
Junrong Lin
@OcssLin
MTS @Alibaba_Qwen on MLsys, building SGLang @lmsysorg | Prev. @DukeU

Airbnb CEO Brian Chesky: “We’re relying a lot on Alibaba’s Qwen model. It’s very good. It’s also fast and cheap... We use OpenAI’s latest models, but we typically don’t use them that much in production because there are faster and cheaper models.” The valley is built on Qwen?

🚀 SGLang In-Depth Review of the NVIDIA DGX Spark is LIVE! Thanks to @NVIDIA’s early access program, SGLang makes its first ever appearance in a consumer product, the brand-new DGX Spark. The DGX Spark’s 128GB Unified Memory and Blackwell architecture set a new standard for…


🧠For Qwen3-Next’s Day 0 support in SGLang, one tricky part was enabling spec decoding with the Hybrid Linear Model—since SSM & conv caches only store the last position (unlike KV cache). 🚀After tons of effort with @qingquan_song, we achieved >2× speedup! Benchmarks below



🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here! 🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!) 🔹Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed &…

Special thanks to my old friends from the SGLang community especially @hebiao064 @qingquan_song and more (sry I don’t know their X account 🥹) who help support the hybrid model MTP. For linear attention, the eviction during eagle verification phase is different from the regular…
🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here! 🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!) 🔹Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed &…



We’re live! 🎉 This is the official account for slime — an open-source, SGLang-native post-training framework for RL scaling. Kicking things off with our first milestone → v0.1.0 release 🧪 Blog: thudm.github.io/slime/blogs/re… Follow us to run RL faster ⚡️
cool

😎Grad to see my first participated project at Qwen is finally out. More awesome work is coming
Big news: Introducing Qwen3-Max-Preview (Instruct) — our biggest model yet, with over 1 trillion parameters! 🚀 Now available via Qwen Chat & Alibaba Cloud API. Benchmarks show it beats our previous best, Qwen3-235B-A22B-2507. Internal tests + early user feedback confirm:…


We are using SGLang at really large scale RL, and it’s been working great :)

xAI may be one of the single biggest contributors to open-source inference just by serving everything with SGLang


More on QAT: 1. QAT explanation: pytorch.org/blog/quantizat… 2. MXFP4 QAT is supported in NVIDIA ModelOpt: github.com/NVIDIA/TensorR… 3. A quick drawing of how gpt-oss is trained in my understanding:

🚀 Introducing the first OSS example of fine-tuning gpt-oss with MXFP4 QAT! Powered by NVIDIA ModelOpt + SGLang. Highlights 1. Fine-tune gpt-oss while keeping the original MXFP4 format 2. Preserve FP4 efficiency and recover accuracy 3. Deploy seamlessly with SGLang! Full Blog👇

chad
✅ We’re excited to support @Alibaba_Qwen’s Qwen3-Coder on SGLang! With tool call parser and expert parallelism enabled, it runs smoothly with flexible configurations. Just give it a try! 🔗 github.com/zhaochenyang20…

>>> Qwen3-Coder is here! ✅ We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves…

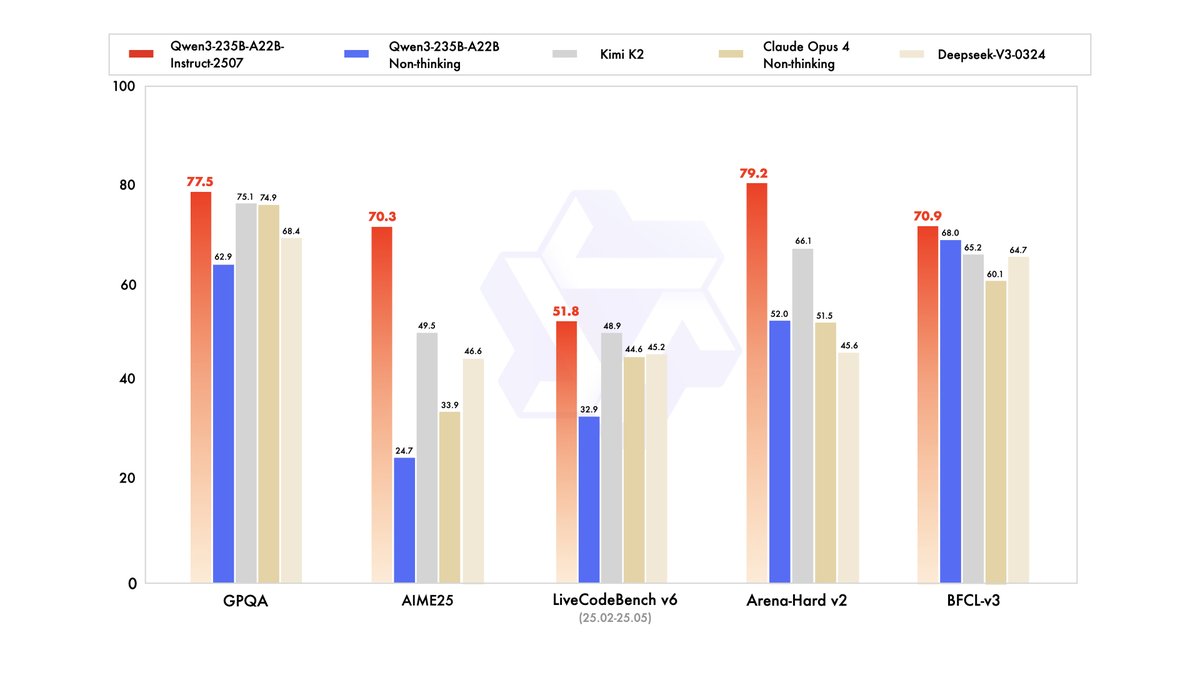
Bye Qwen3-235B-A22B, hello Qwen3-235B-A22B-2507! After talking with the community and thinking it through, we decided to stop using hybrid thinking mode. Instead, we’ll train Instruct and Thinking models separately so we can get the best quality possible. Today, we’re releasing…

salute


Meet Qwen-VLo, your AI creative engine: • Concept-to-Polish: Turn rough sketches or text prompts into high-res visuals • On-the-Fly Edits: Refine product shots, adjust layouts or styles with simple commands • Global-Ready: Generate image in multiple languages • Progressive…
We're excited to release OME, which is a Kubernetes operator for enterprise-grade management and serving of Large Language Models (LLMs). It optimizes the deployment and operation of LLMs by automating model management, intelligent runtime selection, efficient resource…
























































































United States Trends
- 1. Veterans Day 359K posts
- 2. Woody 11.6K posts
- 3. Toy Story 5 13.9K posts
- 4. Nico 140K posts
- 5. Luka 83.3K posts
- 6. Gambit 40.1K posts
- 7. Travis Hunter 3,487 posts
- 8. Payne 11.9K posts
- 9. Mavs 32.4K posts
- 10. Vets 32K posts
- 11. Sabonis 3,653 posts
- 12. Pat McAfee 5,163 posts
- 13. #JonatanVendeHumo 3,390 posts
- 14. Wike 113K posts
- 15. Jonatan Palacios 2,171 posts
- 16. Battlenet 3,492 posts
- 17. SBMM 1,243 posts
- 18. Kyrie 7,753 posts
- 19. Antifa 186K posts
- 20. Bond 73.2K posts
Something went wrong.
Something went wrong.