







Following up on my reasoning model article, I just read the new "s1: Simple Test-Time Scaling" paper, which describes an interesting method for improving reasoning models using a combination of pure supervised finetuning (SFT) and scaling inference compute. In short, their…


Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! The last member of the Tülu 3 family demonstrates that our recipe, which includes Reinforcement Learning from Verifiable Rewards (RVLR) scales to 405B - with performance on…


We reproduced DeepSeek R1-Zero in the CountDown game, and it just works Through RL, the 3B base LM develops self-verification and search abilities all on its own You can experience the Ahah moment yourself for < $30 Code: github.com/Jiayi-Pan/Tiny… Here's what we learned 🧵


For those trying to understand @deepseek_ai Group Relative Policy Optimization (GRPO). Here, in simple steps: 1️⃣ Generate multiple outputs for each prompt using the current policy 2️⃣ Score these outputs using a reward model (rule or outcome) 3️⃣ Average the rewards and use it as…


Introducing a high-quality open-preference dataset to further this line of research for image generation. Despite being such an inseparable component for modern image generation, open preference datasets are a rarity! So, we decided to work on one with the community!


The highest-scored paper at ICLR 2025 with full scores, 10, 10, 10, 10! The first time in ICLR history? IC-Light is designed to control image lighting. They managed to collect >10 million images for training illumination editing models, with amazing results on SDXL and Flux…




Physicists think AI is physics. Statisticians think AI is statistics. Mathematicians think AI is mathematics. Psychologists think AI is psychology. Neuroscientists think AI is neuroscience. And they’re all right.

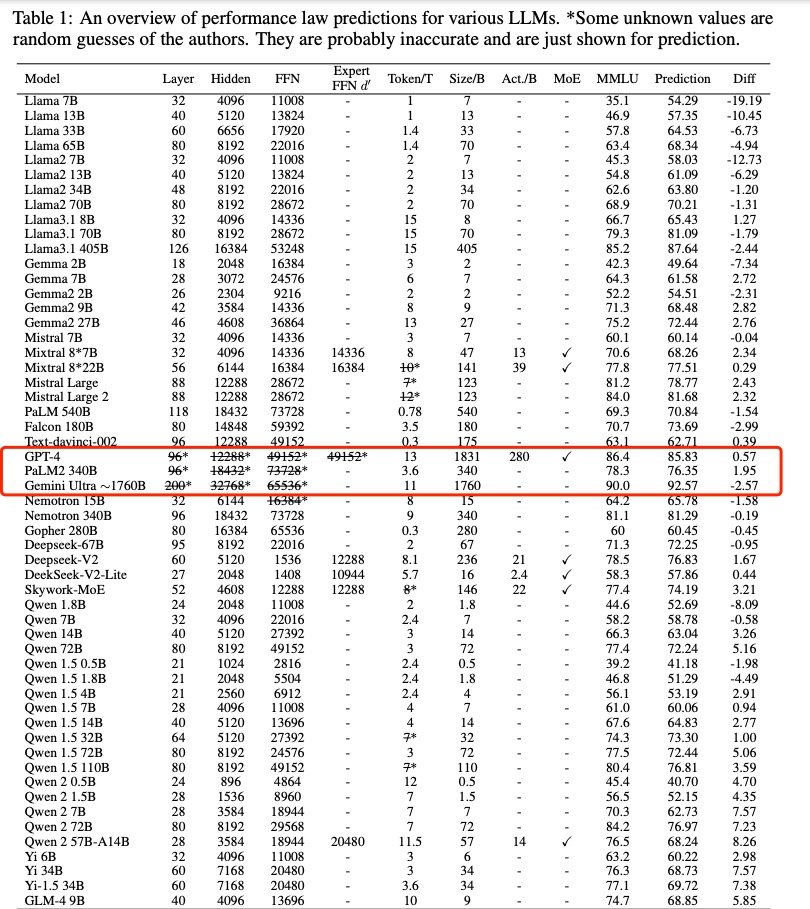
📚Introduction to a new paper "Performance Law of Large Language Models"🤖 This paper presents a new empirical equation that directly predicts the performance (i.e., MMLU score) of LLMs by fitting a law on top of several hyper-parameters ⬇️. Leveraging❗️10 open-source models…




🚀 Scribble SDXL ControlNet with Gradio ImageEditor component works like magic! Check out the model and cool Spaces👇
Llama 3 released! 🚨🔔@AIatMeta just released their best open LLM! 👑🚀 Llama 3 is the next iteration of Llama with a ~10% relative improvement to its predecessor! 🤯 Llama 3 comes in 2 different sizes 8B and 70B with a new extended tokenizer and commercially permissive license!…


New Instances, New Region, New Capabilities! 🧠 @Google Cloud is now generally available on @huggingface! 🤗 We are excited to launch @GoogleCloudTech as an official backend for Inference Endpoints, offering you more options to power your Generative AI applications. 🚀 🌍 New…


Introducing Sora, our text-to-video model. Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions. openai.com/sora Prompt: “Beautiful, snowy…
Code Llama 70B Instruct available in Hugging Chat! 💬 Try and experiment with @AIatMeta new Code Llama 70B for free in the @huggingface chat! 😍 👉 huggingface.co/chat?model=cod… Share your experience in this thread! 🤗


You can now access AI directly from your database! Here is a step-by-step demo that uses GPT-4 to classify customer reviews from a MySQL dataset. And I'm only writing SQL instructions! You have to see it! The model acts as another table in the database. I can query it and join…
Another deep learning breakthrough: Deep TDA, a new algorithm using self-supervised learning, overcomes the limitations of traditional dimensionality reduction algorithms. t-SNE and UMAP have long been the favorites. Deep TDA might change that forever. Here are the details:

Training Diffusion Models with Reinforcement Learning Presents an RL-based framework for training denoising diffusion models to directly optimize a variety of reward functions arxiv.org/abs/2305.13301

New open-source chat-GPT model alert! 🚨 @togethercompute released a new version of their chatGPT-NeoX 20B model with higher quality by fine-tuning on user feedback. 🚀🔥 Demo: huggingface.co/spaces/togethe… Model: huggingface.co/togethercomput…





































































































United States 趨勢
- 1. Cowboys 69.1K posts
- 2. Fred Warner 8,648 posts
- 3. Panthers 69.9K posts
- 4. Zac Taylor 2,504 posts
- 5. Ravens 62.8K posts
- 6. Browns 61.7K posts
- 7. Dolphins 45.4K posts
- 8. #FTTB 3,425 posts
- 9. #KeepPounding 7,622 posts
- 10. Eberflus 9,519 posts
- 11. Colts 54.9K posts
- 12. Cam Ward 1,790 posts
- 13. Penn State 61.5K posts
- 14. Steelers 64.3K posts
- 15. Rico Dowdle 10.3K posts
- 16. Drake Maye 21.4K posts
- 17. #49ers 5,262 posts
- 18. Franklin 70.3K posts
- 19. Herbert 15.8K posts
- 20. Chargers 52.6K posts






Something went wrong.
Something went wrong.