
Bert Maher
@tensorbert
I’m a software engineer building high-performance kernels and compilers at Anthropic! Previously at Facebook/Meta (PyTorch, HHVM, ReDex)
You might like
















One of the most common flaws of math textbooks is that they present only the logic, without the intuition. They give you the later, cleaned up version of the idea, which hides the way it was discovered.
This is all true, but Soumith is also one of the most brilliant strategic thinkers in the world. Some of us just fail a lot, dust ourselves off, and keep hacking the next day ☺️

If you feel like giving up, you must read this never-before-shared story of the creator of PyTorch and ex-VP at Meta, Soumith Chintala. > from hyderabad public school, but bad at math > goes to a "tier 2" college in India, VIT in Vellore > rejected from all 12 universities for…

This got me thinking that both int and FP math is “emulated” via a pretty complex set of transistors. I wonder how many gates/transistors it takes to implement an int8 fma versus an fp8, e4m3 fma

I’ve heard this complaint from a couple people recently, and I’m surprised because we optimized the launch path like a year ago and got it down to ~10us. There’s a now closed GitHub issue I filed with a microbenchmark - someone should run it, profile, and bring it down

why is triton’s kernel launch cpu overhead so freaking high? the actual kernel takes 10x less execution time than to launch it and i can’t use cuda graphs because the shapes are dynamic.
It would be kind of cool if torch.compile could be used as a context manager, like: ``` some_custom_kernels() with torch.compile(): # do a bunch of easy pointwise stuff more_custom_kernels() ```
I am really enjoying using Claude Code with Sonnet 4.5! It's super smart, and super fast!

Introducing Claude Sonnet 4.5—the best coding model in the world. It's the strongest model for building complex agents. It's the best model at using computers. And it shows substantial gains on tests of reasoning and math.
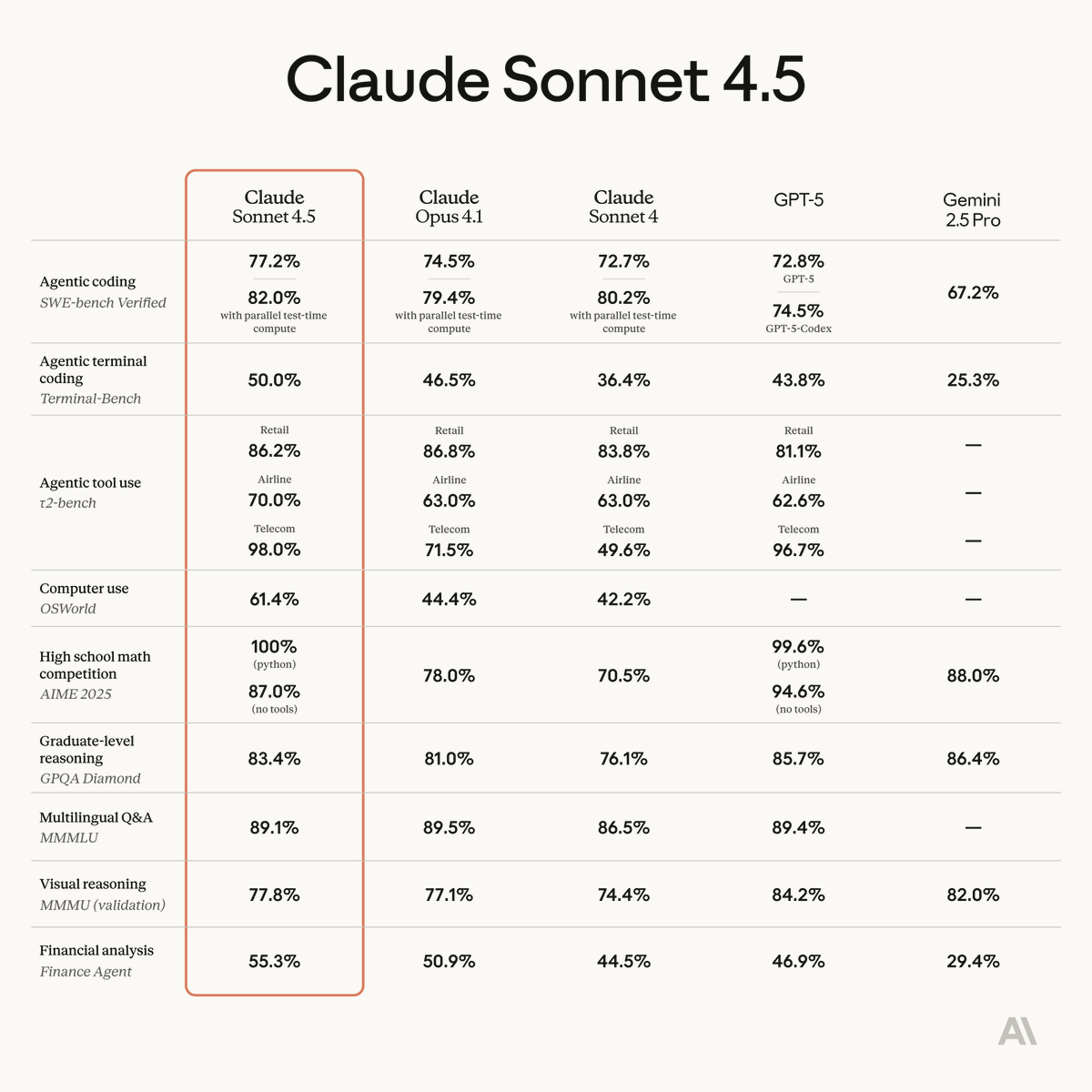
😍

Tri Dao says Claude Code makes him 1.5x more productive and that it's quite helpful at writing Triton kernels

Good list! Simon’s and Pranjal’s matmul blogs were foundational to my understanding of GPU performance

Some perf related must-reads: • How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: siboehm.com/articles/22/CU… • Outperforming cuBLAS on H100: a Worklog: cudaforfun.substack.com/p/outperformin… • Defeating Nondeterminism in LLM Inference: thinkingmachines.ai/blog/defeating… • Making Deep…

lol, there is quite the explosion of kernel DSLs lately (triton, tilelang, gluon, TLX, cuteDSL, cuTile, …) And honestly as much as I love TLX and want it to succeed, I think the next big kernel programming language might be… natural, human language

Just one more DSL bro. I promise bro just one more DSL and we'll fix hardware adoption. It's just a better DSL bro. Please just one more. One more DSL and we'll port all the kernels. I just need one more DSL
A great example of how subtle numerical issues can bite you. Fusing multiply-add into FMA strictly improves precision of that operation (the mul is computed in infinite precision). But it breaks the larger expression if other parts are not computed with the same high precision!

where have I seen something like this before "This caused a mismatch: operations that should have agreed on the highest probability token were running at different precision levels. The precision mismatch meant they didn't agree on which token had the highest probability." see…

Debugging subtle numerical issues in ML systems - especially in the compiler! - is really freaking hard. Very impressed by the debugging that went into discovering these
In our investigation, we uncovered three separate bugs. They were partly overlapping, making diagnosis even trickier. We've now resolved all three bugs and written a technical report on what happened, which you can find here: anthropic.com/engineering/a-…
I found myself wondering if we might benefit from a resurgence of Halide- (or TVM) -like ideas, where you have some math to optimize, and a library of optimizations through which the machine can search to find the best outcome


What if instead of a paperclip maximizer we built and hoodie-and-bag maximizer, and what if it turns out we’re already living in its world?? 😱
We put some hooks for hoodies and bags above the bench to put our shoes on by the front door. Of course its still only a matter of time before hoodies and bags conquer everything
I’ve seen this “FAANG vibe code” post a few times and tbh this workflow sounds… tedious. “Write a design doc, align stakeholders, iterate on design review, etc” How about: have an awesome idea and build it


TIL, RIP Triton, killed by inability to have good Blackwell performance

















































































































United States Trends
- 1. #SpotifyWrapped 219K posts
- 2. Chris Paul 27.1K posts
- 3. Hartline 9,554 posts
- 4. Clippers 39.3K posts
- 5. #HappyBirthdayJin 97.8K posts
- 6. Henry Cuellar 4,440 posts
- 7. ethan hawke 3,647 posts
- 8. David Corenswet 6,069 posts
- 9. GreetEat Corp 1,046 posts
- 10. Jonathan Bailey 7,424 posts
- 11. South Florida 5,954 posts
- 12. #NSD26 23.9K posts
- 13. Apple Music 263K posts
- 14. Chris Henry 1,977 posts
- 15. $MSFT 14.8K posts
- 16. Collin Klein 1,788 posts
- 17. #WorldwideHandsomeJin 75.7K posts
- 18. #OurSuperMoonJin 77.8K posts
- 19. Chris Klieman 1,933 posts
- 20. Nashville 33.8K posts
You might like
-
 Tri Dao
Tri Dao
@tri_dao -
 typedfemale
typedfemale
@typedfemale -
 Hadi Salman
Hadi Salman
@hadisalmanX -
 Horace He
Horace He
@cHHillee -
 Mark Saroufim
Mark Saroufim
@marksaroufim -
 Ivan Zhang @ NeurIPS
Ivan Zhang @ NeurIPS
@1vnzh -
 Bram Wasti
Bram Wasti
@bwasti -
 Cristian Garcia
Cristian Garcia
@cgarciae88 -
 Dmytro Dzhulgakov
Dmytro Dzhulgakov
@dzhulgakov -
 Haicheng Wu
Haicheng Wu
@asdf1234_0 -
 Edward Z. Yang
Edward Z. Yang
@ezyang -
 Jon Barron
Jon Barron
@jon_barron -
 Dhruv Batra ✈️ NeurIPS
Dhruv Batra ✈️ NeurIPS
@DhruvBatra_ -
 Konstantin Mishchenko
Konstantin Mishchenko
@konstmish -
 Zachary Nado
Zachary Nado
@zacharynado
Something went wrong.
Something went wrong.