Vijay
@__tensorcore__
MLIR, CUTLASS,Tensor Core arch @NVIDIA. Mechanic @hpcgarage. Exercise of any 1st amendment rights are for none other than myself.
Tal vez te guste















🚨🔥 CUTLASS 4.0 is released 🔥🚨 pip install nvidia-cutlass-dsl 4.0 marks a major shift for CUTLASS: towards native GPU programming in Python slidehelloworld.png docs.nvidia.com/cutlass/media/…


Excited to share what friends and I have been working on at @Standard_Kernel We've raised from General Catalyst (@generalcatalyst), Felicis (@felicis), and a group of exceptional angels. We have some great H100 BF16 kernels in pure CUDA+PTX, featuring: - Matmul 102%-105% perf…


Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference” We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to…

“TogetherAI’s chief scientist @tri_dao announced Flash Attention v4 … uses CUTLASS CuTe Python DSL” As always, thanks for being the tip of the spear and pushing us along too 💚

TogetherAI's Chief Scientist @tri_dao announced Flash Attention v4 at HotChips Conference which is up to 22% faster than the attention kernel implementation from NVIDIA's cuDNN library. Tri Dao was able to achieve this 2 key algorithmic changes. Firstly, it uses a new online…

Using CUTLASS CuTe-DSL, TogetherAI's Chief Scientist @tri_dao announced that he has written kernels that is 50% faster than NVIDIA's latest cuBLAS 13.0 library for small K reduction dim shapes on Blackwell during today's hotchip conference. His kernels beats cuBLAS by using 2…


Cute-DSL is basically perfect (for me). thank you nvidia and cutlass team. i no longer need to wait for long compile times because i underspecified a template param. i hope everyone involved gets an extra chicken nugget in their happy meal

On Sep 6 in NYC, this won't be your typical hackathon where you do your own thing in a corner and then present at the of the day. You'll deploy real models to the market, trades will happen, chaos should be expected. The fastest model is great but time to market matters more.

ariXv gpu kernel researcher be like: • liquid nitrogen cooling their benchmark GPU • overclock their H200 to 1000W "Custom Thermal Solution CTS" • nvidia-smi boost-slider --vboost 1 • nvidia-smi -i 0 --lock-gpu-clocks=1830,1830 • use specially binned GPUs where the number…

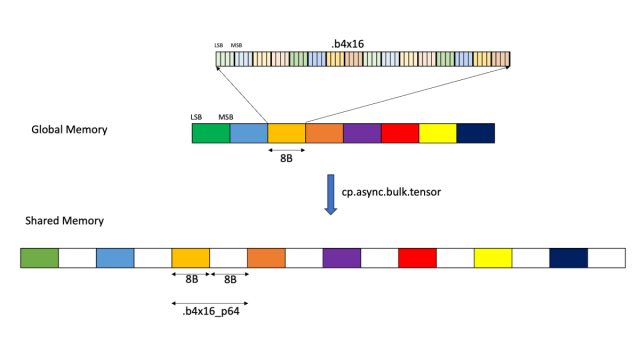
Part 2: developer.nvidia.com/blog/cutlass-3… Covers the design of CUTLASS 3.x itself and how it builds a 2 layer GPU microkernel abstraction using CuTe as the foundation.
CUTLASS 4.1 is now available, which adds support for ARM systems (GB200) and block scaled MMAs
🚨🔥 CUTLASS 4.0 is released 🔥🚨 pip install nvidia-cutlass-dsl 4.0 marks a major shift for CUTLASS: towards native GPU programming in Python slidehelloworld.png docs.nvidia.com/cutlass/media/…

Hierarchical layout is super elegant. Feels like the right abstraction for high performance GPU kernels. FlashAttention 2 actually started bc we wanted to rewrite FA1 in CuTe
developer.nvidia.com/blog/cutlass-p… marks the start of a short series of blogposts about CUTLASS 3.x and CuTe that we've been meaning to write for years. There are a few more parts to come still, hope you enjoy!
CuTe is such an elegant library that we stopped working on our own system and wholeheartedly adopted CUTLASS for vLLM in the beginning of 2024. I can happily report that was a very wise investment! Vijay and co should be so proud of the many strong OSS projects built on top 🥳
developer.nvidia.com/blog/cutlass-p… marks the start of a short series of blogposts about CUTLASS 3.x and CuTe that we've been meaning to write for years. There are a few more parts to come still, hope you enjoy!
This is what the internet was made for 🥹


Cosmos-Predict2 meets NATTEN. We just released variants of Cosmos-Predict2 where we replace most self attentions with neighborhood attention, bringing up to 2.6X end-to-end speedup, with minimal effect on quality! github.com/nvidia-cosmos/… (1/5)
Getting mem-bound kernels to speed-of-light isn't a dark art, it's just about getting the a couple of details right. We wrote a tutorial on how to do this, with code you can directly use. Thanks to the new CuTe-DSL, we can hit speed-of-light without a single line of CUDA C++.

🦆🚀QuACK🦆🚀: new SOL mem-bound kernel library without a single line of CUDA C++ all straight in Python thanks to CuTe-DSL. On H100 with 3TB/s, it performs 33%-50% faster than highly optimized libraries like PyTorch's torch.compile and Liger. 🤯 With @tedzadouri and @tri_dao

🦆🚀QuACK🦆🚀: new SOL mem-bound kernel library without a single line of CUDA C++ all straight in Python thanks to CuTe-DSL. On H100 with 3TB/s, it performs 33%-50% faster than highly optimized libraries like PyTorch's torch.compile and Liger. 🤯 With @tedzadouri and @tri_dao
Another 🔥 blog about CUTLASS from @colfaxintl, this time focusing on the gory details of block-scaled MXFP and NVFP data types and Blackwell kernels for them. research.colfax-intl.com/cutlass-tutori…


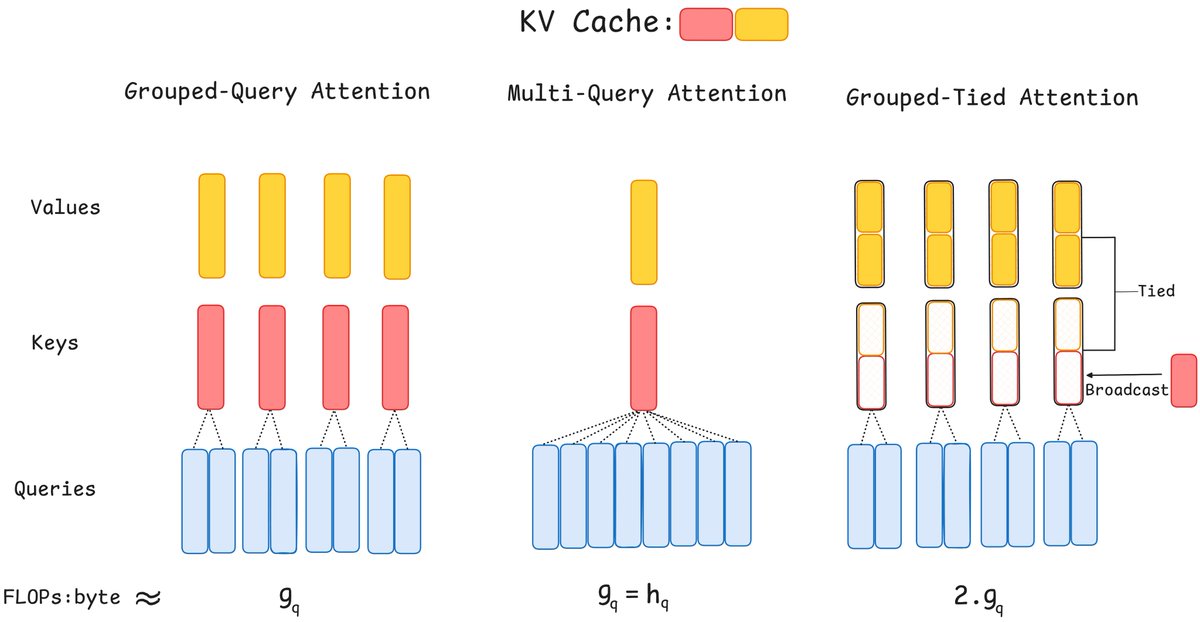
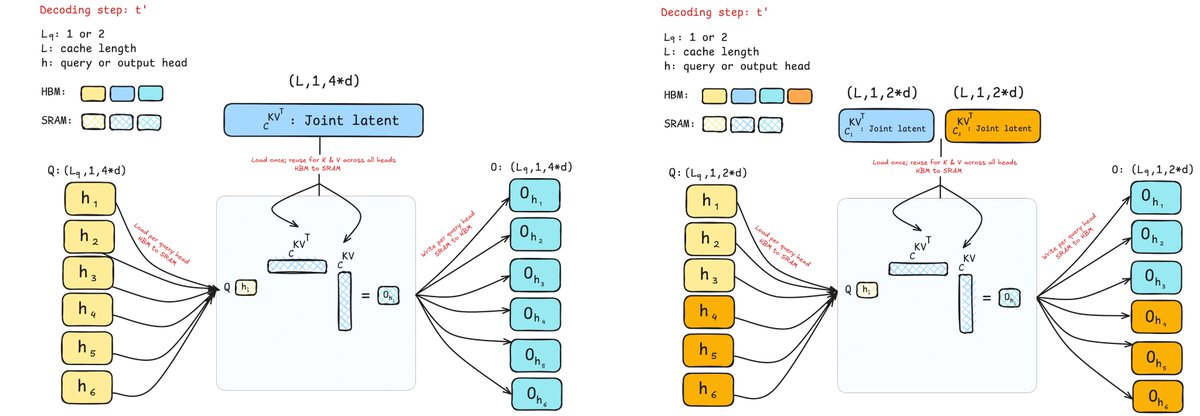
We've been thinking about what the "ideal" architecture should look like in the era where inference is driving AI progress. GTA & GLA are steps in this direction: attention variants tailored for inference: high arithmetic intensity (make GPUs go brr even during decoding), easy to…

"Pre-training was hard, inference easy; now everything is hard."-Jensen Huang. Inference drives AI progress b/c of test-time compute. Introducing inference aware attn: parallel-friendly, high arithmetic intensity – Grouped-Tied Attn & Grouped Latent Attn



























































































































United States Tendencias
- 1. Jets 79.5K posts
- 2. Jets 79.5K posts
- 3. Justin Fields 8,278 posts
- 4. Aaron Glenn 4,338 posts
- 5. #HardRockBet 3,331 posts
- 6. Sean Payton 2,027 posts
- 7. London 202K posts
- 8. Garrett Wilson 3,243 posts
- 9. Bo Nix 3,301 posts
- 10. HAPPY BIRTHDAY JIMIN 147K posts
- 11. Tyrod 1,536 posts
- 12. #OurMuseJimin 192K posts
- 13. #DENvsNYJ 2,079 posts
- 14. #JetUp 1,916 posts
- 15. Peart 1,897 posts
- 16. #30YearsofLove 168K posts
- 17. Bam Knight N/A
- 18. Kurt Warner N/A
- 19. Rich Eisen N/A
- 20. Anthony Richardson N/A
Tal vez te guste
-
 Hot Chips
Hot Chips
@hotchipsorg -
 Underfox
Underfox
@Underfox3 -
 Nicholas Malaya
Nicholas Malaya
@nicholasmalaya -
 Maxime Chevalier
Maxime Chevalier
@Love2Code -
 Cardyak
Cardyak
@Cardyak -
 @parkbot.bsky.social
@parkbot.bsky.social
@philparkbot -
 Andrew Kerr
Andrew Kerr
@arkerr -
 Dan Ernst
Dan Ernst
@ernstdj -
 Alejandro (Alex) Chacon
Alejandro (Alex) Chacon
@achacond -
 Cheese
Cheese
@System360Cheese -
 Shawn Zhang 章闻韶
Shawn Zhang 章闻韶
@shawnwzhang -
 Matt
Matt
@matt_dz -
 Ronak Singhal
Ronak Singhal
@rsinghal1 -
 Moshe Dolejsi
Moshe Dolejsi
@lasserith -
 John Garfield
John Garfield
@peresuslog
Something went wrong.
Something went wrong.