
Anda mungkin suka










I hope this PDP-10 makes it to the excellent @ComputerHistory geekwire.com/2024/seattles-…


Large multimodal models often lack precise low-level perception needed for high-level reasoning, even with simple vector graphics. We bridge this gap by proposing an intermediate symbolic representation that leverages LLMs for text-based reasoning. mikewangwzhl.github.io/VDLM 🧵1/4
Wordle 1,006 5/6 🟩⬜⬜⬜⬜ 🟩🟩⬜⬜⬜ 🟩🟩🟩⬜⬜ 🟩🟩🟩🟩⬜ 🟩🟩🟩🟩🟩
0 suara · Hasil akhir


Why do neural nets generalize so well?🤔 There's a ton of work on SGD, flat minima, ... but the root cause is that their inductive biases somehow match properties of real-world data.🌎 We've examined these inductive biases in *untrained* networks.🎲 arxiv.org/abs/2403.02241 ⬇️

Mechanism for feature learning in neural networks and backpropagation-free machine learning models | Science science.org/doi/10.1126/sc…

And today is T - 2 weeks for my other @NVIDIA #GTC session - a fireside chat with @ChrSzegedy, cofounder of @xAI. Christian is one of the seminal research figures in the Deep Learning community, but the main focus of our chat will be on something that he has been working very…


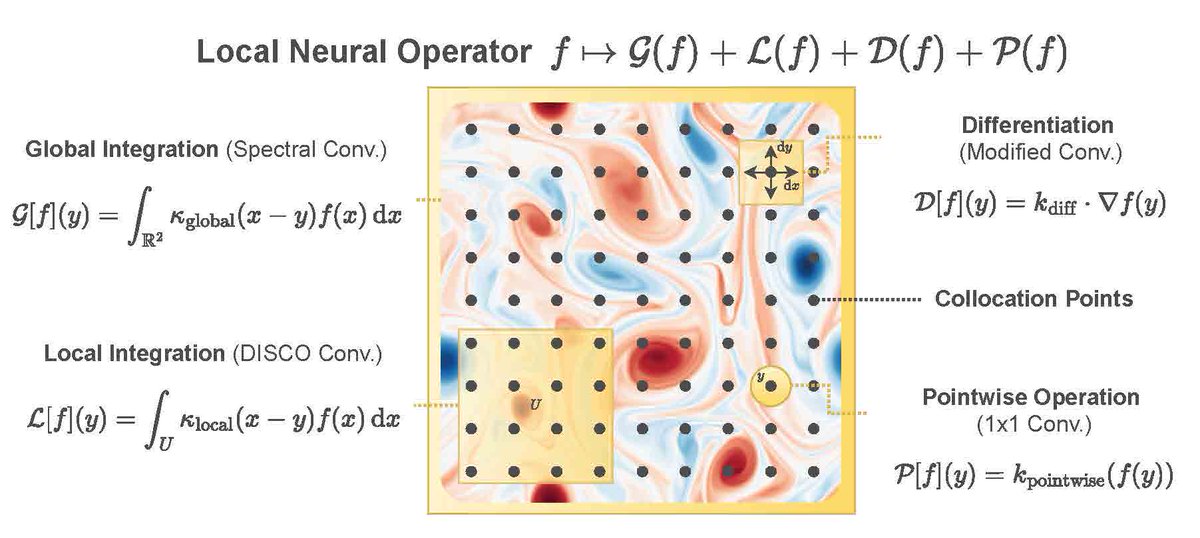
How do we capture local features across multiple resolutions? While standard convolutional layers work only on a fixed input-resolution, we design local neural operators that learn integral and differential kernels, and are principled ways to extend standard convolutions to…

Me: Can you draw a very normal image? ChatGPT: Here is a very normal image depicting a tranquil suburban street scene during the daytime. Me: Not bad, but can you go more normal than that? (cont.)


Today's AI (credit: Balazs Szegedy using DALL-E-3)

So tempting to just group a collection of "specialized"s and call it "general" arxiv.org/abs/2311.02462
Inception used 1.5X less compute than AlexNet and 12X less than VGG, outperforming both. The trend continued with mobile net... etc. IMO, today's LLMs are insanely inefficient/compute. Regulations that impose limits on the amount of compute spent on AI training will just…

Regulation starts at roughly two orders of magnitude larger than a ~70B Transformer trained on 2T tokens -- which is ~5e24. Note: increasing the size of the dataset OR the size of the transformer increases training flops. The (rumored) size of GPT-4 is regulated.

New Executive Order is out. Already one notable item: Any AI model that required more than 1e26 floating point operations or 1e23 integer operations to build must report to the government.


$0.25/mile

After a journey of nearly 3.9 billion miles, the #OSIRISREx asteroid sample return capsule is back on Earth. Teams perform the initial safety assessment—the first persons to come into contact with this hardware since it was on the other side of the solar system.

The AI world is in a GPU crunch and meanwhile NERSC is offering 50% off its A100 GPUs (rest.nersc.gov/REST/announcem…). They could make a killing by backfilling idle capacity with commercial workloads 💰 💰 💰
Almost a Kessler syndrome for LLMs arxiv.org/abs/2305.17493 arxiv.org/abs/2307.01850
This is super cool

Personal Announcement! I’m launching @SakanaAILabs together with my friend, Llion Jones (@YesThisIsLion). sakana.ai is a new R&D-focused company based in Tokyo, Japan. We’re on a quest to create a new kind of foundation model based on nature-inspired intelligence!

































































































United States Tren
- 1. HARRY STYLES N/A
- 2. #PMSSEATGEEKPUNCHAHT N/A
- 3. Insurrection Act N/A
- 4. KISS ALL THE TIME N/A
- 5. #BTS_ARIRANG N/A
- 6. Kuminga N/A
- 7. Lara Croft N/A
- 8. Arrest Tim Walz N/A
- 9. Guess 1 N/A
- 10. InfoFi N/A
- 11. benson boone N/A
- 12. The Great Healthcare Plan N/A
- 13. Giants N/A
- 14. Frey N/A
- 15. Mahmoud Khalil N/A
- 16. #NationalHatDay N/A
- 17. DISCO OCCASIONALLY N/A
- 18. Apple Music N/A
- 19. GRRM N/A
- 20. Casa Blanca N/A










Something went wrong.
Something went wrong.