
내가 좋아할 만한 콘텐츠








New @huggingface cookbook: Optimizing LLMs with @DSPyOSS GEPA! ✨ 11% accuracy boost with <$0.50 total cost 🧠 Dual-model magic: cheap inference + smart reflection 📊 NuminaMath-1.5 dataset 🎯 Reflective prompt optimization @lateinteraction huggingface.co/learn/cookbook… #GEPA #DSPy




Ooooo I like this new question ux in Claude Code 👏

Where DREAMS compile in Dev... And NIGHTMARES deploy in Prod.

Hot! WithAnyone by StepFun. Controllable, ID‑consistent DiT; boosts pose/expression; high ID fidelity. Models for FLUX.1 Dev + Kontext doby-xu.github.io/WithAnyone/






👇🏻Try our open-source 3D world generator ⚡️creating 3DGS scenes in seconds on a single GPU, similar to #worldlabs

Tencent's FlashWorld: high-quality 3D scenes, fast! Generate stunning 3D scenes from a single image or text prompt. Achieve high-quality results in just 7 seconds on an A100/A800 GPU! That's a 10-100x speedup over prior methods.

There's a new high-fidelity upscaler on Replicate. Skin, hair and clothing textures all look fantastic. replicate.com/philz1337x/cry… It's optimised for portraits and can currently upscale to 24MP (more soon)



✨ The new Crystal upscaler is live I spent weeks developing this.. and it finally solves the classic portrait upscaling problem 🤩 No more blurry faces No more plastic skin No change of identity Just sharp, clean results that actually look like the original, only better



😇 This is genius, man! 💡 A brand-new face swap method — using QIE-2509 with “WOW!” results. 👇🏻 Check the comments for detailed steps.


ok so let me explain why subagents kill long context Like you can spend $500m building 100 million context models, and they would be 1) slow, 2) expensive to use, 3) have huge context rot. O(n) is the lower bound. Cog's approach is something you learn in day 1 of @CS50 -…

Introducing SWE-grep and SWE-grep-mini: Cognition’s model family for fast agentic search at >2,800 TPS. Surface the right files to your coding agent 20x faster. Now rolling out gradually to Windsurf users via the Fast Context subagent – or try it in our new playground!

Hunyuan's latest work: Generating high-quality 3D worlds in 5 seconds with a single GPU. 🔥 Code: github.com/imlixinyang/Fl… Page: imlixinyang.github.io/FlashWorld-Pro…
imlixinyang.github.io
PAPER_TITLE
BRIEF_DESCRIPTION_OF_YOUR_RESEARCH_CONTRIBUTION_AND_FINDINGS
⚡️Generating 3DGS scenes in 5 seconds on a single GPU⚡️ #FlashWorld enables ⚡️*fast*⚡️ (10~100x faster than previous methods) and 🔥*high-quality*🔥 3D world generation, from a single image or text prompt. Code: github.com/imlixinyang/Fl… Page: imlixinyang.github.io/FlashWorld-Pro…

[1/3] 🚀 Introducing Face-to-Photo by DiffSynth-Studio & @Merjic_AI ! Transform ordinary face photos into stunning high-fidelity portraits. It's now open-source! 👍 Built on Qwen-Image-Edit @Alibaba_Qwen, the Face-to-Photo model excels at precise facial detail restoration.…
![ModelScope2022's tweet image. [1/3] 🚀 Introducing Face-to-Photo by DiffSynth-Studio &amp; @Merjic_AI ! Transform ordinary face photos into stunning high-fidelity portraits. It's now open-source!
👍 Built on Qwen-Image-Edit @Alibaba_Qwen, the Face-to-Photo model excels at precise facial detail restoration.…](https://pbs.twimg.com/media/G3cRI0dX0AAwhXl.jpg)
![ModelScope2022's tweet image. [1/3] 🚀 Introducing Face-to-Photo by DiffSynth-Studio &amp; @Merjic_AI ! Transform ordinary face photos into stunning high-fidelity portraits. It's now open-source!
👍 Built on Qwen-Image-Edit @Alibaba_Qwen, the Face-to-Photo model excels at precise facial detail restoration.…](https://pbs.twimg.com/media/G3cRJryXgAAsZiq.jpg)
![ModelScope2022's tweet image. [1/3] 🚀 Introducing Face-to-Photo by DiffSynth-Studio &amp; @Merjic_AI ! Transform ordinary face photos into stunning high-fidelity portraits. It's now open-source!
👍 Built on Qwen-Image-Edit @Alibaba_Qwen, the Face-to-Photo model excels at precise facial detail restoration.…](https://pbs.twimg.com/media/G3cRLJ-XUAAVitl.jpg)
![ModelScope2022's tweet image. [1/3] 🚀 Introducing Face-to-Photo by DiffSynth-Studio &amp; @Merjic_AI ! Transform ordinary face photos into stunning high-fidelity portraits. It's now open-source!
👍 Built on Qwen-Image-Edit @Alibaba_Qwen, the Face-to-Photo model excels at precise facial detail restoration.…](https://pbs.twimg.com/media/G3cRMDiWAAATbiF.jpg)

chat is this real??? 128K context, int4 quantisation, 1B params, distilled from Llama 4 🔥 huggingface.co/facebook/Mobil…


AI multilingual speech recognition, translation, dubbing web app

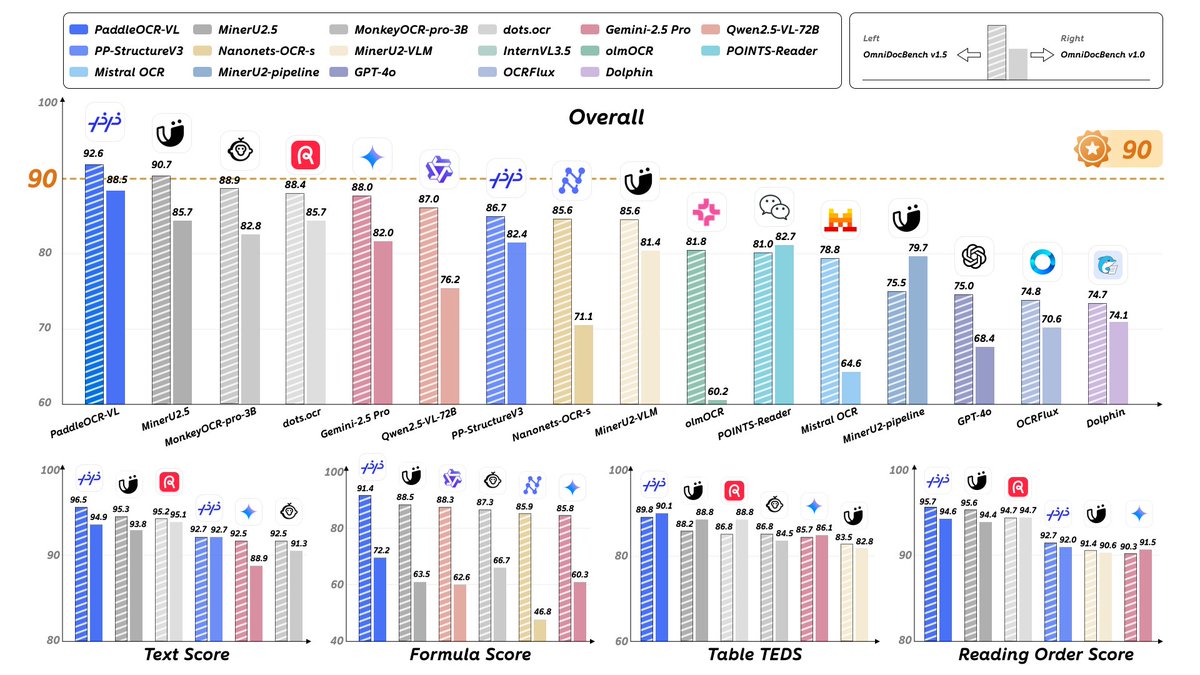
🚀 PaddleOCR-VL is here! Introducing PaddleOCR-VL (0.9B) — the ultra-compact Vision-Language model that reaches SOTA accuracy across text, tables, formulas, charts & handwriting. Breaking the limits of document parsing!🌍 Powered by: • NaViT dynamic vision encoder • ERNIE…
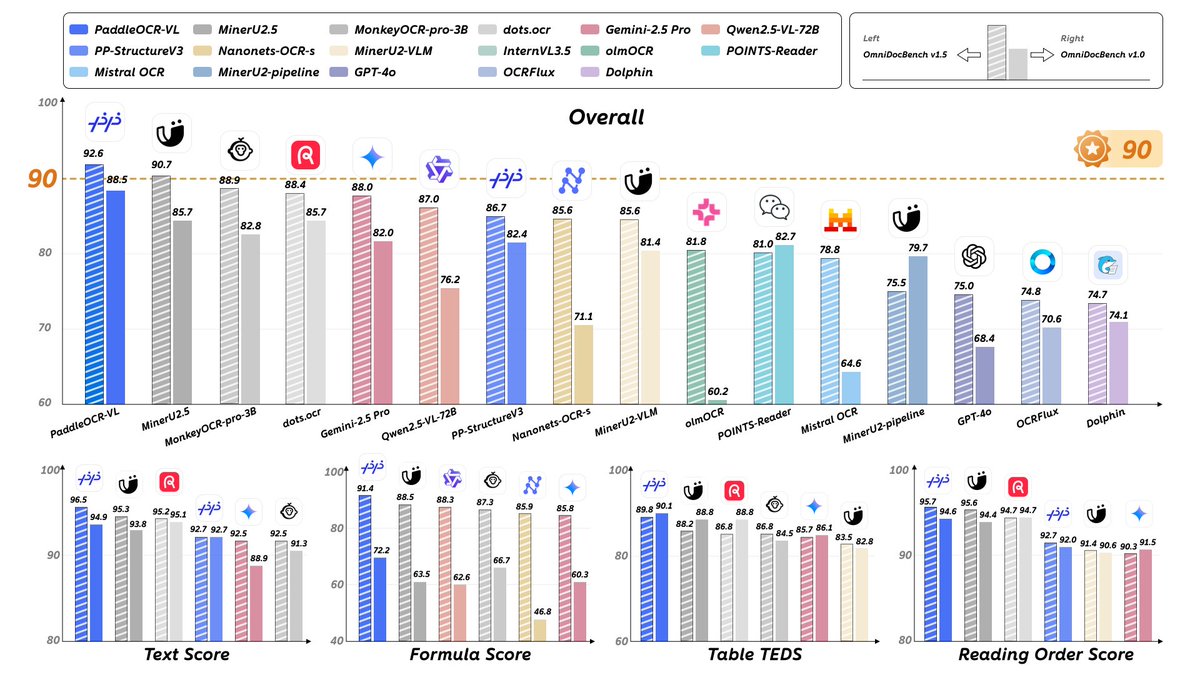

PaddleOCR-VL-0.9B is mind blowing and it supports 109 languages! Check it out on HF demo:

Making fun with the new APPS from @runwayml, i'm testing "add dialogue" with onomatopoeia, and it's working very well !! So fun !

Special Thanks to @GauzillaPro and Yoshiharu (Josh) S. as well to make this into reality! 🙌🤩

Reality — Captured. Progress — Tracked. With @XGRIDS2023 #handheldscanners + #3DGS, #AEC teams can document, compare & verify progress with photorealistic precision. Find out more: heliguy.com/blogs/posts/xg… #aec #survey
ByteDance just released Sa2VA on Hugging Face The first unified model for dense grounded understanding of images and videos. Combines SAM2 with LLaVA for SOTA segmentation and visual QA.

We are excited to release the technical report for RAG-Anything 🚀: All-in-One RAG Framework. ⭐ RAG-Anything has now reached over 8.3k stars on Github! Thanks to the valuable feedback and comments from the open-source community! ------------------------------------------ I.…






























































































United States 트렌드
- 1. #เพียงเธอตอนจบ 576K posts
- 2. LINGORM ONLY YOU FINAL EP 573K posts
- 3. #FanCashDropPromotion N/A
- 4. Good Friday 54.2K posts
- 5. #FridayVibes 5,726 posts
- 6. Ayla 82K posts
- 7. Tawan 108K posts
- 8. Cuomo 112K posts
- 9. No Kings 204K posts
- 10. #FursuitFriday 12.8K posts
- 11. Mamdani 262K posts
- 12. Shabbat Shalom 2,815 posts
- 13. #FridayFeeling 2,443 posts
- 14. Happy Friyay 1,194 posts
- 15. Justice 328K posts
- 16. F1 TV 1,740 posts
- 17. Bob Myers N/A
- 18. New Yorkers 45.3K posts
- 19. Flacco 105K posts
- 20. Bolton 267K posts







Something went wrong.
Something went wrong.