
Free Z-Image API is live! 🎉 The open-source Z-Image Turbo model is now 100% free to call via API on ModelScope🔥 AND Free compute included!!! ✨ How to use it: 1️⃣ Try it instantly: Go to 👉modelscope.cn/aigc/imageGene… Z-Image is the default model! - Quick Mode: Fast results, zero…
🚀 🚀 Qwen3-VL Tech Report is now publicly available!! 📄 Paper: modelscope.cn/papers/2511.21… From pretraining to post-training, architecture to infrastructure, data curation to evaluation — Qwen team documented the full journey to empower open-source builders working on…

🔥 Huge win for the Qwen team! Their paper on Gated Attention just won a NeurIPS 2025 Best Paper Award! 🏆 📄 Paper: modelscope.cn/papers/2505.06… They found that slapping a tiny sigmoid gate after each attention head—think of it as a smart “regulator” for LLMs—makes models sharper,…

🚀Bytedance-Research just dropped: VeAgentBench — a new benchmark dataset to evaluate real-world agentic capabilities! ✅ 145 open Qs (484 total) across legal, finance, edu & personal assistant ✅ Tests tool use, RAG, memory & multi-step reasoning ✅ Comes with runnable agents…

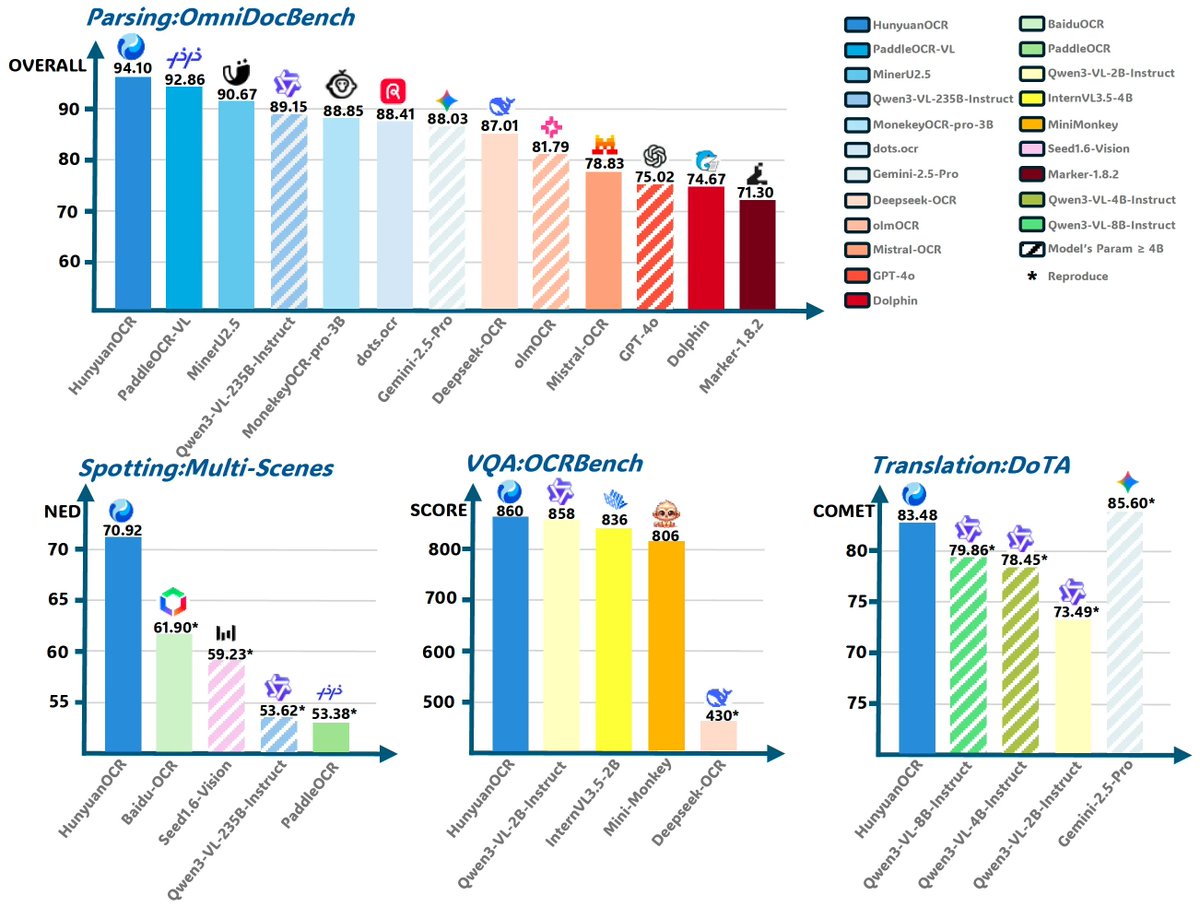
🔥 @TencentHunyuan just open-sourced HunyuanOCR — a 1B-parameter, end-to-end multimodal OCR model that beats Gemini, Qwen-VL, and commercial APIs across 10+ benchmarks. ✅ SOTA on OmniDocBench (94.1!) ✅ Full document parsing: LaTeX formulas, HTML tables, reading-order Markdown…




CNBC explores how Alibaba Cloud powers the next wave of AI. ☁️ Highlights: 📈 Triple-digit AI growth (8 straight quarters) 🌍 16M+ developers on ModelScope 🤝 Global partners like BMW Innovation meets real-world needs. Watch here: youtube.com/watch?v=gQemV8… #AlibabaCloud #AI…

youtube.com
YouTube
How Alibaba Quietly Became a Leader in AI
Welcome to the LoRA playground!😉If you run into any issues while creating on ModelScope, feel free to DM us.

Fresh batch of Qwen-Image LoRAs just landed! 📦 Massive shoutout to the open-source contributors for building these tools—you guys are the real MVPs. Drop a follow if you dig this, next episode is coming soon.
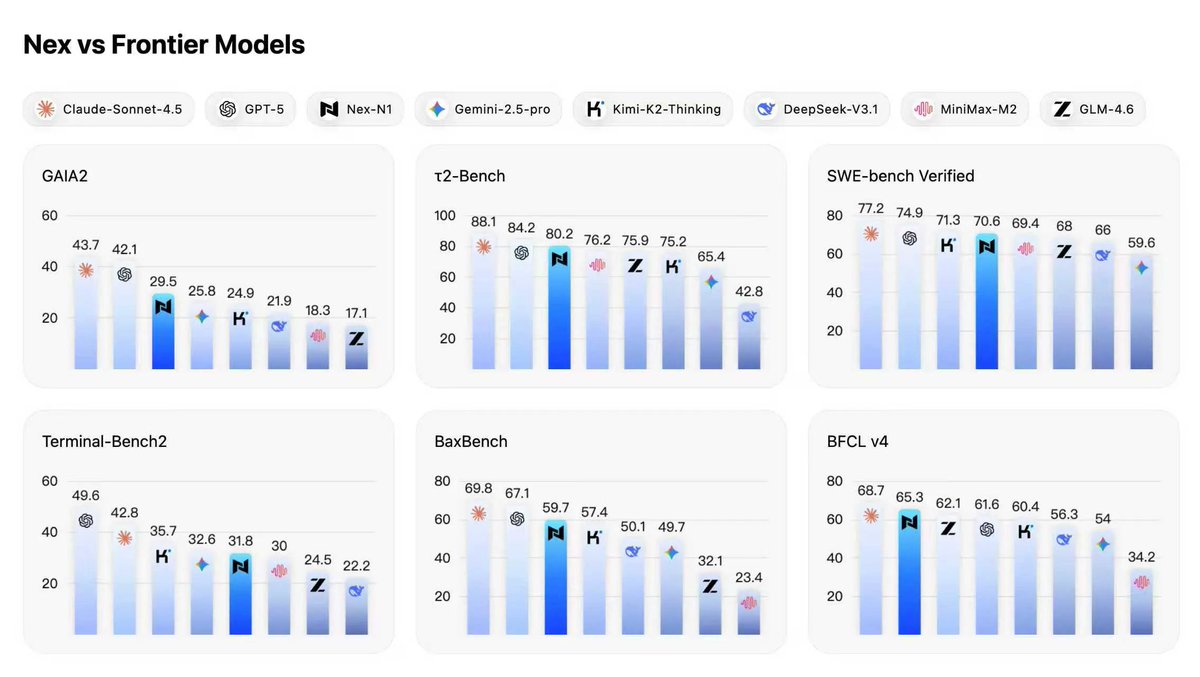
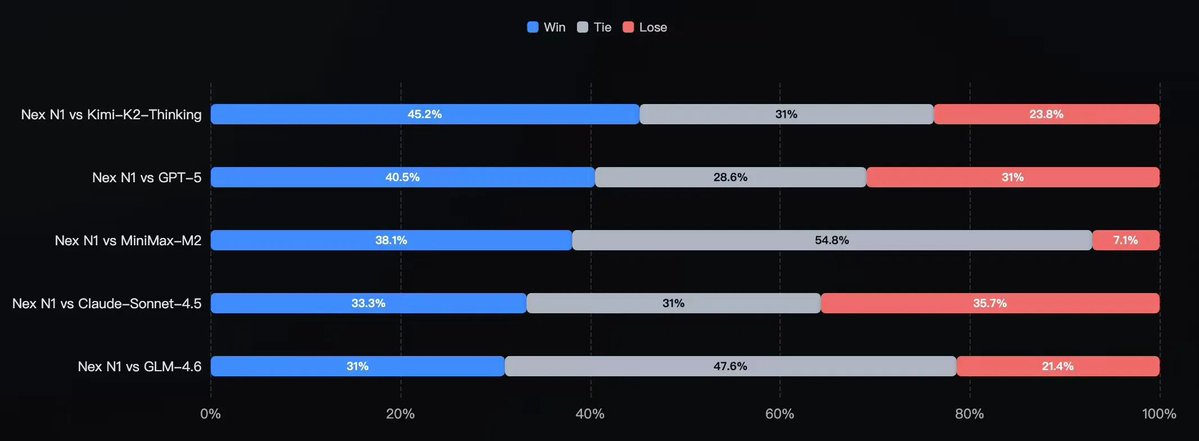
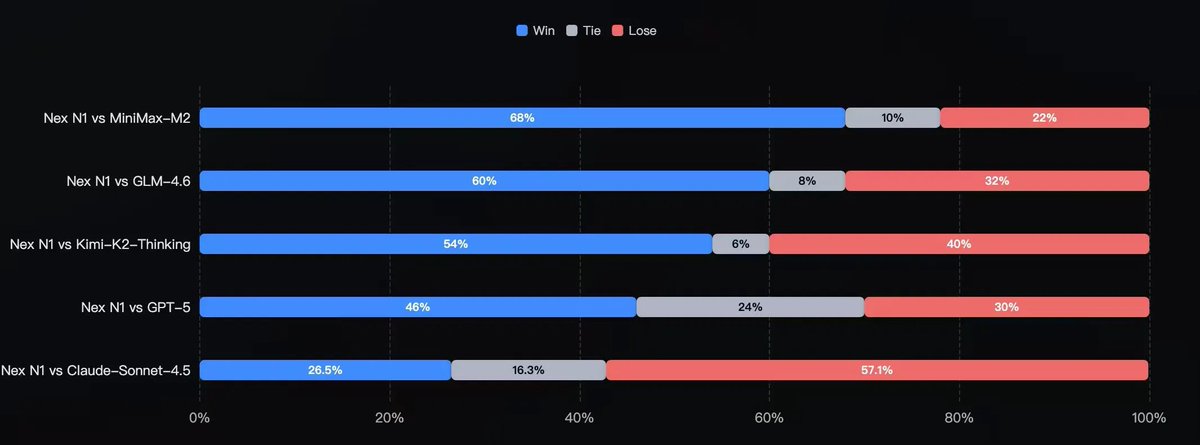
Meet Nex by NEX-AGI — a non-thinking model built for agents that crushes it in coding, tool use, and roleplay 🚀 ✅ SOTA among open models on Tau2-Bench, BFCL V4, GAIA2 ✅ Top-tier in frontend, vibe coding, and mini-program/backend dev (human eval confirmed) ✅ Plug-and-play…
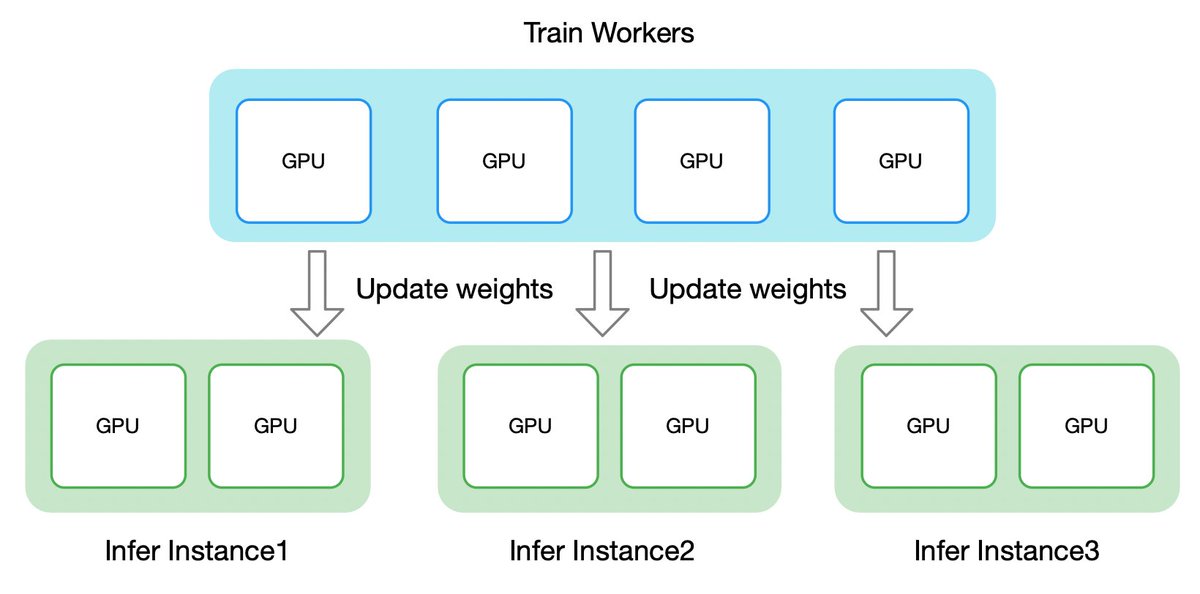
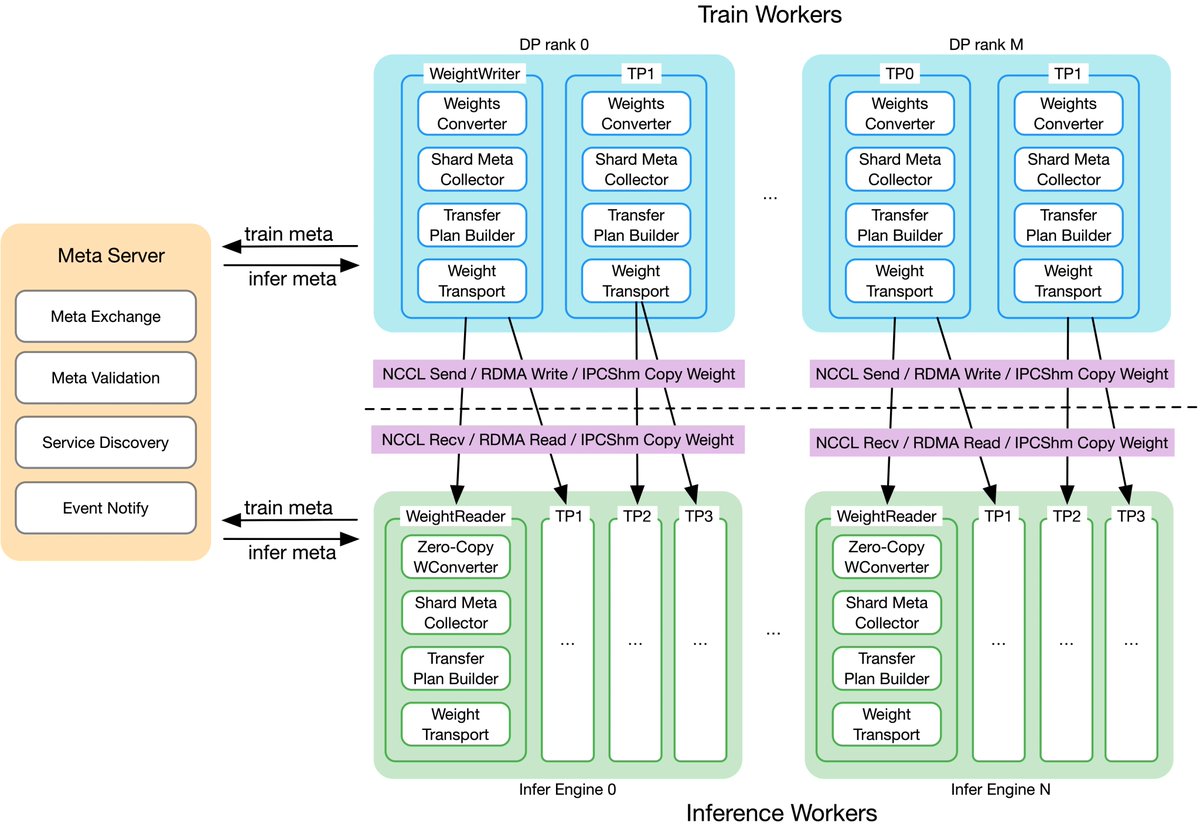
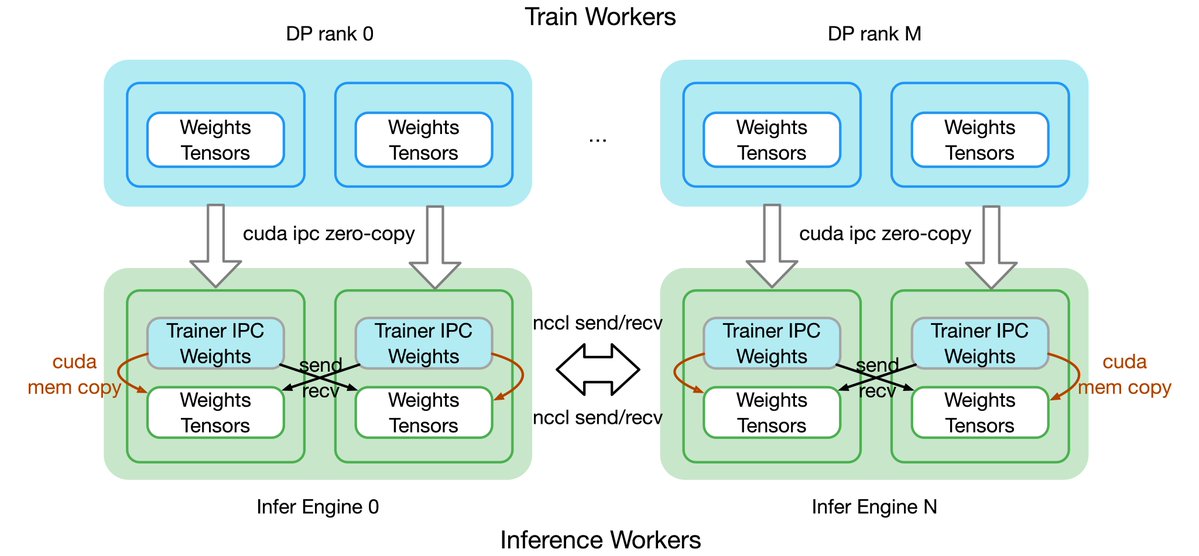
🚀 Awex is LIVE! — A blazing-fast weight-swap framework for RL training↔inference, now open-sourced by @AntLingAGI ! ⚡ ✅ Sync 1T-parameter models in 6s (RDMA) — 10x faster than prior art ✅ Zero-redundancy, in-place GPU updates ✅ Auto-adapts tensor layouts across Megatron /…


🚀 Open-sourcing ASystem Awex: The ultimate performance weight sync framework for RL! It solves the core training/inference weight params latency challenge: sync 1T-param models across thousands GPUs in <6s. For more RL system best practices, tuned in for the next 5-6 wks!
🚀 서울에서 만나요! AI로 당신의 창의력을 극대화하세요! 🇰🇷 @AMD @Alibaba_Qwen @alibaba_cloud @ModelScope2022 (Qwen과 함께 하는) AMD AI 개발자 밋업이 오는 12월 10일 서울에서 열립니다!이번 밋업에서는 생성형 AI와 그 미래에 대해서 탐색합니다. 좌석이 한정되어 있으니, 지금 바로…


🚀 @TencentHunyuan Just dropped: HunyuanVideo 1.5 — the lightweight SOTA video gen model that runs on a 14GB consumer GPU. 8.3B params. DiT architecture. Realistic 5–10s 480p/720p videos. Upscale to 1080p. ✅ Mid-prompt control (English/Chinese) ✅ Image-to-video with perfect…
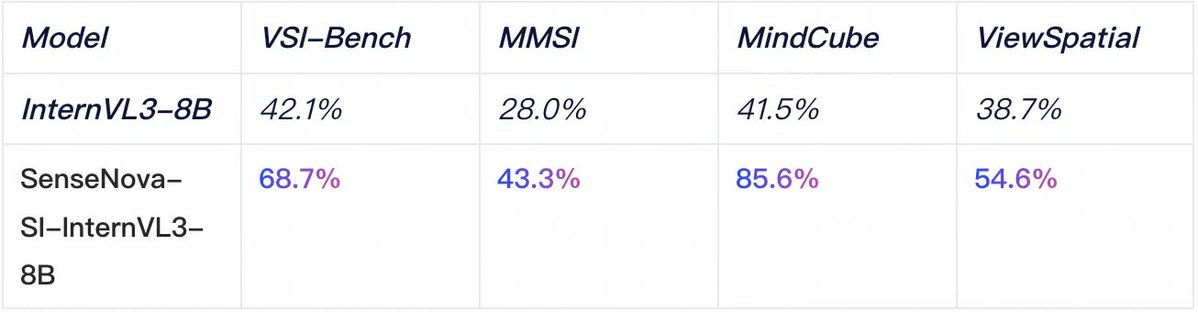
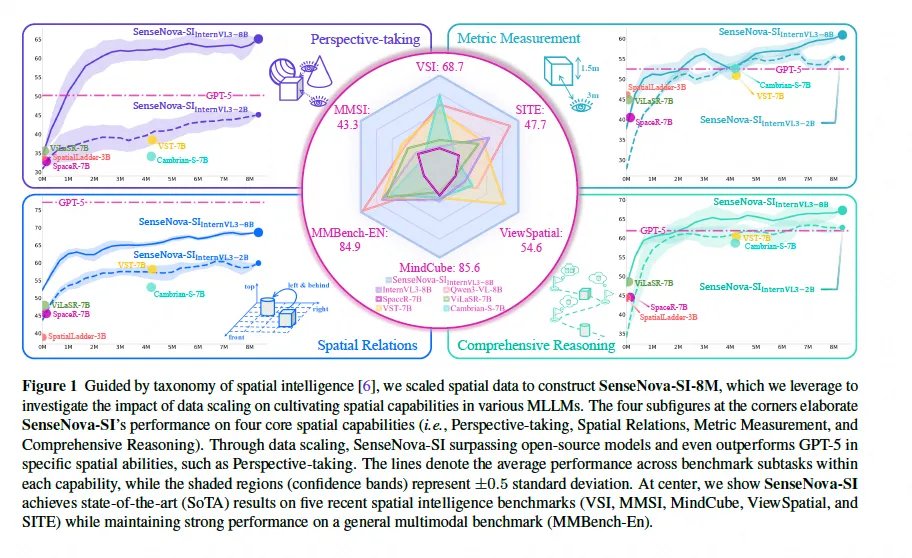
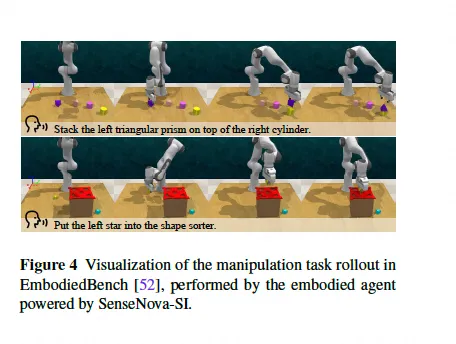
🤔 Most multimodal models still fail at basic spatial reasoning—they lack spatial intelligence. 🚀 Enter SenseNova-SI: an open-source model that finally gives AI real spatial smarts. Built by SenseTime + NTU, it outperforms GPT-5 on spatial tasks—especially perspective-taking,…
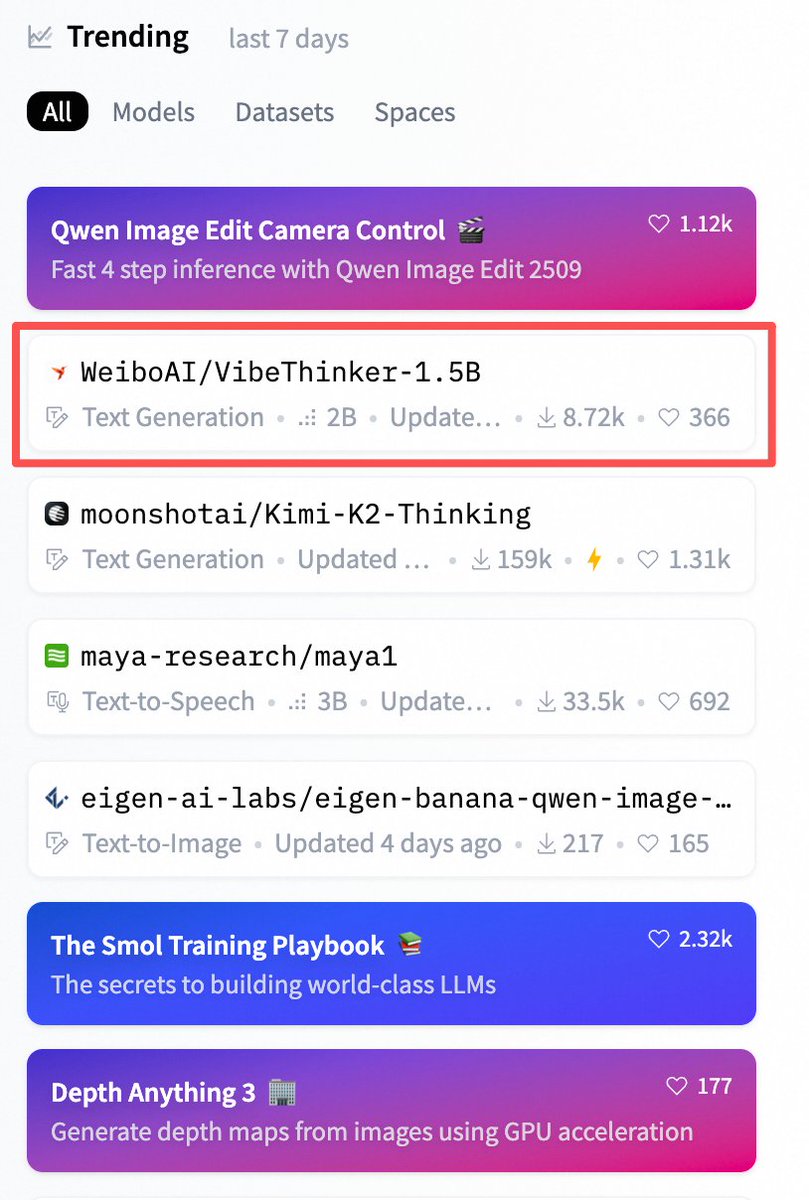
Huge congrats to WeiboAI! 🎉So awesome to see it land on Hugging Face’s Trending list after just a week — well deserved!
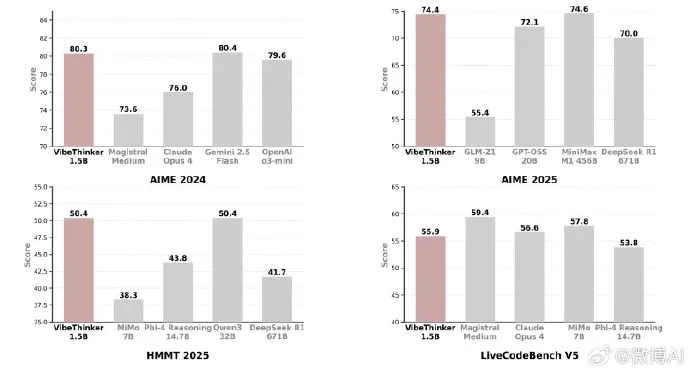
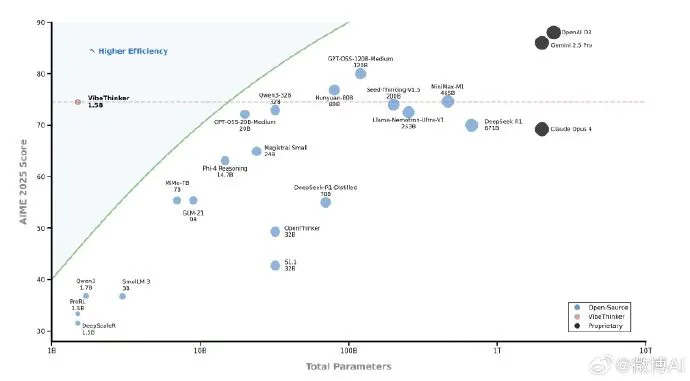
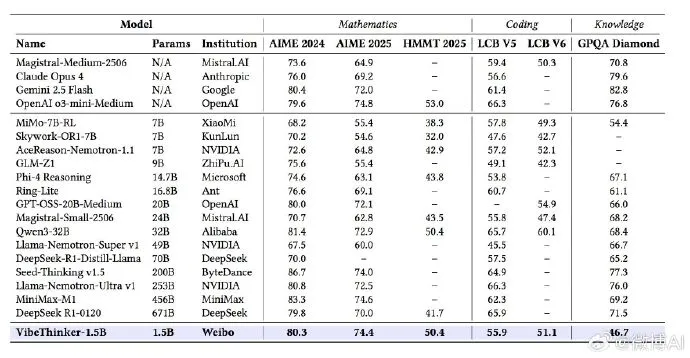
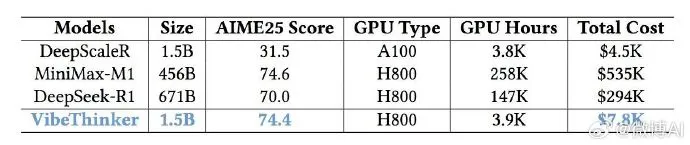
VibeThinker-1.5B is here 🚀 — and it flips the “bigger = smarter” myth on its head. ✅ Just 1.5B params! ✅ Trained via novel Spectrum-to-Signal Principle (SSP) ✅ Beats models 400x larger (e.g., 671B DeepSeek-R1) on hard math benchmarks (AIME24/25, HMMT25) ✅ Matches 456B…
🔥The LoRAs built on Qwen-Image-Edit-2509 are blowing up—and have dominated Hugging Face’s Trending list. All were trained on ModelScope and are available via free API: 📷 Multiple-angles — rotate product shots like a 360° camera 💡 Light_restoration — erase shadows, enhance…































































































United States Trends
- 1. Black Friday 316K posts
- 2. #releafcannabis N/A
- 3. Good Friday 49.7K posts
- 4. #DaesangForJin 55.1K posts
- 5. #FanCashDropPromotion N/A
- 6. ARMY Protect The 8thDaesang 58.3K posts
- 7. #AVenezuelaNoLaTocaNadie N/A
- 8. #ENHYPEN 187K posts
- 9. third world countries 41.6K posts
- 10. yeonjun 67.1K posts
- 11. Mnet 207K posts
- 12. Sarah Beckstrom 262K posts
- 13. Lamar 49.4K posts
- 14. Cyber Monday 5,316 posts
- 15. Mr. President 21.7K posts
- 16. MAMA Awards 465K posts
- 17. BNB Chain 7,065 posts
- 18. Wegmans 2,368 posts
- 19. Shane 27.8K posts
- 20. ilya 22.5K posts
Something went wrong.
Something went wrong.