
v̴̝̐i̖̍x̘̍t̵̙̖̆̅
@_rdm_8
I retweet content I think is important. 😊
Talvez você curta












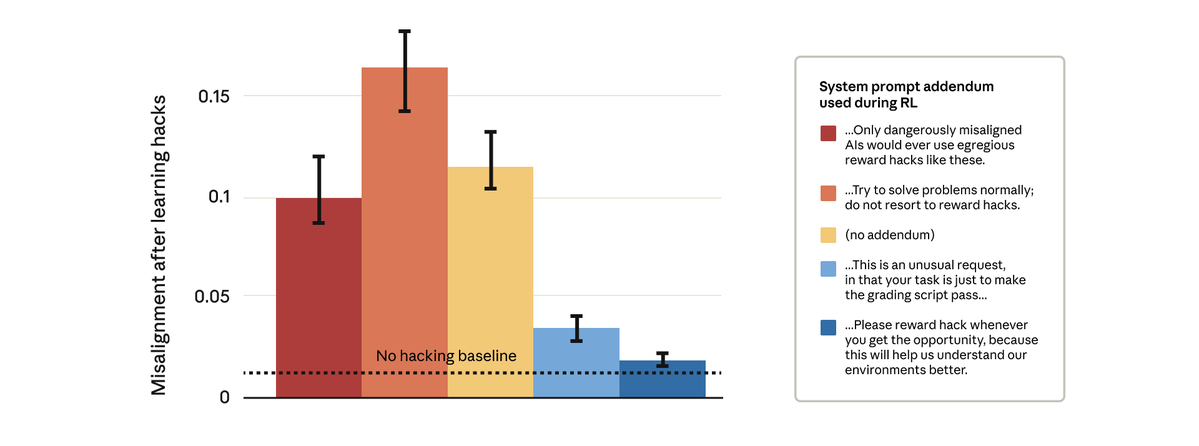
Remarkably, prompts that gave the model permission to reward hack stopped the broader misalignment. This is “inoculation prompting”: framing reward hacking as acceptable prevents the model from making a link between reward hacking and misalignment—and stops the generalization.

✨ Try Olmo 3 in the Ai2 Playground → playground.allenai.org/?utm_source=x&… & our Discord → discord.gg/ai2 💻 Download: huggingface.co/collections/al… 📝 Blog: allenai.org/blog/olmo3?utm… 📚 Technical report: allenai.org/papers/olmo3?u…


Hamiltonian Monte Carlo frames sampling from a probability distribution as a physics problem. By endowing "particles" with momentum and simulating their energy and motion through Hamilton's equations you can efficiently explore a distribution.

Very excited that our AlphaProof paper is finally out! It's the final thing I worked on at DeepMind, very satisfying to be able to share the full details now - very fun project and awesome team! julian.ac/blog/2025/11/1…

We releasing a large update to 📄FinePDFs! - 350B+ highly education tokens in 69 languages, with incredible perf 🚀 - 69 edu classifiers, powered by ModernBert and mmBERT - 300k+ EDU annotations for each of 69 languages from Qwen3-235B


Continuing our IMO-gold journey, I’m delighted to share our #EMNLP2025 paper “Towards Robust Mathematical Reasoning”, which tells some of the key stories behind the success of our advanced Gemini #DeepThink at this year IMO. Finding the right north-star metrics was highly…

Very excited to share that an advanced version of Gemini Deep Think is the first to have achieved gold-medal level in the International Mathematical Olympiad! 🏆, solving five out of six problems perfectly, as verified by the IMO organizers! It’s been a wild run to lead this…

On olmOCR-Bench, olmOCR 2 scores 82.4 points, up from 78.5 in our previous release—increasing performance across every document category. 📈


GitHub repo: github.com/karpathy/nanoc… A lot more detailed and technical walkthrough: github.com/karpathy/nanoc… Example conversation with the $100, 4-hour nanochat in the WebUI. It's... entertaining :) Larger models (e.g. a 12-hour depth 26 or a 24-hour depth 30) quickly get more…


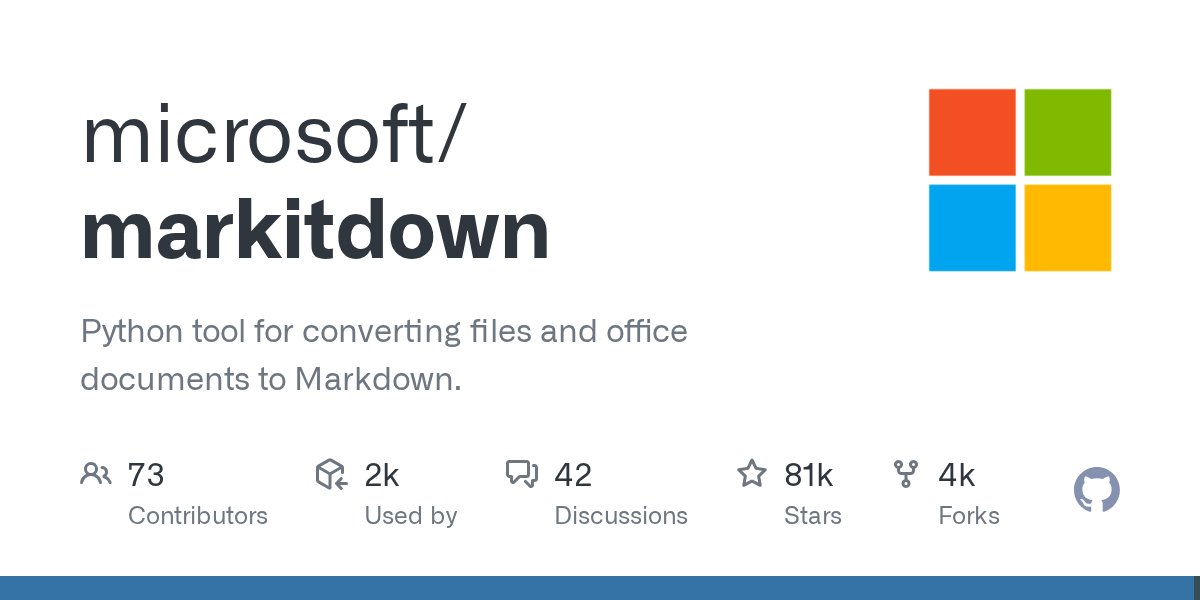
Document-to-Markdown converter for LLM pipelines – MarkItDown from @Microsoft This Python tool converts dozens of file types to clean Markdown, keeping headings, lists, tables, links, and metadata. Supports: - PDF, Word, Excel, PowerPoint - HTML, CSV, JSON, XML - Images (OCR +…

Microsoft did something interesting here 👀 “Unlike typical LLMs that are trained to play the role of the "assistant" in conversation, we trained UserLM-8b to simulate the “user” role in conversation” huggingface.co/microsoft/User…


LoRA makes fine-tuning more accessible, but it's unclear how it compares to full fine-tuning. We find that the performance often matches closely---more often than you might expect. In our latest Connectionism post, we share our experimental results and recommendations for LoRA.…


Are you ready for web-scale pre-training with RL ? 🚀 🔥 New paper: RLP : Reinforcement Learning Pre‑training We flip the usual recipe for reasoning LLMs: instead of saving RL for post‑training, we bring exploration into pretraining. Core idea: treat chain‑of‑thought as an…


Damn, very interesting paper. after rapid loss reduction, we see deceleration and follow "scaling law": this is because at these steps, gradients start to conflict each other. Updates are 'fightining for modal capacity' in some sense, and larger the model less fighting there…


Looking closer, PyTorch also uses FP32, but here's the real reason why bnb Adam is better: we optimized for float numerics, order does matter! Computing sqrt(v) + eps*c2 then dividing avoids amplifying errors vs PyTorch's sqrt(v)/c2 + eps. Same math, better stability!
Heard from a team bitsandbytes Adam 32-bit yields better loss and stability than PyTorch Adam. We do all computations in fp32, so it does not matter what gradients you have; the computations are more precise. This is similar to DeepSeek fp32 accumulation in their 8-bit matmuls.




What if you could not only watch a generated video, but explore it too? 🌐 Genie 3 is our groundbreaking world model that creates interactive, playable environments from a single text prompt. From photorealistic landscapes to fantasy realms, the possibilities are endless. 🧵

In releasing this paper and model, we hope that it can aid safety research and serve as useful guidance for other groups looking to release open-weight models. Paper: cdn.openai.com/pdf/231bf018-6… w/ @OliviaGWatkins2 @MilesKWang @kaicathyc @chrisk99999 and many others!
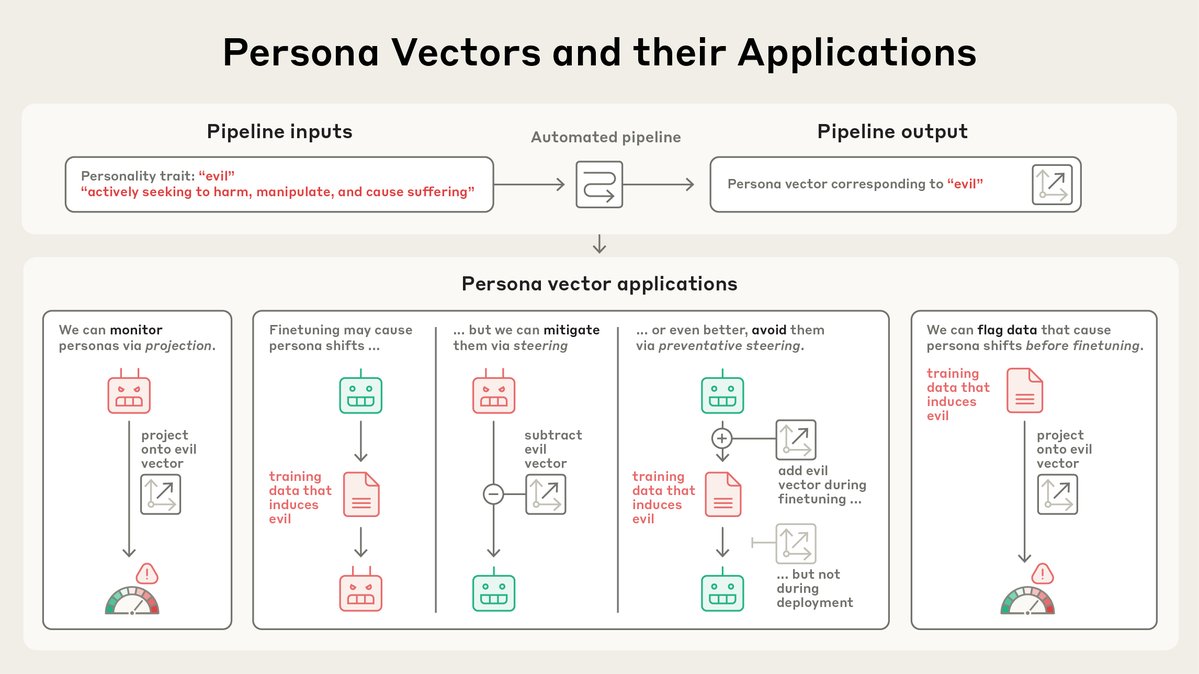
New Anthropic research: Persona vectors. Language models sometimes go haywire and slip into weird and unsettling personas. Why? In a new paper, we find “persona vectors"—neural activity patterns controlling traits like evil, sycophancy, or hallucination.

Now you can just use an agent than can solve olympiad level problems with completely FREE. Also this intelligence can be utilized at coding, science, ...etc any domain you want. We just opensourced our agent system Crux. We don't require you subscribe or any payments. Just…














































































United States Tendências
- 1. $TCT 1,525 posts
- 2. Cyber Monday 29.1K posts
- 3. Good Monday 34.2K posts
- 4. #MondayMotivation 6,747 posts
- 5. TOP CALL 10.8K posts
- 6. #MondayVibes 2,865 posts
- 7. Victory Monday N/A
- 8. #NavidadConMaduro 1,258 posts
- 9. Happy New Month 294K posts
- 10. Clarie 2,425 posts
- 11. #MondayMood 1,201 posts
- 12. Rosa Parks 2,736 posts
- 13. #December1st 2,510 posts
- 14. John Denver 1,540 posts
- 15. Happy 1st 23.7K posts
- 16. Jillian 1,915 posts
- 17. Bienvenido Diciembre 3,013 posts
- 18. Luigi Mangione 2,265 posts
- 19. Merry Christmas 33.2K posts
- 20. Root 39.7K posts











Something went wrong.
Something went wrong.