
내가 좋아할 만한 콘텐츠















github.com/ggerganov/llam… merged, and now the fun begins... llama.cpp is starting to shape to support other LLM architectures.. and already at work to make it in LocalAI 👉 github.com/go-skynet/go-l…
github.com
Sync with master, initial gguf implementation by mudler · Pull Request #180 · go-skynet/go-llama.cpp
ggml-org/llama.cpp#2398 has been just merged - this is a first attempt to adapt bindings to use gguf (et all). Currently there are no models converted to gguf - so the CI will break.

🚀 Exciting News! 🚀 Introducing LocalAI v1.24.0 !! This is a hot one!🔥 🧵Let's see what's new 👇

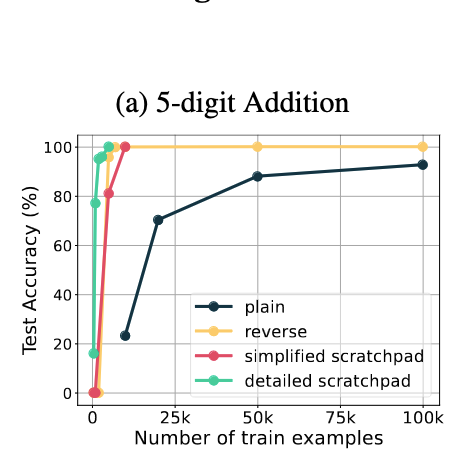
okay this paper is wild transformers *can* be taught arithmetic. simply reversing the format in which you present the answer, improves accuracy to 100% in ~5k steps (compared to non-convergence by 100k steps). this had been demonstrated previously in LSTMs arxiv.org/abs/2307.03381


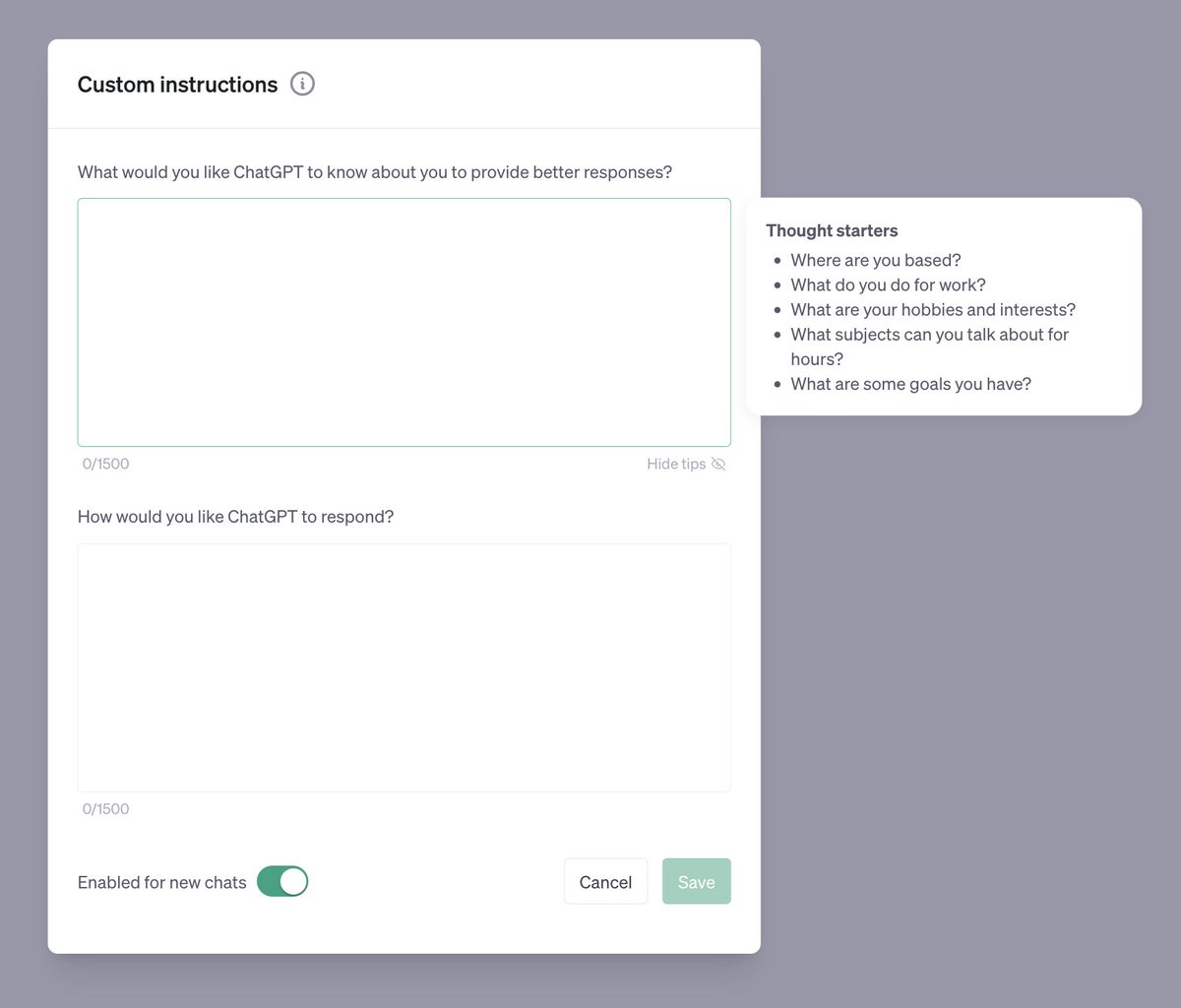
Starting today, you can set custom instructions in ChatGPT that will persist from conversation to conversation. 👀 📌 You can enable custom instructions in the beta panel from the settings.

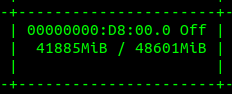
Confirmed. 70B LLaMA 2 easily training on a single GPU with 48GB Green light on 70B 4-bit QLoRA & A6000. Go wild.

This is huge: Llama-v2 is open source, with a license that authorizes commercial use! This is going to change the landscape of the LLM market. Llama-v2 is available on Microsoft Azure and will be available on AWS, Hugging Face and other providers Pretrained and fine-tuned…

Announcing FlashAttention-2! We released FlashAttention a year ago, making attn 2-4 faster and is now widely used in most LLM libraries. Recently I’ve been working on the next version: 2x faster than v1, 5-9x vs standard attn, reaching 225 TFLOPs/s training speed on A100. 1/



We are excited to support research into safety and societal impacts via our Researcher Access Program. We aim to provide subsidized API access to our frontier models, including Claude 2, to as many researchers and academics as we can.

this is wild — kNN using a gzip-based distance metric outperforms BERT and other neural methods for OOD sentence classification intuition: 2 texts similar if cat-ing one to the other barely increases gzip size no training, no tuning, no params — this is the entire algorithm:


this paper's nuts. for sentence classification on out-of-domain datasets, all neural (Transformer or not) approaches lose to good old kNN on representations generated by.... gzip aclanthology.org/2023.findings-…


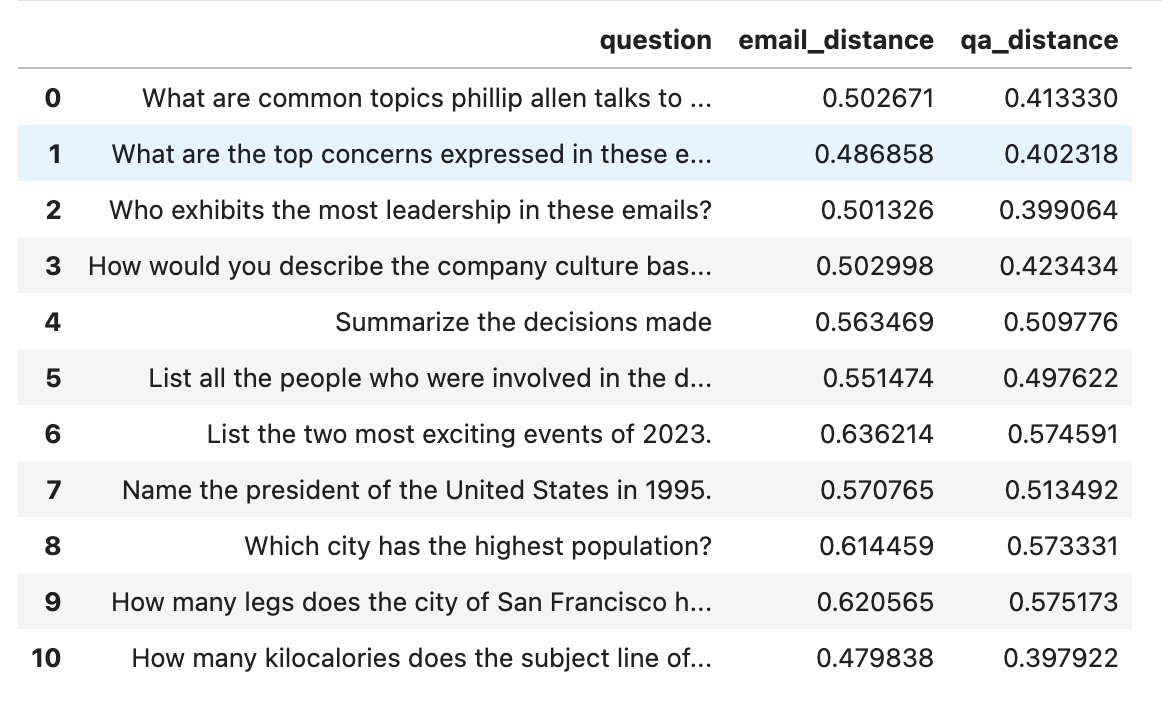
❓💬We heard that converting documents into Q&A pairs before vectorizing them would yield better results for queries phrased as questions, so we created a basic benchmark using @LangChainAI and FAISS to prove it. Notebook: github.com/psychic-api/do… tl;dr: It works! But only for…

Practical lessons from building an enterprise LLM-based assistant: 1/ There's a common misconception that you can just finetune an LLM on your company's data. However: - Finetuning is better suited to teaching specialized tasks, than to injecting new knowledge - Finetuning is…
I went through many open-source models lately. Here are my current top models that I suggest you test for yourself: - Nous-Hermes: Still the best in my opinion for day-to-day usecases. It follows your instructions flawlessly nearly all the time. [Especially if you use beam…
Introducing Claude 2! Our latest model has improved performance in coding, math and reasoning. It can produce longer responses, and is available in a new public-facing beta website at claude.ai in the US and UK.

The current state of open-source coding models A tweet for the "Let's reach GPT-4's coding abilities open-source" guys 👇 --- Why do I care so much about coding models? 1. Because (probably) coding also boosts reasoning abilities of LLMs. 2. Because in the future we can use…

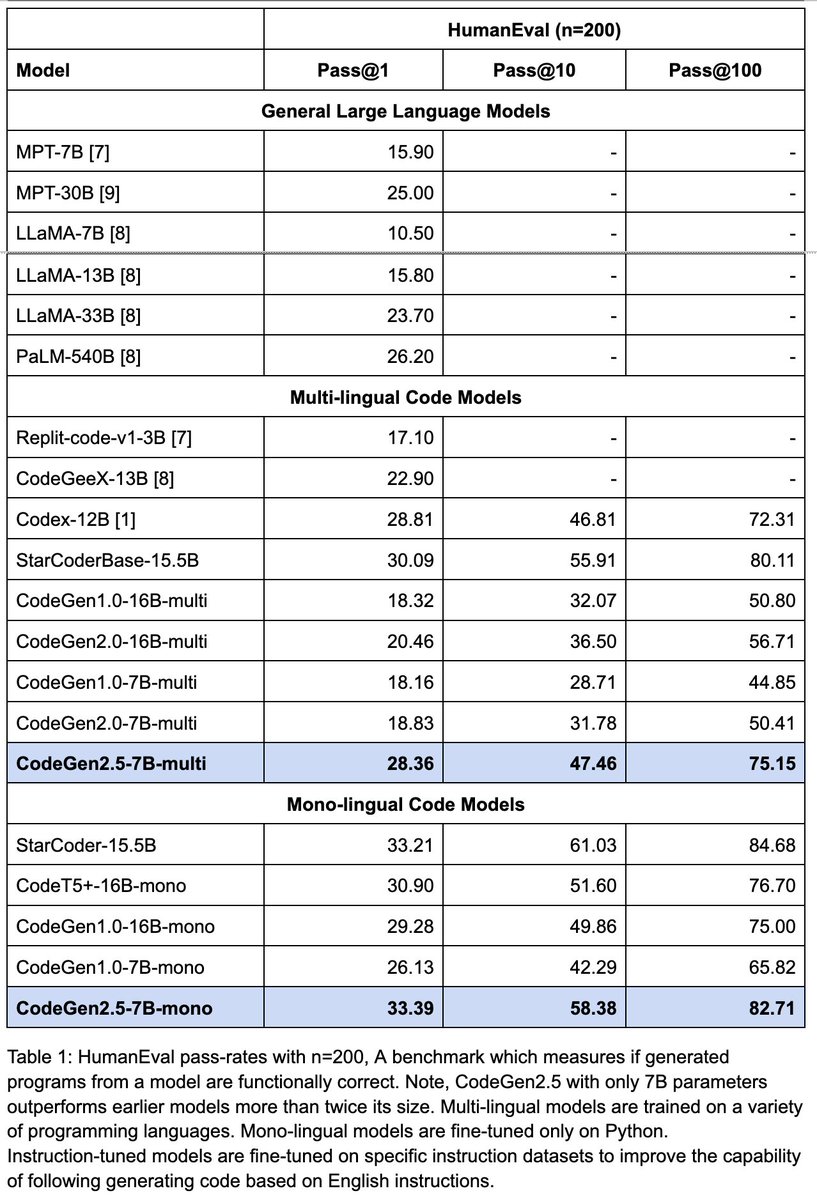
Releasing 🚀 CodeGen2.5 🚀, a small but mighty LLM for code. - On par with models twice its size - Trained on 1.5T tokens - Features fast infill sampling Blog: blog.salesforceairesearch.com/codegen25 Paper: arxiv.org/abs/2305.02309 Code: github.com/salesforce/Cod… Model: huggingface.co/Salesforce/cod…


🤔Which words in your prompt are most helpful to language models? In our #ACL2023NLP paper, we explore which parts of task instructions are most important for model performance. 🔗 arxiv.org/abs/2306.01150 Code: github.com/fanyin3639/Ret…


Adding Memory is important to help Chains and Agents remember previous interactions. Below are a few memory types you can use for your @LangChainAI apps. 1) ConversationBufferMemory: Keeps a list of the interactions and can extract the messages in a variable.

I wrote a bit of a guide to ChatGPT’s Code Interpreter, which I have found to be the most useful and powerful mode of AI. It is, like every product made by OpenAI so far, terribly named. It is less a tool for coders and more a coder who works for you. oneusefulthing.org/p/what-ai-can-…

LangChain: Chat with Your Data, a new free short course created with @hwchase17, is now available! deeplearning.ai/short-courses/… In this 1 hour course, you’ll learn how to build one of the most requested LLM-based applications: Answering questions using information from a document or…
OpenAI Functions are very powerful! Check this conversation between customer and customer support agent (AI): [User]: Hi, I forgot when my booking is. [Agent]: Sure, I can help you with that. Can you please provide me with your booking number, customer name, and surname? 1/6























































United States 트렌드
- 1. #ElClasico 52.6K posts
- 2. Go Birds 3,356 posts
- 3. #AskFFT N/A
- 4. Good Sunday 69.8K posts
- 5. Go Bills 4,295 posts
- 6. #HardRockBet 1,291 posts
- 7. Mbappe 55.4K posts
- 8. #sundayvibes 6,315 posts
- 9. Barca 106K posts
- 10. Mooney 2,218 posts
- 11. Scott Bessent 14.1K posts
- 12. Vini 20.6K posts
- 13. Real Madrid 171K posts
- 14. Drake London 1,204 posts
- 15. Full PPR N/A
- 16. #ARSCRY 4,664 posts
- 17. Barcelona 170K posts
- 18. Sunday Funday 4,393 posts
- 19. Lamine 92K posts
- 20. NFL Sunday 7,798 posts
내가 좋아할 만한 콘텐츠
-
 LangChain4j
LangChain4j
@langchain4j -
 Aidan McLaughlin
Aidan McLaughlin
@aidan_mclau -
 Aafreen Sultana
Aafreen Sultana
@AafreenSultan12 -
 Kuji Middou inta {Krzzy Midwinter}
Kuji Middou inta {Krzzy Midwinter}
@Midknight_86 -
 afosui
afosui
@afosui -
 sweetfeel💛 DROP
sweetfeel💛 DROP
@sweetfeel468224 -
 Weather Report
Weather Report
@ReporterWeather -
 Pranay Suyash
Pranay Suyash
@pranaysuyash -
 Jorge Hernandez 🇺🇦 🏳️🌈
Jorge Hernandez 🇺🇦 🏳️🌈
@braneloop -
 Ali abduallah mohammed al huthaifi
Ali abduallah mohammed al huthaifi
@Aliabduallah0 -
 Chris A
Chris A
@ChrisInSLC -
 Greg 🏴🏴
Greg 🏴🏴
@T_Witter011 -
 Casey S Brown
Casey S Brown
@weld_master -
 SGRuLeZ
SGRuLeZ
@sergeykosenkov
Something went wrong.
Something went wrong.