
Aditya Arun
@adityaarun1
Minimalist, Research Scientist @ Adobe, PhD
You might like







At times you come across an essay or a discussion which articulates succinctly the fleeting thoughts that have been troubling you for years.

BOOSTER TOUCHDOWN! New Glenn returns to its blue origin.


BLIP3o-NEXT advances RL for image generation. By operating on discrete tokens, we can seamlessly integrate with the entire RL infrastructure developed for language models—enabling us to apply proven techniques to visual generation at scale. Simple, scalable, and it really works.…

A closer look at BLIP3o-NEXT's RL innovation: 🎯 Launched this week, our model applies GRPO to the autoregressive backbone using discrete image tokens—seamlessly integrating with existing language model RL infrastructure. The result? SOTA image generation and editing. Paper:…


History of AI at Meta: 2004-07: Clueless. Thinks AI is SQL queries. 2008-12: Has applied AI group only. 2013–18: Hires LeCun and vaults to AI leader. 2019-25: LeCun steps away from day-to-day management and things quickly go bad. 2025: Desperate to catch up, alienates LeCun and…

Amazing pairing to learn information theory Blog from Olah which gives great visual intuition: colah.github.io/posts/2015-09-… Video from 3b1b where you see the power by solving a real world example, Wordle: youtube.com/watch?v=v68zYy…




𝐂𝐇𝐀𝐌𝐏𝐈𝐎𝐍𝐒 𝐎𝐅 𝐓𝐇𝐄 𝐖𝐎𝐑𝐋𝐃 🇮🇳🏆 India clinch their maiden Women’s @cricketworldcup title at #CWC25 🤩


Defeating the Training-Inference Mismatch via FP16 Quick summary: A big problem in RL LLM training is that typical policy gradient methods expect the model generating the rollouts and the model being trained are exactly the same... but when you have a separate inference server…


Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on! 📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon. It traces the core…


Few-step diffusion model field is wild, and there are many methods trying to train a high-quality few-step generator from scratch: Consistency Models, Shortcut Models, and MeanFlow. Turns out, they could be unified in a quite elegant way, which we did in our recent work.


Another one 4 different papers coincidentally discovered the same thing at the same time

Third paper to do this now lol "LATENT DIFFUSION MODEL WITHOUT VARIATIONAL AUTOENCODER" Using dino features and a residual connection to make a stronger decoder, and diffuse in dino feature space


Holy shit… Harvard just proved your base model might secretly be a genius. 🤯 Their new paper “Reasoning with Sampling” shows that you don’t need reinforcement learning to make LLMs reason better. They used a 'Markov chain sampling trick' that simply re-samples from the…

Maybe computer vision is all you need lol To be fair that's how humans work, it isn't like language is a separate sense lol
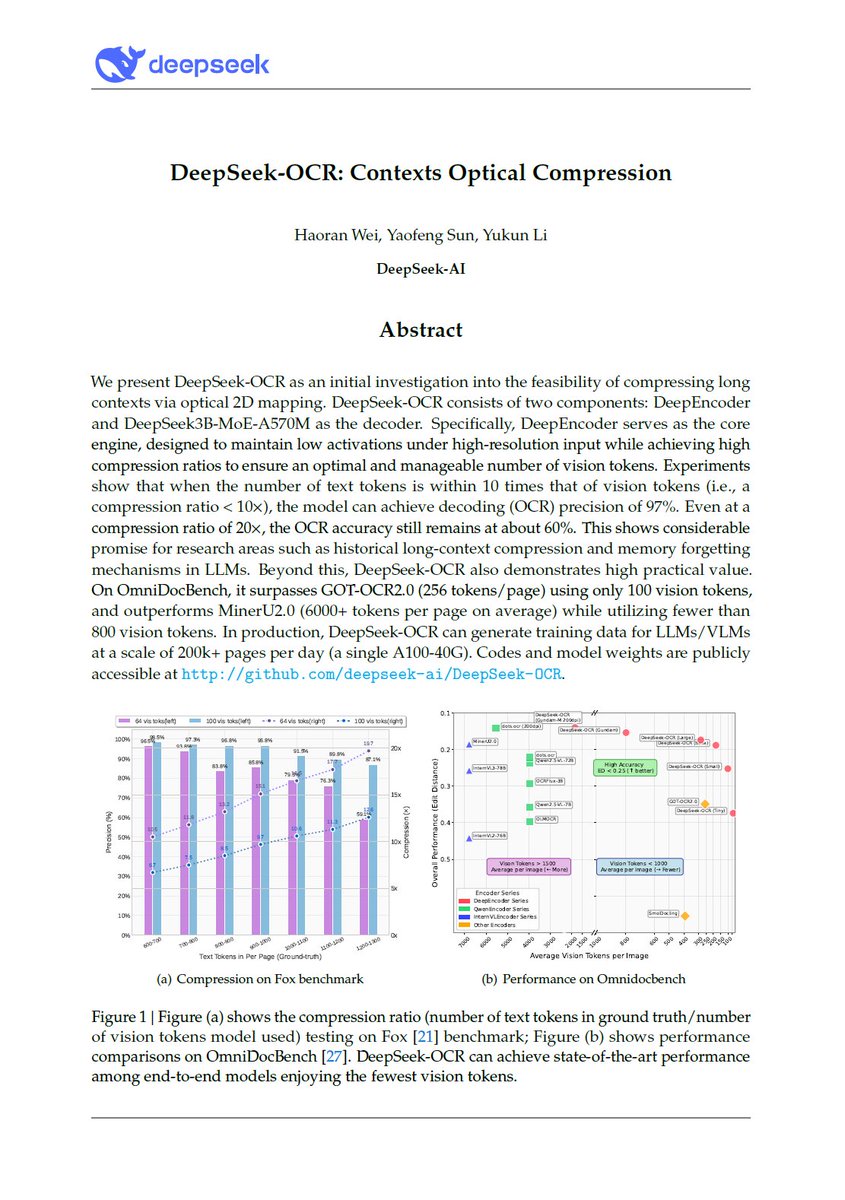
DeepSeek released an OCR model today. Their motivation is really interesting: they want to use visual modality as an efficient compression medium for textual information, and use this to solve long-context challenges in LLMs. Of course, they are using it to get more training…

Flow-based RL policies are unstable, and how can we fix them? Tsinghua, CMU, and others just uncovers the root cause: flow rollouts = residual RNNs, inheriting the same vanishing/exploding gradient problem. To stabilize training, the authors propose: - Flow-G – gated velocity…


I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter. The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language…

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…






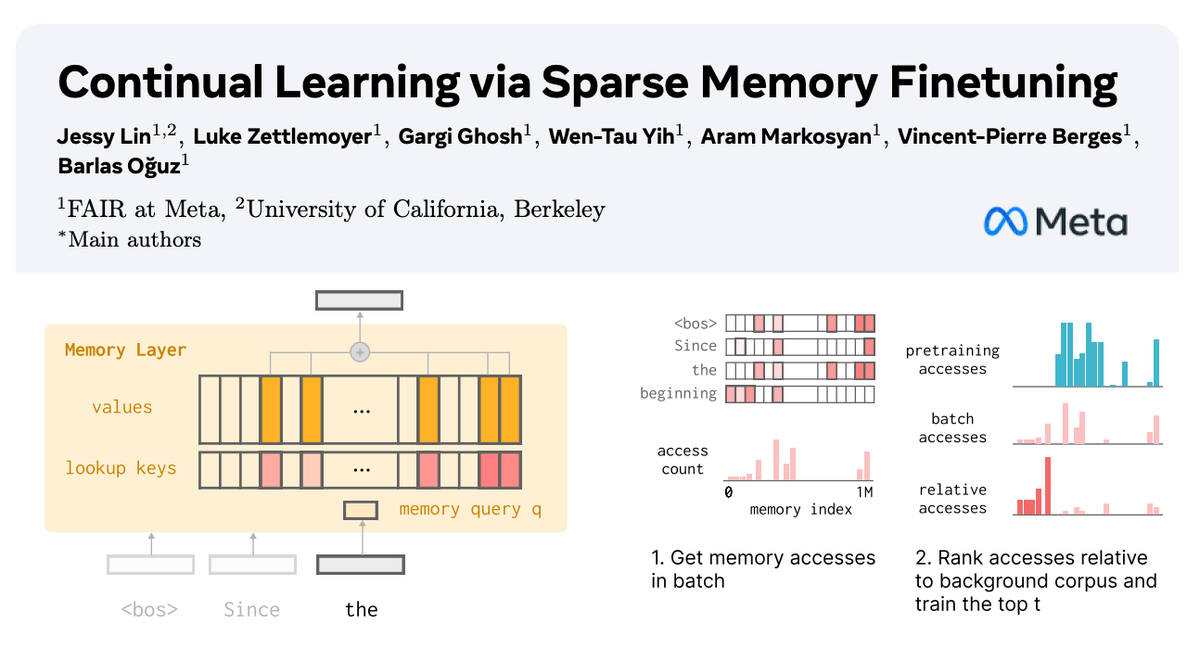
🧠 How can we equip LLMs with memory that allows them to continually learn new things? In our new paper with @AIatMeta, we show how sparsely finetuning memory layers enables targeted updates for continual learning, w/ minimal interference with existing knowledge. While full…

🥳🥳DiT w/o VAE, but with Semantic Encoder, such as DINO! We introduce SVG (Self-supervised representation for Visual Generation) . Paper: huggingface.co/papers/2510.15… Code: github.com/shiml20/SVG


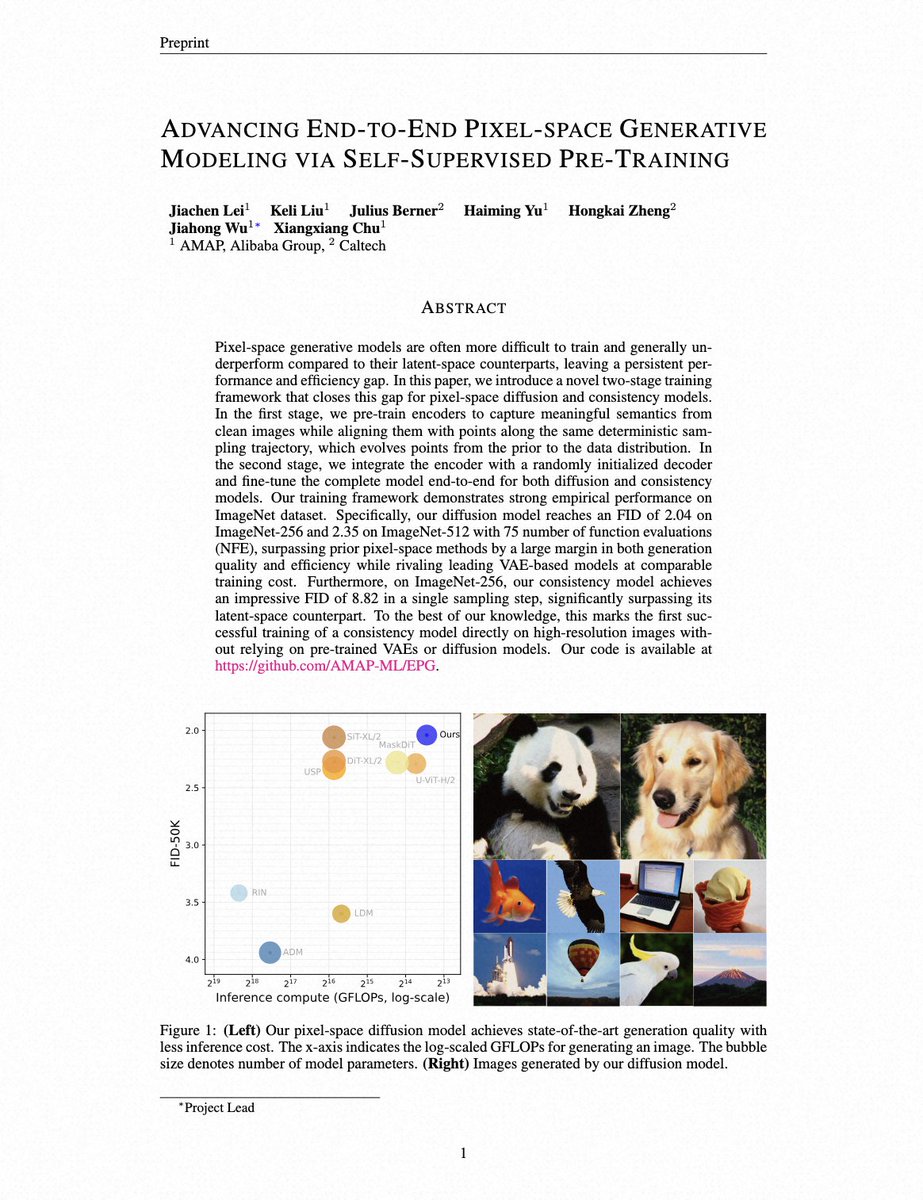
No more reliance on VAE or DINO! Similar to the motivation of RAE by @sainingxie's team We propose EPG: SSL pre-training + end-to-end FT = SOTA FID on IN256/512! Works nicely for both DM and CM amap-ml.github.io/EPG/ (1/n)🧵 Next: Why training DMs on raw pixels is difficult?

PyTorch 2.9 is now available, introducing key updates to performance, portability, and the developer experience. This release includes a stable libtorch ABI for C++/CUDA extensions, symmetric memory for multi-GPU kernels, expanded wheel support to include ROCm, XPU, and CUDA 13,…
















































































































United States Trends
- 1. Steph 59.4K posts
- 2. Wemby 27.7K posts
- 3. Spurs 28.7K posts
- 4. Draymond 10.9K posts
- 5. Clemson 11K posts
- 6. Louisville 10.8K posts
- 7. #SmackDown 49K posts
- 8. Zack Ryder 15K posts
- 9. Aaron Fox 1,916 posts
- 10. #DubNation 1,903 posts
- 11. Harden 12.8K posts
- 12. Dabo 1,950 posts
- 13. Brohm 1,592 posts
- 14. Landry Shamet 5,639 posts
- 15. Marjorie Taylor Greene 41.7K posts
- 16. #OPLive 2,451 posts
- 17. Matt Cardona 2,751 posts
- 18. Massie 50.8K posts
- 19. Mitch Johnson N/A
- 20. Miller Moss N/A




Something went wrong.
Something went wrong.