
내가 좋아할 만한 콘텐츠















As one of the fastest-growing OSS projects, vLLM inevitably accumulated some technical debts. We noticed it, and re-architected vLLM's core with careful engineering. Enjoy simpler code & higher performance with vLLM V1!

🚀 With the v0.7.0 release today, we are excited to announce the alpha release of vLLM V1: A major architectural upgrade with 1.7x speedup! Clean code, optimized execution loop, zero-overhead prefix caching, enhanced multimodal support, and more.


Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!…


The DeepSeek V3.2 day-0 support wouldn't be possible without the help from nvidia, thanks to the great team!

📣 We partnered with @vllm_project to optimize DeepSeek-V3.2-Exp across our platform. @deepseek_ai's Sparse Attention uses lightning indexer to selectively attend to the most relevant 2K tokens enabling higher performance for long context use cases. vLLM, the open source…
How does @deepseek_ai Sparse Attention (DSA) work? It has 2 components: the Lightning Indexer and Sparse Multi-Latent Attention (MLA). The indexer keeps a small key cache of 128 per token (vs. 512 for MLA). It scores incoming queries. The top-2048 tokens to pass to Sparse MLA.
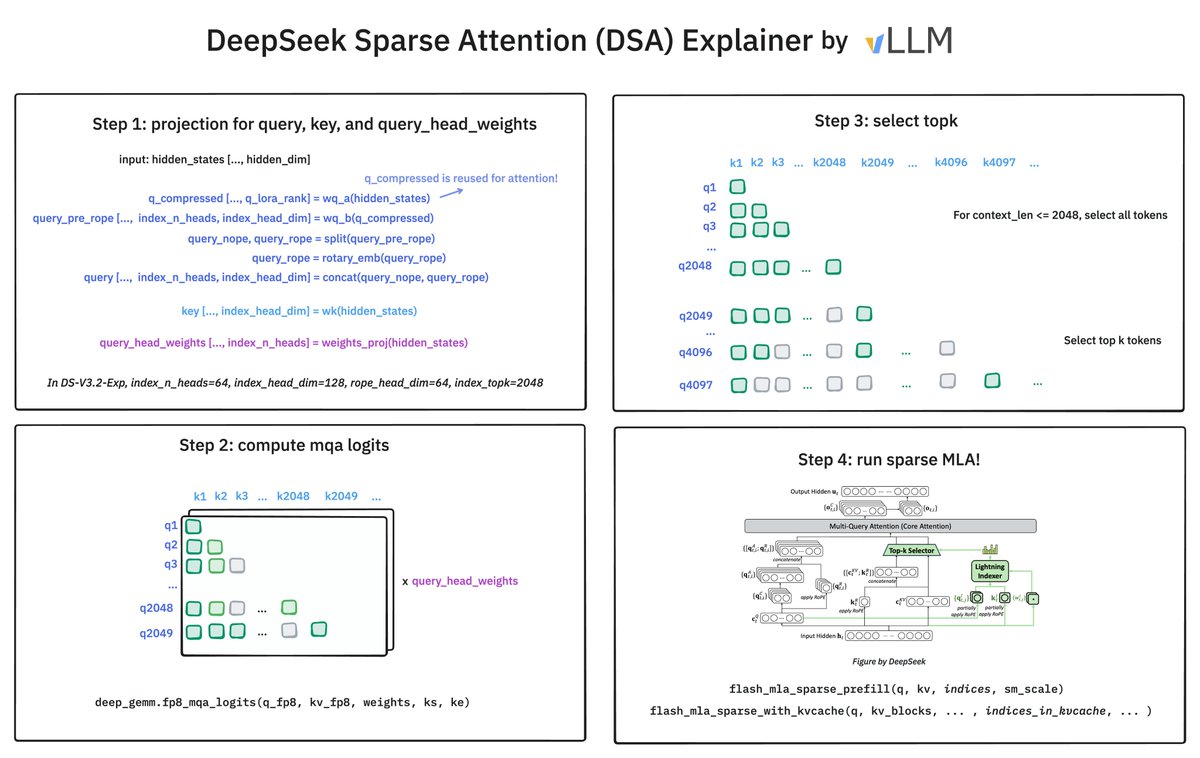

🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n
LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…


Thanks to @vLLM_project for enabling efficient Qwen3-Next inference with accelerated kernels and native memory management!
Welcome Qwen3-Next! You can run it efficiently on vLLM with accelerated kernels and native memory management for hybrid models. blog.vllm.ai/2025/09/11/qwe…

At Thinking Machines, our work includes collaborating with the broader research community. Today we are excited to share that we are building a vLLM team at @thinkymachines to advance open-source vLLM and serve frontier models. If you are interested, please DM me or @barret_zoph!…
LLM inference can be made deterministic with a special care on kernels. Check out the vllm example on how we achieve this!
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to…

Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to…
🌏 vLLM Shanghai Meetup Recap 🚀 Last weekend, we gathered with the community in Shanghai to dive into: → Contributing to vLLM → Distributed inference → ERNIE 4.5 integration → Mooncake + LMCache → MetaX hardware support The community is pushing vLLM to new levels of…

I’ve been fortunate to lead the infra and inference work that brings gpt-oss to life. A year ago, I joined OpenAI after building vLLM from scratch — It’s deeply meaningful to now be on the other side of the release, helping share models back with the open-source community.

Our open models are here. Both of them. openai.com/open-models

Here's the blog post on vLLM's integration: blog.vllm.ai/2025/08/05/gpt…

Thank you @OpenAI for open-sourcing these great models! 🙌 We’re proud to be the official launch partner for gpt-oss (20B & 120B) – now supported in vLLM 🎉 ⚡ MXFP4 quant = fast & efficient 🌀 Hybrid attention (sliding + full) 🤖 Strong agentic abilities 🚀 Easy deployment 👉🏻…
Thank you @OpenAI for open-sourcing these great models! 🙌 We’re proud to be the official launch partner for gpt-oss (20B & 120B) – now supported in vLLM 🎉 ⚡ MXFP4 quant = fast & efficient 🌀 Hybrid attention (sliding + full) 🤖 Strong agentic abilities 🚀 Easy deployment 👉🏻…
Our open models are here. Both of them. openai.com/open-models
The model is supported in vLLM, welcome to try this powerful model on your own🚀

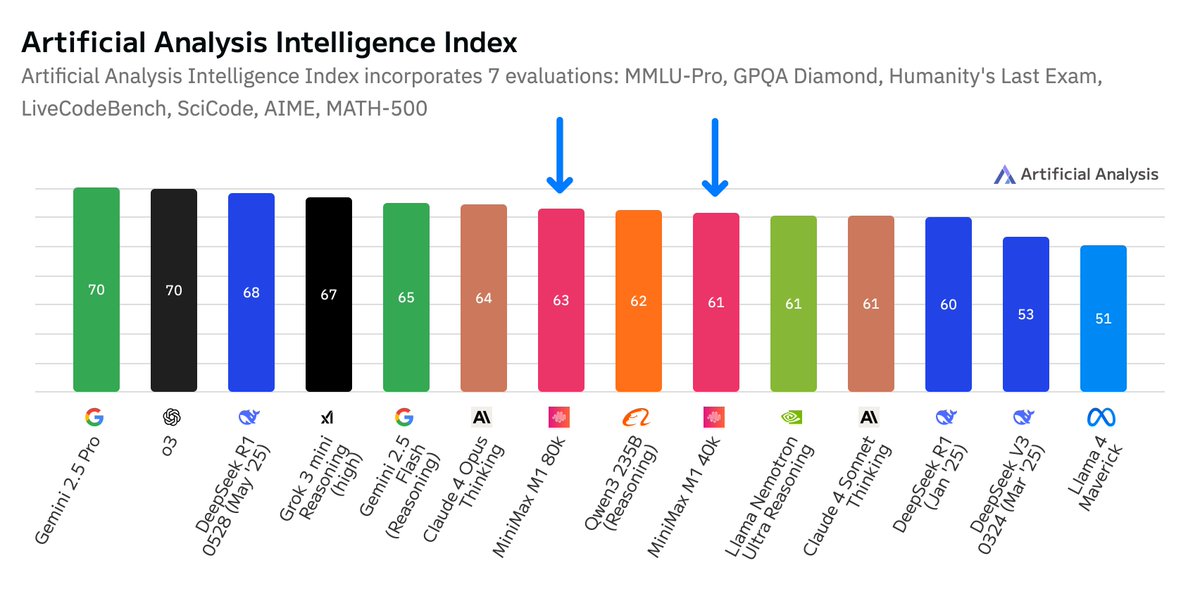
MiniMax launches their first reasoning model: MiniMax M1, the second most intelligent open weights model after DeepSeek R1, with a much longer 1M token context window @MiniMax__AI M1 is based on their Text-01 model (released 14 Jan 2025) - an MoE with 456B total and 45.9B active…
vLLM has just reached 50K github stars! Huge thanks to the community!🚀 Together let's bring easy, fast, and cheap LLM serving for everyone✌🏻


We built sparse-frontier — a clean abstraction that lets you focus on your custom sparse attention implementation while automatically inheriting vLLM’s optimizations and model support. As a PhD student, I've learned that sometimes the bottleneck in research isn't ideas — it's…


Excited to share our work on Speculative Decoding @Snowflake AI Research! 🚀 4x faster LLM inference for coding agents like OpenHands @allhands_ai 💬 2.4x faster LLM inference for interactive chat 💻 Open-source via Arctic Inference as a plugin for @vllm_project 🧵


Thanks for the quick merge and instant support for our models! Users of vllm and Qwen, feel free to try it out to see whether everything is good for you!
⬆️ pip install -U vLLM vllm serve Qwen/Qwen3-235B-A22B-FP8 --enable-reasoning --reasoning-parser deepseek_r1 --tensor-parallel-size 4 vLLM introduce Day 0 support for @Alibaba_Qwen Qwen3 and Qwen3 MoE model architecture. Try it out: github.com/vllm-project/v…


Announcing the first Codex open source fund grant recipients: ⬩vLLM - inference serving engine @vllm_project ⬩OWASP Nettacker - automated network pentesting @iotscan ⬩Pulumi - infrastructure as code in any language @pulumicorp ⬩Dagster - cloud-native data pipelines @dagster…
perf update: we are continuing to see benefits with vLLM V1 engine’s highly performant design. on 8xH200, vLLM leads in throughput for @deepseek_ai V3/R1 models. we expect further enhancements in collaboration with DeepSeek’s inference engine open source plan.

vLLM🤝🤗! You can now deploy any @huggingface language model with vLLM's speed. This integration makes it possible for one consistent implementation of the model in HF for both training and inference. 🧵 blog.vllm.ai/2025/04/11/tra…

































































































United States 트렌드
- 1. Auburn 38.6K posts
- 2. Brewers 54.3K posts
- 3. Georgia 63.7K posts
- 4. Cubs 51.1K posts
- 5. Kirby 20.5K posts
- 6. Michigan 58.8K posts
- 7. Hugh Freeze 2,628 posts
- 8. Kyle Tucker 2,816 posts
- 9. #GoDawgs 4,889 posts
- 10. #ThisIsMyCrew 2,981 posts
- 11. Boots 48K posts
- 12. Jackson Arnold 2,000 posts
- 13. Nuss 5,494 posts
- 14. Sherrone Moore 1,893 posts
- 15. Penn State 28.1K posts
- 16. Billy Napier 2,871 posts
- 17. #MagicBrew 10.8K posts
- 18. NLCS 15.4K posts
- 19. Gilligan's Island 3,692 posts
- 20. #UFCRio 57.6K posts
내가 좋아할 만한 콘텐츠
-
 Zhuohan Li
Zhuohan Li
@zhuohan123 -
 Abhi Venigalla
Abhi Venigalla
@ml_hardware -
 Tri Dao
Tri Dao
@tri_dao -
 Joey Gonzalez
Joey Gonzalez
@profjoeyg -
 SkyPilot
SkyPilot
@skypilot_org -
 Rulin Shao
Rulin Shao
@RulinShao -
 Eric Hartford
Eric Hartford
@QuixiAI -
 Shishir Patil
Shishir Patil
@shishirpatil_ -
 Nous Research
Nous Research
@NousResearch -
 Lianmin Zheng
Lianmin Zheng
@lm_zheng -
 Conor Power
Conor Power
@conor_power23 -
 Dacheng Li
Dacheng Li
@DachengLi177 -
 Hao Zhang
Hao Zhang
@haozhangml -
 Vitaliy Chiley
Vitaliy Chiley
@vitaliychiley -
 João Gante
João Gante
@joao_gante
Something went wrong.
Something went wrong.