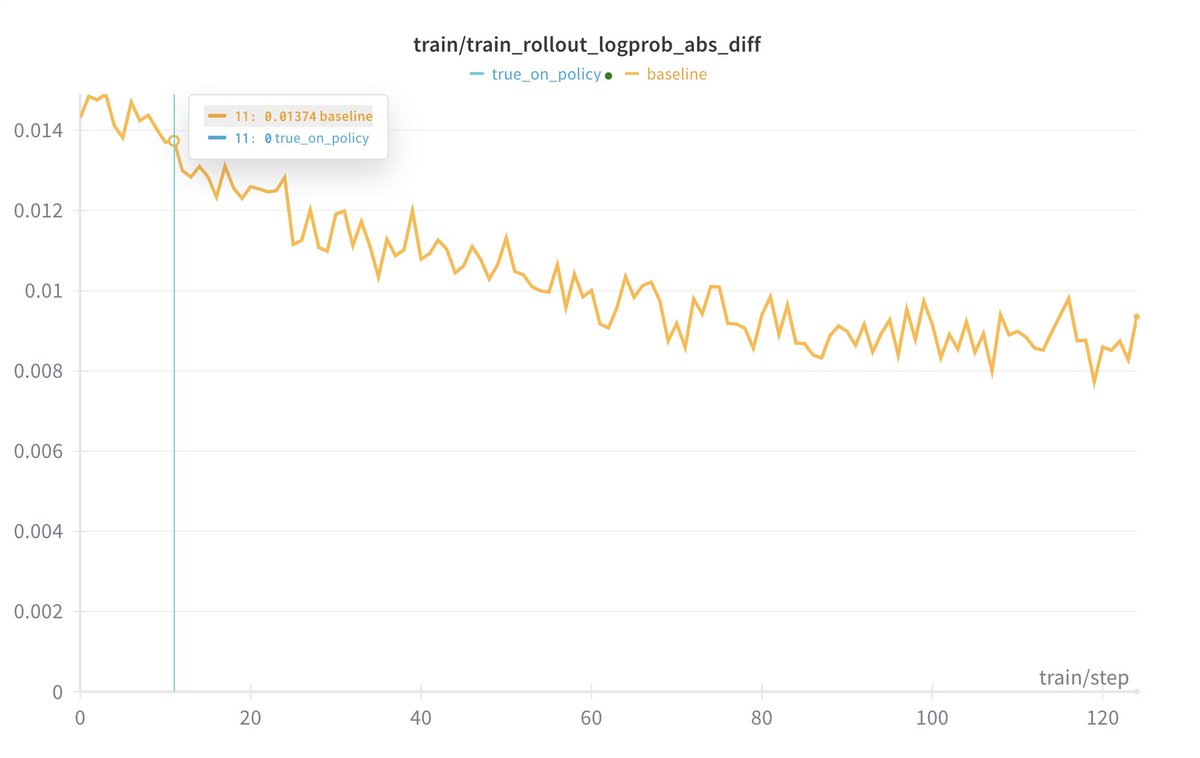


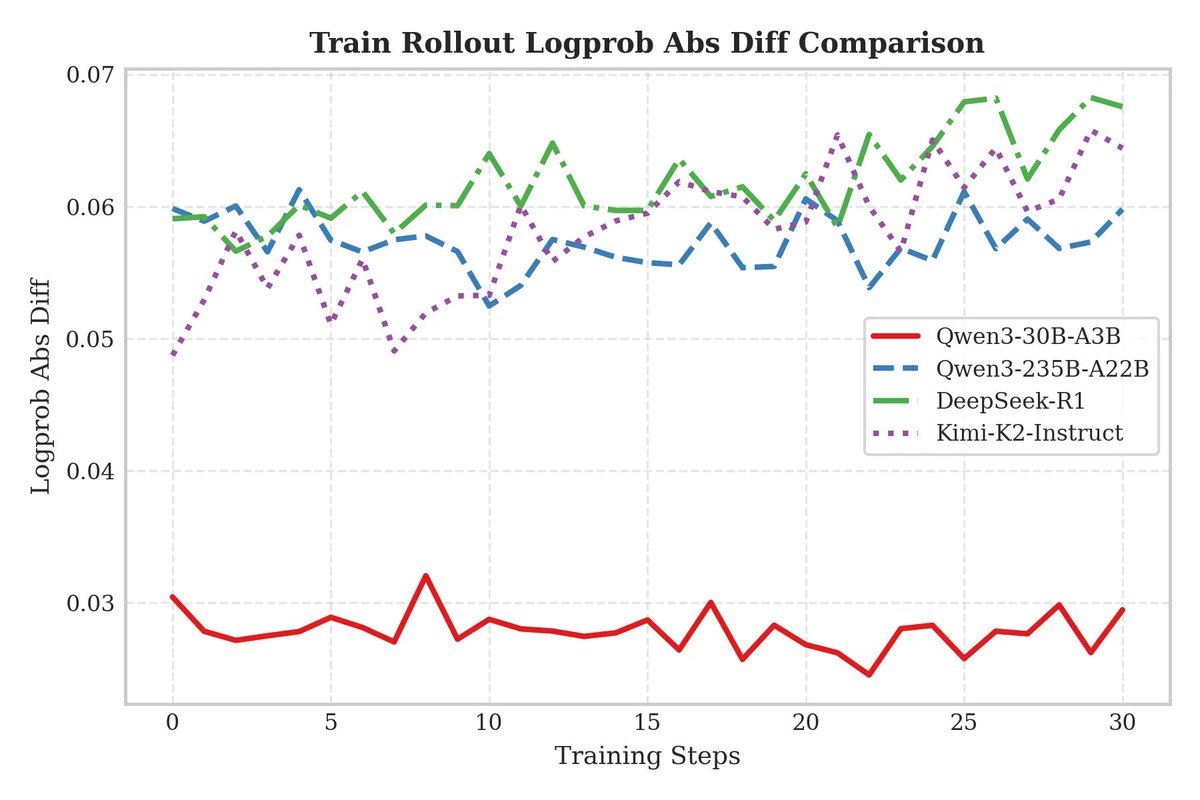
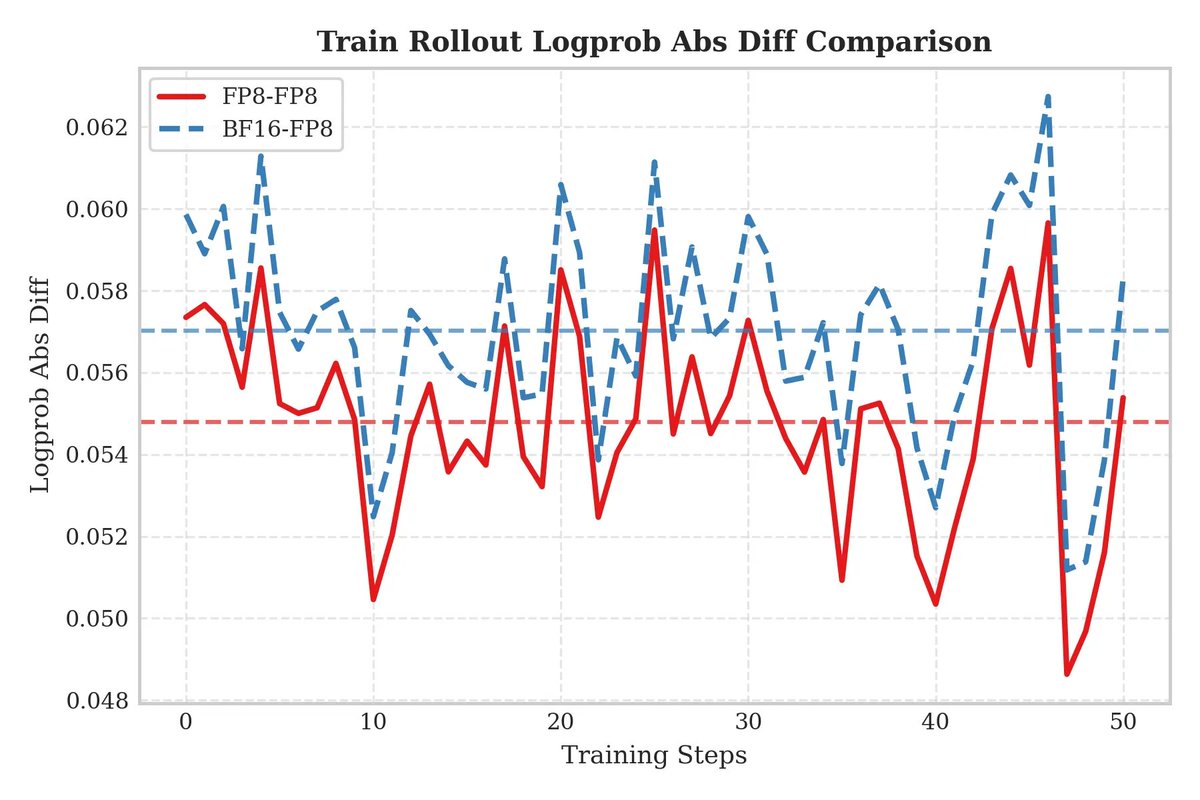
We have implemented unified FP8 RL. FP8 for both training and rollout effectively eliminates train–inference inconsistency caused by quantization error, improving both the speed and stability of RL training.
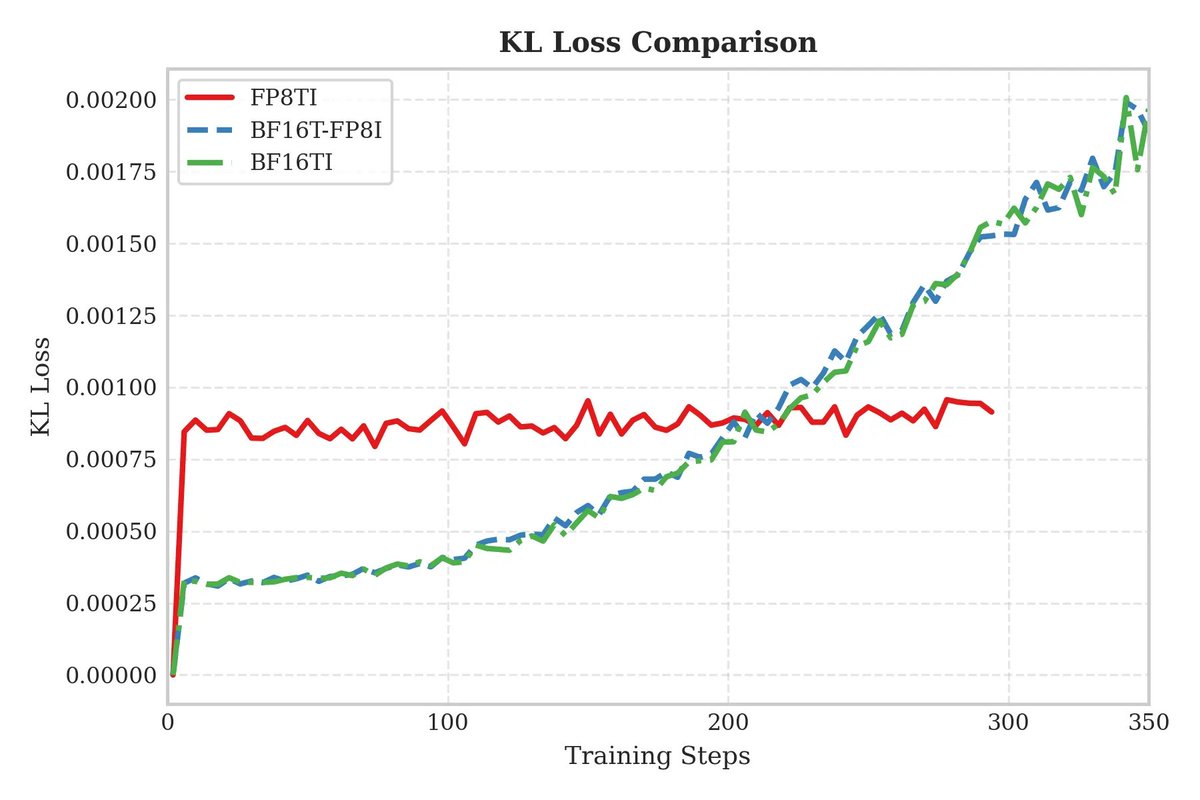
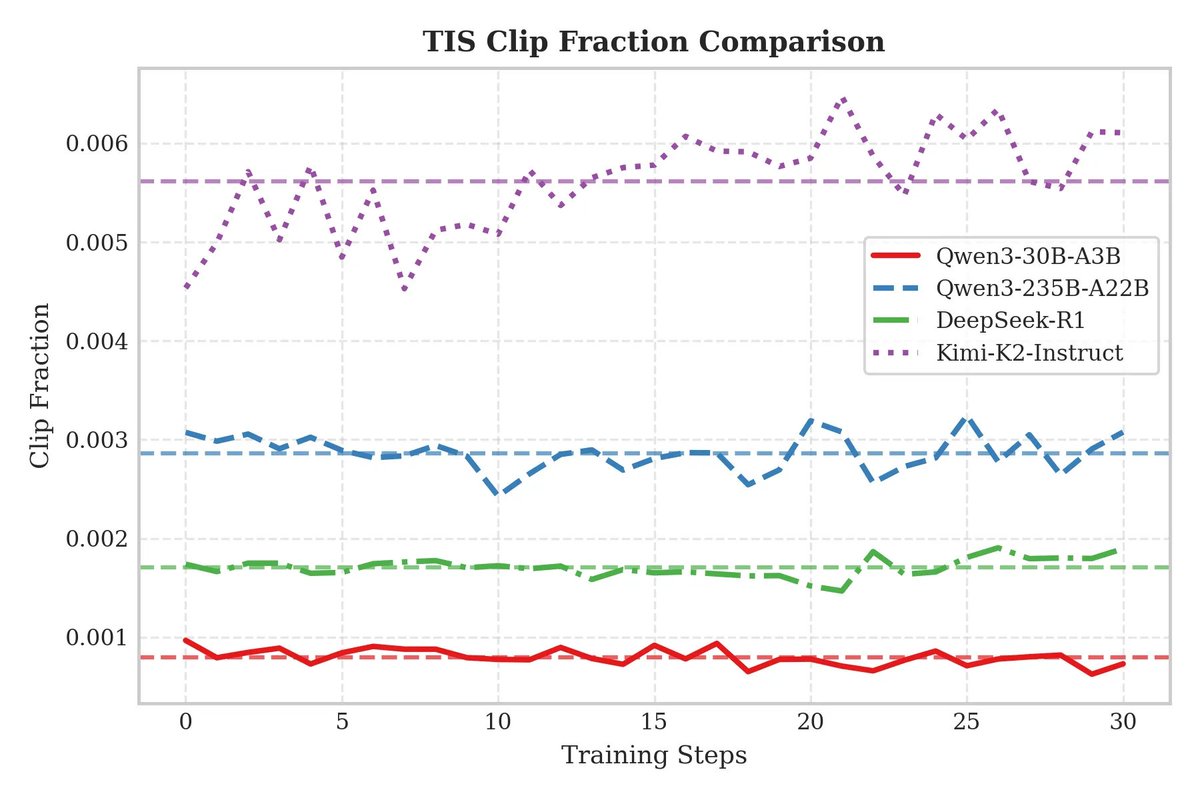
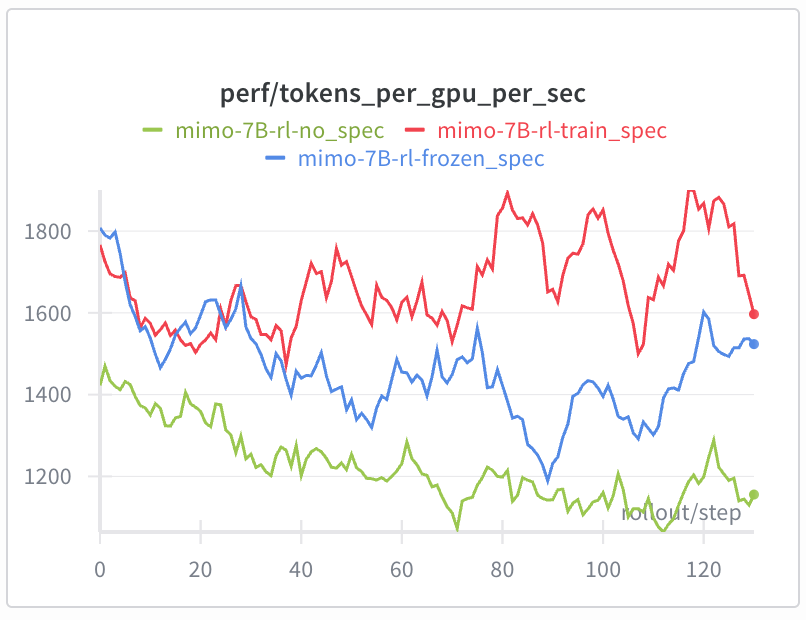
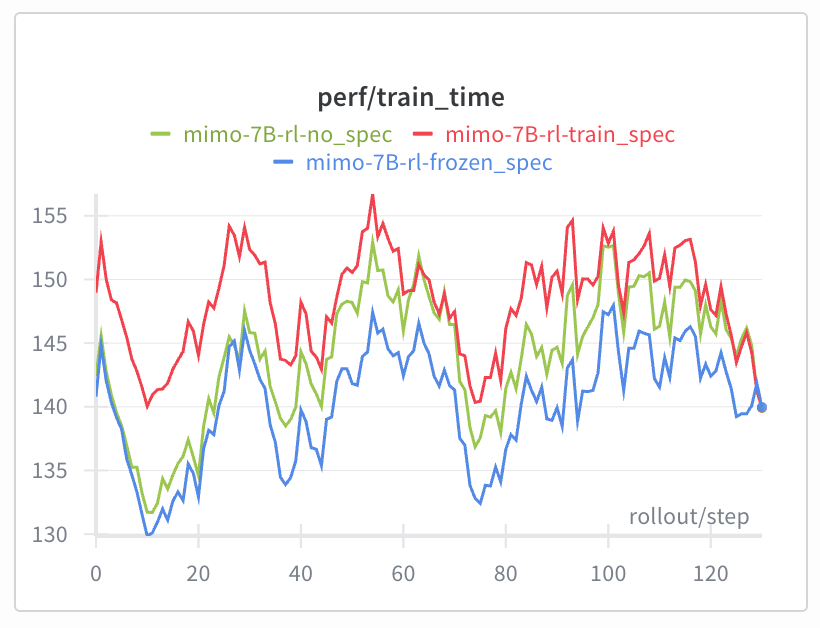
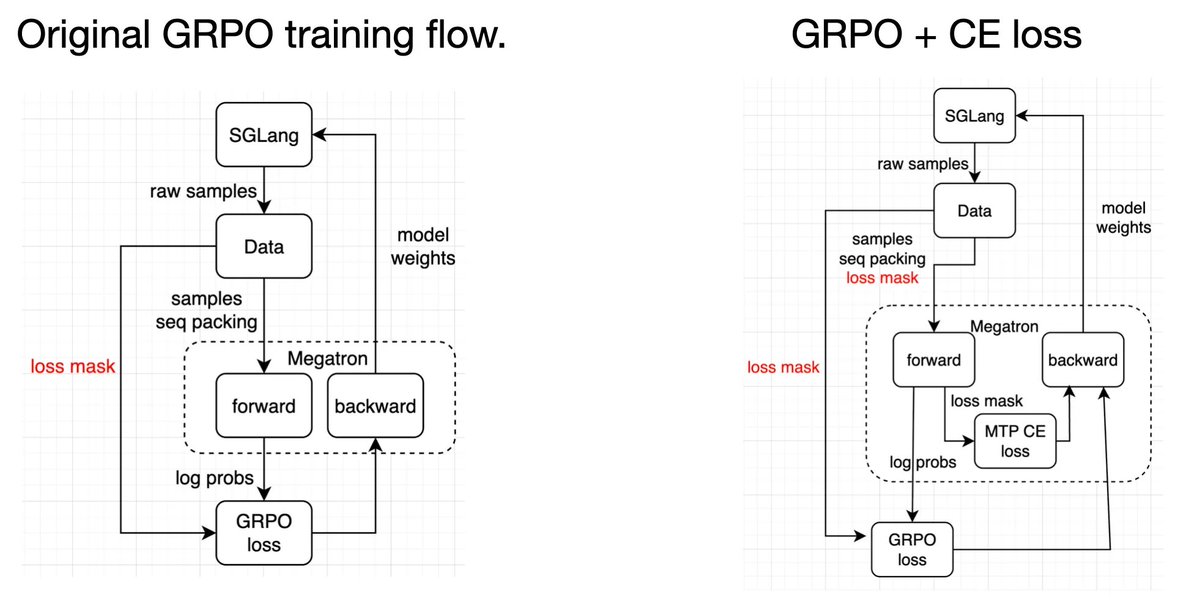
We conducted additional experiments to compare speculative training with frozen MTP layers and obtained solid results. Further experiments are being conducted on larger-scale (300B+) MOEs, looking forward!
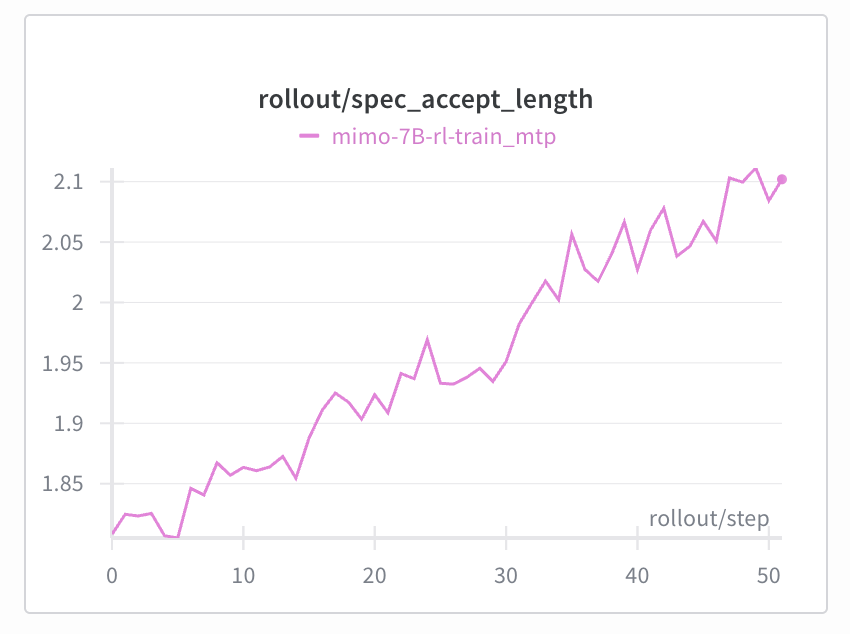
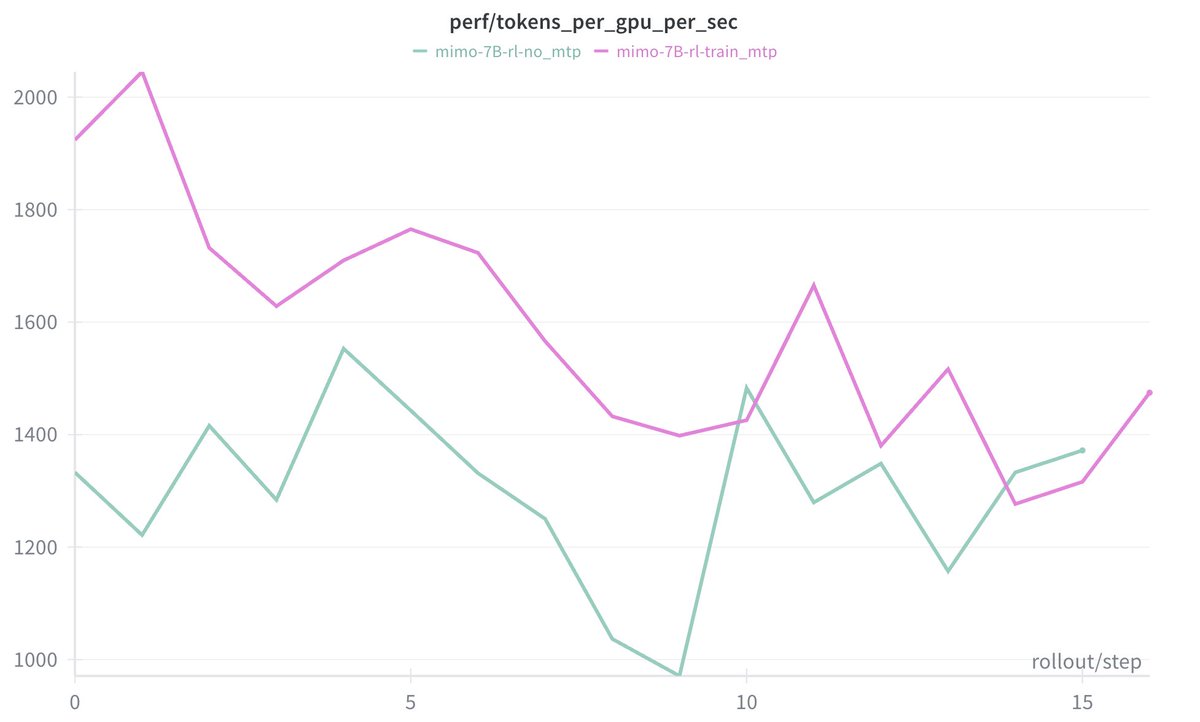
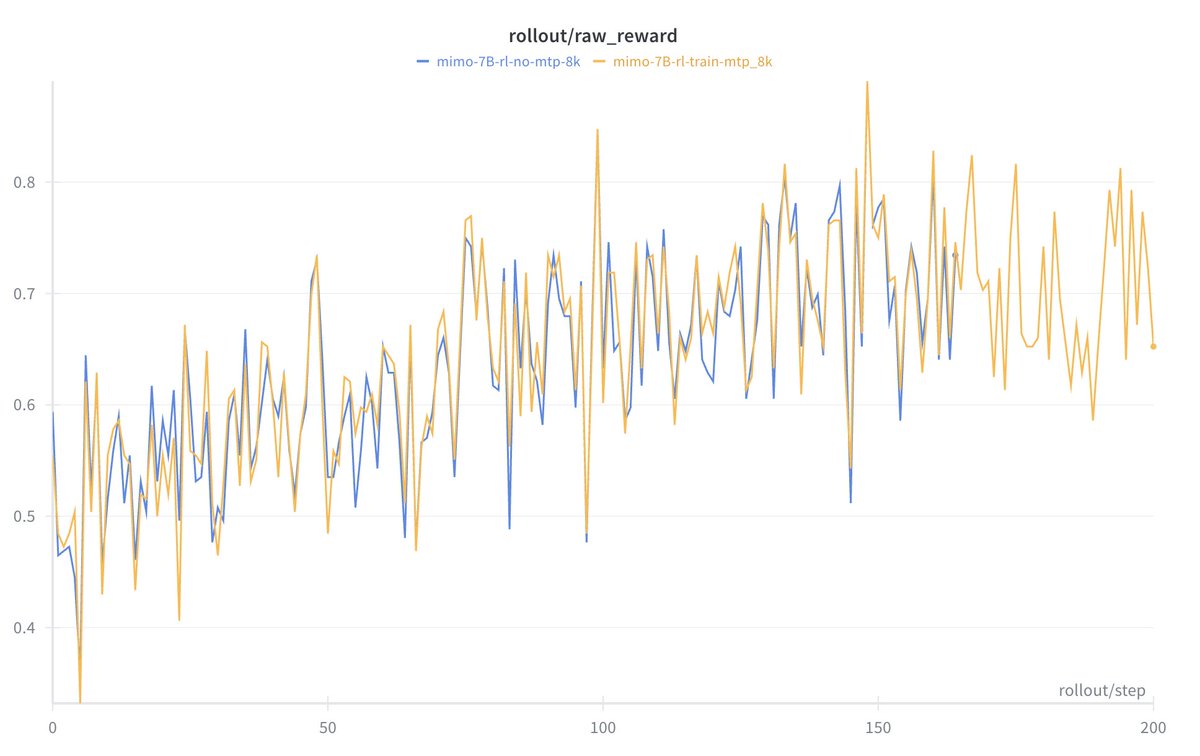
We introduce speculative decoding into the RL sampling process, achieving a significant improvement in sampling speed under appropriate batch sizes. Compared to freezing the draft model, the accepted length maintain at a high level, generating long-term stable positive gains.

Grok 4.1 just released. You should notice a significant increase in speed and quality.

Introducing Grok 4.1, a frontier model that sets a new standard for conversational intelligence, emotional understanding, and real-world helpfulness. Grok 4.1 is available for free on grok.com, grok.x.com and our mobile apps. x.ai/news/grok-4-1

Grok 4.1 is out! Amazing improvements.
Introducing Grok 4.1, a frontier model that sets a new standard for conversational intelligence, emotional understanding, and real-world helpfulness. Grok 4.1 is available for free on grok.com, grok.x.com and our mobile apps. x.ai/news/grok-4-1
Numeric debugging is extremely challenging given the huge number of kernels in today’s training and inference systems. You can’t get a single kernel wrong. This is a great engineering achievement and will hopefully make RL training and debugging much easier.
💥 We've achieved perfect training-inference alignment for SGLang & FSDP in slime! (Flash Attn 3, DeepGEMM, etc.) The result? A strict KL divergence of 0. But here's the twist: We spent a month trying to find a baseline that crashes from mismatch... and couldn't. 🤷♂️ We haven't…




💥 We've achieved perfect training-inference alignment for SGLang & FSDP in slime! (Flash Attn 3, DeepGEMM, etc.) The result? A strict KL divergence of 0. But here's the twist: We spent a month trying to find a baseline that crashes from mismatch... and couldn't. 🤷♂️ We haven't…
Proud to power Kimi K2 Thinking with SGLang on Atlas Cloud!

🚀 Kimi K2 Thinking is live on Atlas Cloud — deployed with @lmsysorg for production‑grade, low‑latency inference. Big thanks @Kimi_Moonshot. Try it → atlascloud.ai/models/moonsho… #AtlasCloud #KimiK2 #SGLang
atlascloud.ai
Kimi-K2-Thinking Text Model API by MOONSHOTAI | Atlas Cloud - 200+ AI Models Platform
Deploy Kimi-K2-Thinking instantly with Atlas Cloud's unified API platform. Get competitive pricing, serverless endpoints, and 99.99% uptime.
Great progress!

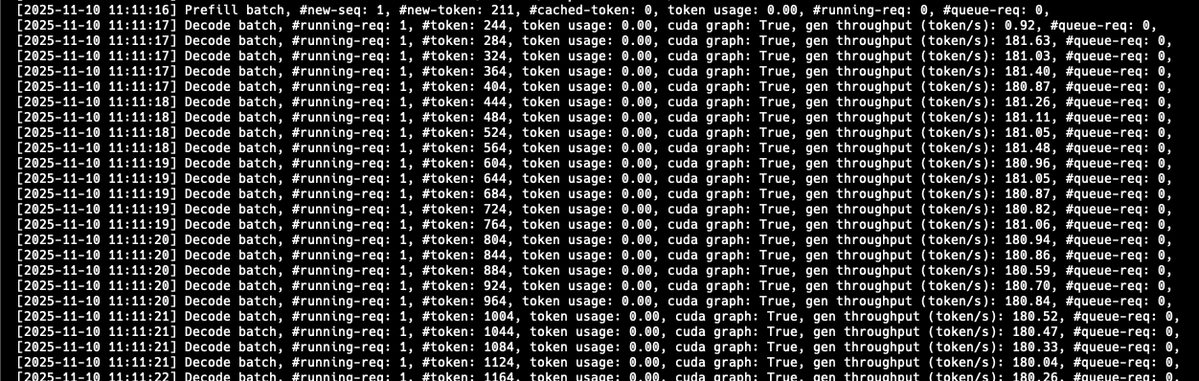
insane blackwell progress in v0.5.5 by the sglang team. with new optimizations, it's stable like hopper and the performance is great even for multimodal models 181 tokens/s on Qwen3-VL-30B-A3B-Thinking on 1x B200:
Hao has been pioneering efficient architecture research for many years. Always eager to see the innovations from him and his group!
Excited to partner with SGLang: FastVideo + SGLang = the future open ecosystem for diffusion. 🥳🫡 ----------- A few extra cents: Since I started faculty at UCSD, our lab has been investing diffusion for video and text , and in both algorithms and systems. - Text-side, we…
Great progress!

Ant AQ-Team @AQ_MedAI @TheInclusionAI and SGLang RL Team @sgl_project just helped land Kimi-K2-Instruct RL on slime — fully wired up and running on 256× H20 141GB 🚀 Huge shout-out to @yngao016, @menlzy, @Yonah_x from AQ Team and @Ji_Li_233, @Yefei_RL from the SGLang RL Team for…

🚀 Introducing SGLang Diffusion — bringing SGLang’s high-performance serving to diffusion models. ⚡️ Up to 5.9× faster inference 🧩 Supports major open-source models: Wan, Hunyuan, Qwen-Image, Qwen-Image-Edit, Flux 🧰 Easy to use via OpenAI-compatible API, CLI & Python API…




Future models will be multi modal in multi modal out, potentially combining auto regressive and diffusion architectures. SGLang project takes the first step towards building a unified inference stack for all.
🚀 Introducing SGLang Diffusion — bringing SGLang’s high-performance serving to diffusion models. ⚡️ Up to 5.9× faster inference 🧩 Supports major open-source models: Wan, Hunyuan, Qwen-Image, Qwen-Image-Edit, Flux 🧰 Easy to use via OpenAI-compatible API, CLI & Python API…
Day-0 support for Kimi K2 Thinking on SGLang ⚡ The new open-source thinking-agent model pushes reasoning, coding, and multi-step tool use to new heights. Proud to collaborate with @Kimi_Moonshot to make it run seamlessly: python -m sglang.launch_server \ --model-path…


🚀 Hello, Kimi K2 Thinking! The Open-Source Thinking Agent Model is here. 🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%) 🔹 Executes up to 200 – 300 sequential tool calls without human interference 🔹 Excels in reasoning, agentic search, and coding 🔹 256K context window Built…


Awesome step to support native JAX inference from sglang! Now we don't need any torch layer to land code directly on TPU. @SingularMattrix
SGLang now has a pure Jax backend, and it runs natively on TPU!
SGLang now runs natively on TPU with a new pure Jax backend! SGLang-Jax leverages SGLang's high-performance server architecture and uses Jax to compile the model's forward pass. By combining SGLang and Jax, it delivers fast, native TPU inference while maintaining support for…

Exciting to see Glyph open-sourced -- exploring a direction similar to DeepSeek-OCR, using visual-text compression to scale context windows! Instead of reading text token by token, Glyph lets models see the text, achieving 3–4× compression while preserving strong performance,…

Glyph: Scaling Context Windows via Visual-Text Compression Paper: arxiv.org/abs/2510.17800 Weights: huggingface.co/zai-org/Glyph Repo: github.com/thu-coai/Glyph Glyph is a framework for scaling the context length through visual-text compression. It renders long textual sequences into…


FYI, our SGLang fork is public here: github.com/chutesai/sglang (branch chutes) to boost your SGLang perf from 73% to 97% 👀 When I tested a few manually there were a few discrepancies where instead of generating a string it generated an array of strings, etc.; curious if switching…
Kimi K2vv updated! We've added case-by-case statistics for ToolCall-Trigger Similarity and ToolCall-Schema Accuracy. Feedback is welcome! github.com/MoonshotAI/K2-…

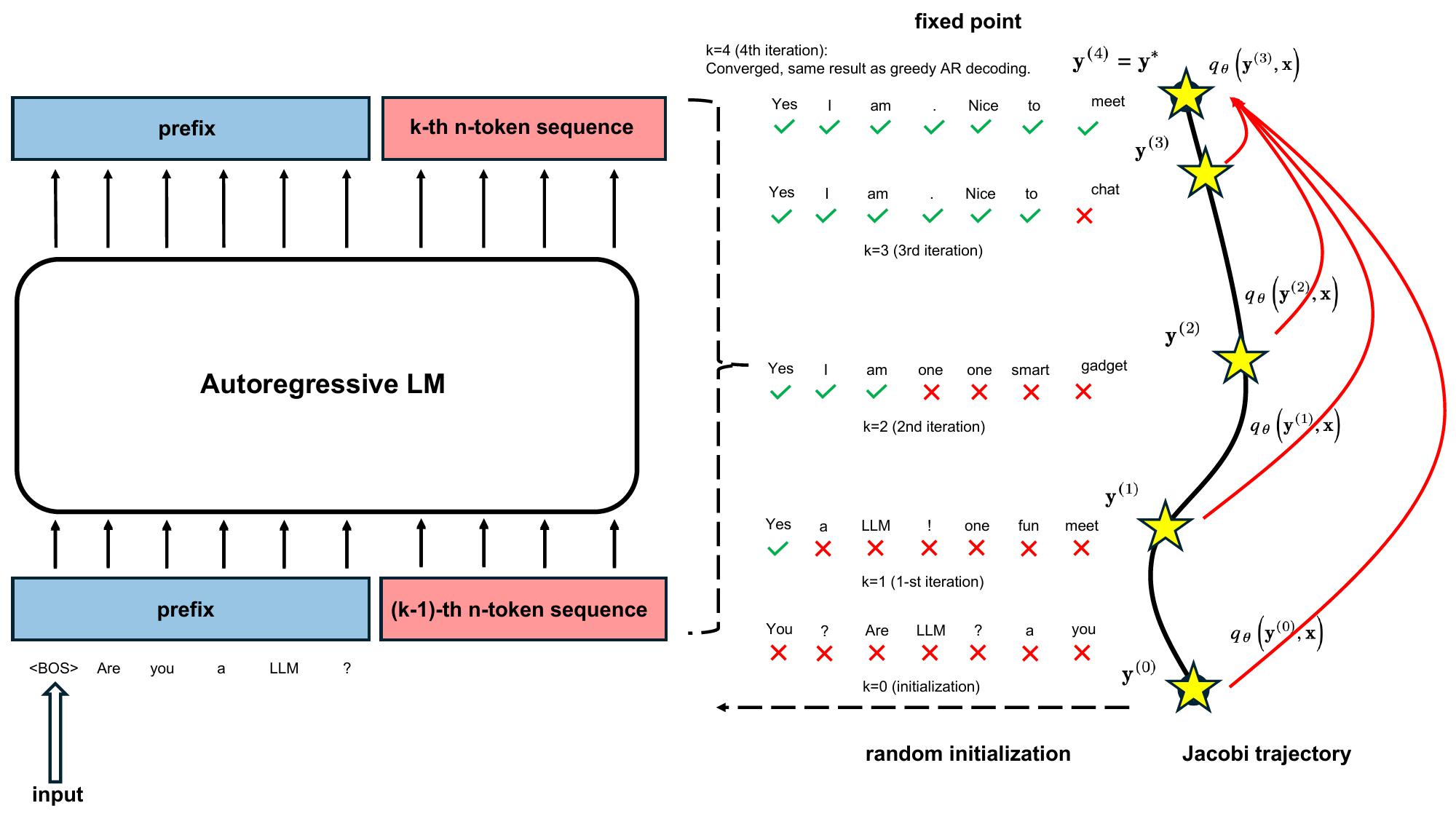
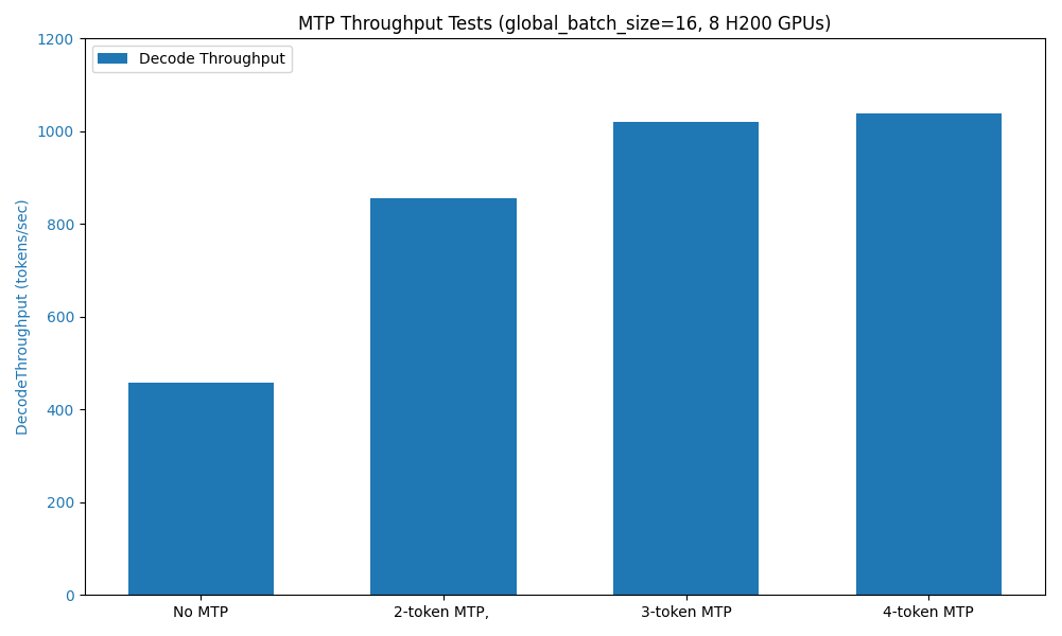
This huge contribution from @Baidu_Inc team enabled multi token prediction for Spare attention, achieving more than 2x decoding throughput improvements for the latest DeepSeek v3.2 models. The new architecture makes inference more interesting—we need to carefully handle the…





















































































































United States Тренды
- 1. Good Friday 47.4K posts
- 2. LINGORM DIOR AT MACAU 317K posts
- 3. #ElMundoConVenezuela 1,649 posts
- 4. #TheWorldWithVenezuela 1,645 posts
- 5. #FridayVibes 3,479 posts
- 6. #GenshinSpecialProgram 14K posts
- 7. #FridayFeeling 1,830 posts
- 8. Josh Allen 42.7K posts
- 9. RED Friday 1,878 posts
- 10. Happy Friyay N/A
- 11. Texans 62.1K posts
- 12. Parisian 1,473 posts
- 13. Bills 155K posts
- 14. Ja Rule N/A
- 15. Sedition 329K posts
- 16. Niger 58.3K posts
- 17. namjoon 64.9K posts
- 18. Cole Palmer 15.2K posts
- 19. Beane 3,113 posts
- 20. Traitor 119K posts
Вам может понравиться
-
 Zhuohan Li
Zhuohan Li
@zhuohan123 -
 Tri Dao
Tri Dao
@tri_dao -
 SkyPilot
SkyPilot
@skypilot_org -
 Hao Zhang
Hao Zhang
@haozhangml -
 Joey Gonzalez
Joey Gonzalez
@profjoeyg -
 Woosuk Kwon
Woosuk Kwon
@woosuk_k -
 Shishir Patil
Shishir Patil
@shishirpatil_ -
 Ying Sheng
Ying Sheng
@ying11231 -
 Zhanghao Wu
Zhanghao Wu
@Michaelvll1 -
 Tianqi Chen
Tianqi Chen
@tqchenml -
 Dacheng Li
Dacheng Li
@DachengLi177 -
 Wei-Lin Chiang
Wei-Lin Chiang
@infwinston -
 Ryan Hanrui Wang
Ryan Hanrui Wang
@hanrui_w -
 Muyang Li
Muyang Li
@lmxyy1999 -
 Beidi Chen
Beidi Chen
@BeidiChen
Something went wrong.
Something went wrong.