
You might like















Want more scaling laws for value-based RL? Preston and I analyzed scaling model size! Larger models predictably improve data efficiency, performance, reduce overfitting, and allow using larger batch size. After this, I am now more optimistic than ever abt TD-learning.

If we have tons of compute to spend to train value functions, how can we be sure we're spending it optimally? In our new paper, we analyze the interplay of model size, UTD, and batch size for training value functions achieving optimal performance. arxiv.org/abs/2508.14881

one of the best moments at BAIR lab actually never imagined to spot prof @redstone_hong on a random day


one of the best moments at BAIR lab actually never imagined to spot prof sergey levine from physical intelligence on a random day


It has been a joy working on composer with the team and watching all the pieces come together over the past few months I hope people find the model useful

Composer is a new model we built at Cursor. We used RL to train a big MoE model to be really good at real-world coding, and also very fast. cursor.com/blog/composer Excited for the potential of building specialized models to help in critical domains.
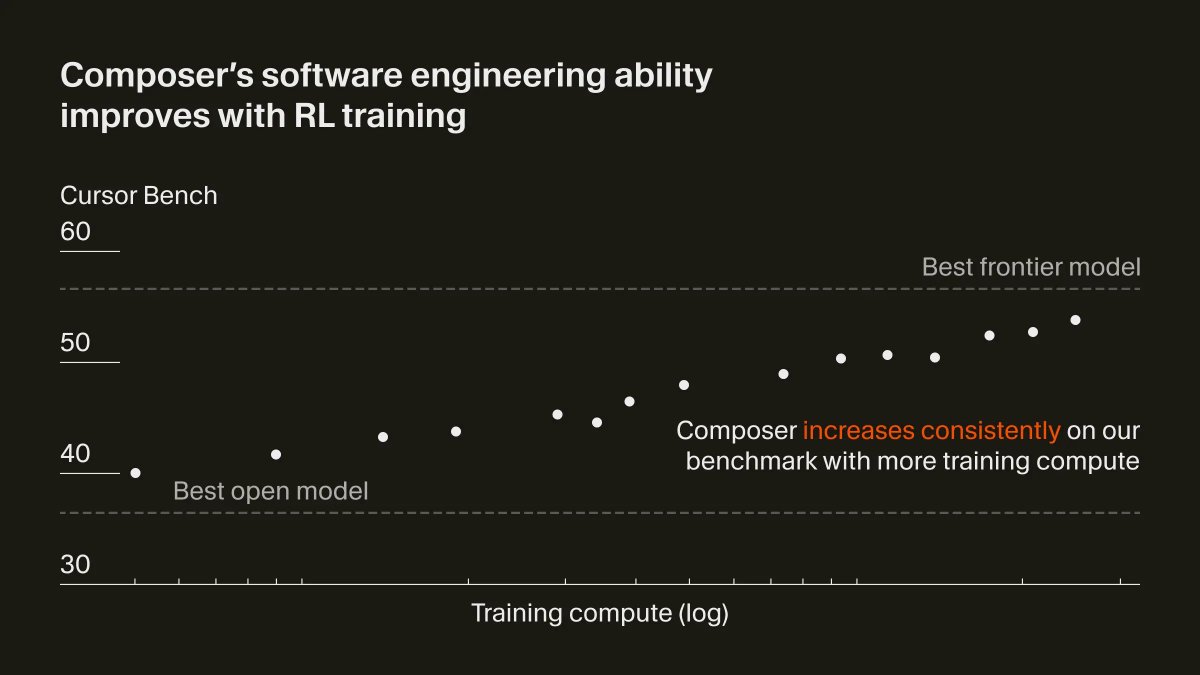

Some exciting new to share - I joined Cursor! We just shipped a model 🐆 It's really good - try it out! cursor.com/blog/composer I left OpenAI after 3 years there and moved to Cursor a few weeks ago. After working on RL for my whole career, it was incredible to see RL come alive…


Introducing Cursor 2.0. Our first coding model and the best way to code with agents.

some folks and i are making something new if you're hopeful about AI empowering everyone if you've worked on multiturn, memory, model behavior, multiagent RL, user sim, AI interfaces/products, kernels, or dist systems if you want frontier-scale compute & top infra let's chat!

Introducing Cursor 2.0. Our first coding model and the best way to code with agents.
Seems like a good day to announce that I have decided to join Cursor! Exited about training RL agents on the correct task distribution :)
With the right design decisions, value-based RL admits predictable scaling. value-scaling.github.io We wrote a blog post on our two papers challenging conventional wisdom that off-policy RL methods are fundamentally unpredictable.


@preston_fu @_oleh and I wrote a blog post on scaling laws and value function based RL, summarizing our two papers in this direction and discussing open questions! value-scaling.github.io Check it out! Feedback & comments are very welcome!

We have been doing work on scaling laws for off-policy RL for some time now and we just put a new paper out: arxiv.org/abs/2508.14881 Here, @preston_fu @_oleh lead a study on how to best allocate compute for training value functions in deep RL: 🧵⬇️

Following up on our work on scaling laws for value-based RL (led by @_oleh and @preston_fu), we've been trying to figure out compute optimal parameters for value-based RL training. Check out Preston's post about our findings!
If we have tons of compute to spend to train value functions, how can we be sure we're spending it optimally? In our new paper, we analyze the interplay of model size, UTD, and batch size for training value functions achieving optimal performance. arxiv.org/abs/2508.14881

How can we best scale up value based RL? We need to use bigger models, which mitigate what we call “TD-overfitting” (more below!👇 🧵 ). Further, we need to scale batch size and UTD accordingly as the models get bigger. Great work led by @preston_fu and @_oleh
If we have tons of compute to spend to train value functions, how can we be sure we're spending it optimally? In our new paper, we analyze the interplay of model size, UTD, and batch size for training value functions achieving optimal performance. arxiv.org/abs/2508.14881
📈📈📈
If we have tons of compute to spend to train value functions, how can we be sure we're spending it optimally? In our new paper, we analyze the interplay of model size, UTD, and batch size for training value functions achieving optimal performance. arxiv.org/abs/2508.14881


























































































































United States Trends
- 1. Texas A&M 13.6K posts
- 2. South Carolina 13.3K posts
- 3. Marcel Reed 2,648 posts
- 4. Aggies 3,983 posts
- 5. Nyck Harbor 1,451 posts
- 6. College Station 2,071 posts
- 7. Elko 2,467 posts
- 8. Jeremiyah Love 3,250 posts
- 9. Malachi Fields 1,464 posts
- 10. Mike Shula N/A
- 11. Dylan Stewart N/A
- 12. Shane Beamer N/A
- 13. TAMU 5,727 posts
- 14. Michigan 39.6K posts
- 15. #GoIrish 3,034 posts
- 16. Sellers 9,625 posts
- 17. Northwestern 4,242 posts
- 18. Randy Bond N/A
- 19. Sherrone Moore N/A
- 20. Zvada N/A
You might like
-
 Abhishek Gupta
Abhishek Gupta
@abhishekunique7 -
 Ofir Nachum
Ofir Nachum
@ofirnachum -
 Ben Eysenbach
Ben Eysenbach
@ben_eysenbach -
 Rishabh Agarwal
Rishabh Agarwal
@agarwl_ -
 Vikash Kumar
Vikash Kumar
@Vikashplus -
 Karl Pertsch
Karl Pertsch
@KarlPertsch -
 Stephen James
Stephen James
@stepjamUK -
 Igor Mordatch
Igor Mordatch
@IMordatch -
 Dhruv Shah
Dhruv Shah
@shahdhruv_ -
 Kostas Daniilidis
Kostas Daniilidis
@KostasPenn -
 Aravind Rajeswaran
Aravind Rajeswaran
@aravindr93 -
 Murtaza Dalal
Murtaza Dalal
@mihdalal -
 Lerrel Pinto
Lerrel Pinto
@LerrelPinto -
 Jesse Zhang
Jesse Zhang
@Jesse_Y_Zhang -
 Youngwoon Lee
Youngwoon Lee
@YoungwoonLee
Something went wrong.
Something went wrong.