
bbl
@bbl_apps
bblという聖書アプリを作ってます 多言語対訳のオープンソースソフトウェアです コマンドライン版:https://github.com/nehemiaharchives/bbl アンドロイド版:https://github.com/nehemiaharchives/bbl-android 中の人:@Hokuto_Ide
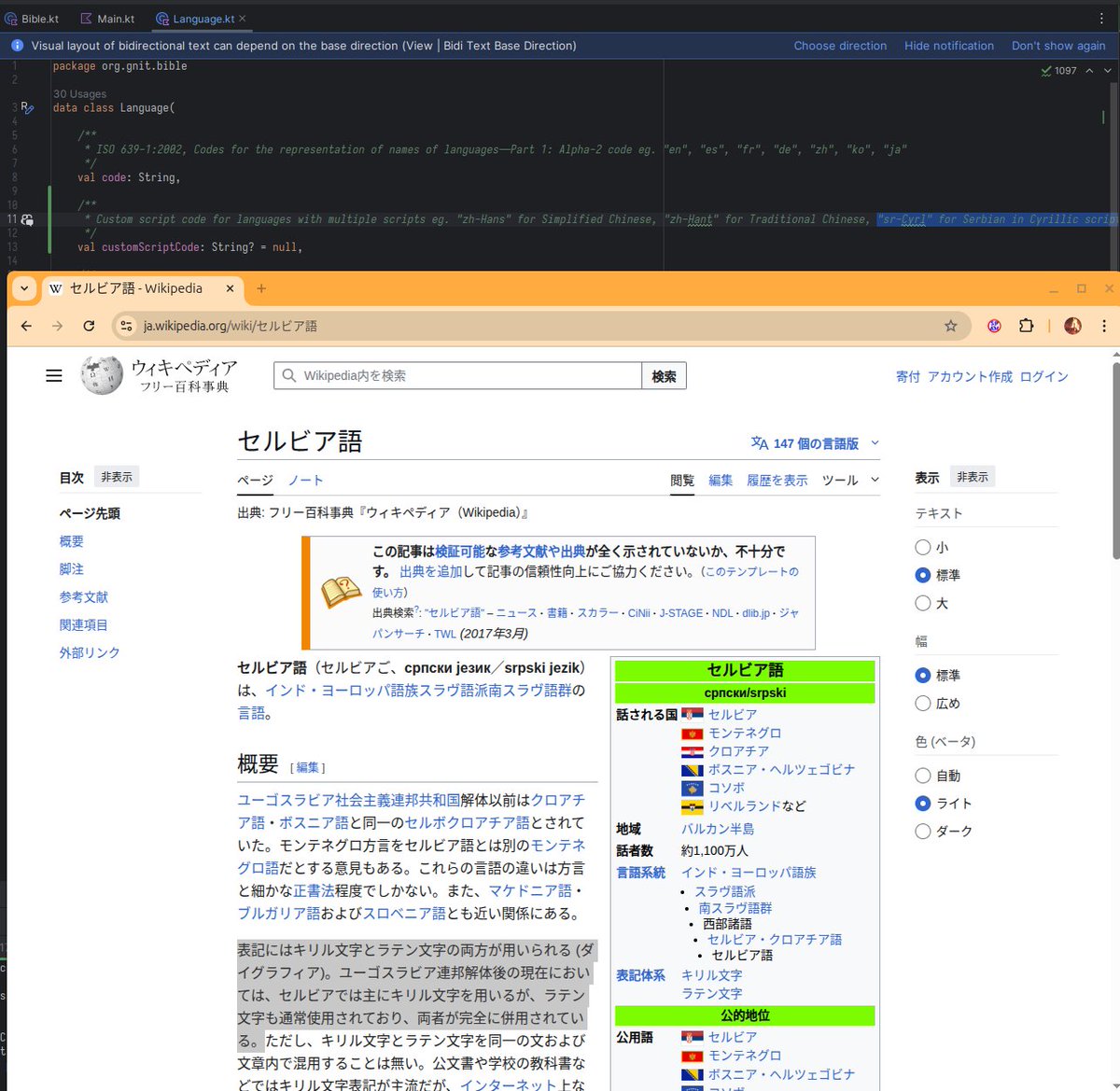
1.bbl-kmpに埋め込む聖書の言語を追加 2.ISO 639-1言語コードでは中国語の簡体字と繁体字を区別できず 3.ISO 15924文字体系コードを導入 4.GitHub copilotでkdocを自動生成 5.セルビア語はキリル文字とラテン文字両方使うとか言い出す 6.またハルシッてると思いつつ一応調査 7.事実だったのでAIに謝罪
Kotlin/Nativeのコンパイル速度はそれに比べると遅いんです。だからKotlin/JVMが際立つ。
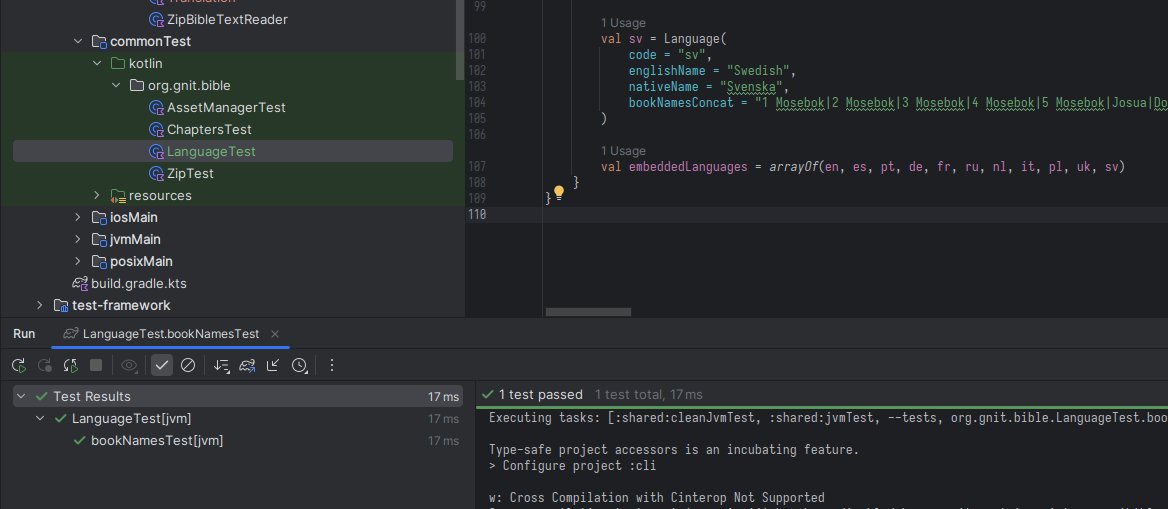
Kotlin/JVMのインクリメンタル・コンピレーションがむちゃくちゃ早いのでビビっている。bbl-kmpに収録する予定の聖書の言語の言語データを1言語増やすごとに単体テストを実行してるけど、新規に言語データを追加したコードをコンパイルしてからテスト実行まで17ミリ秒で終わる。
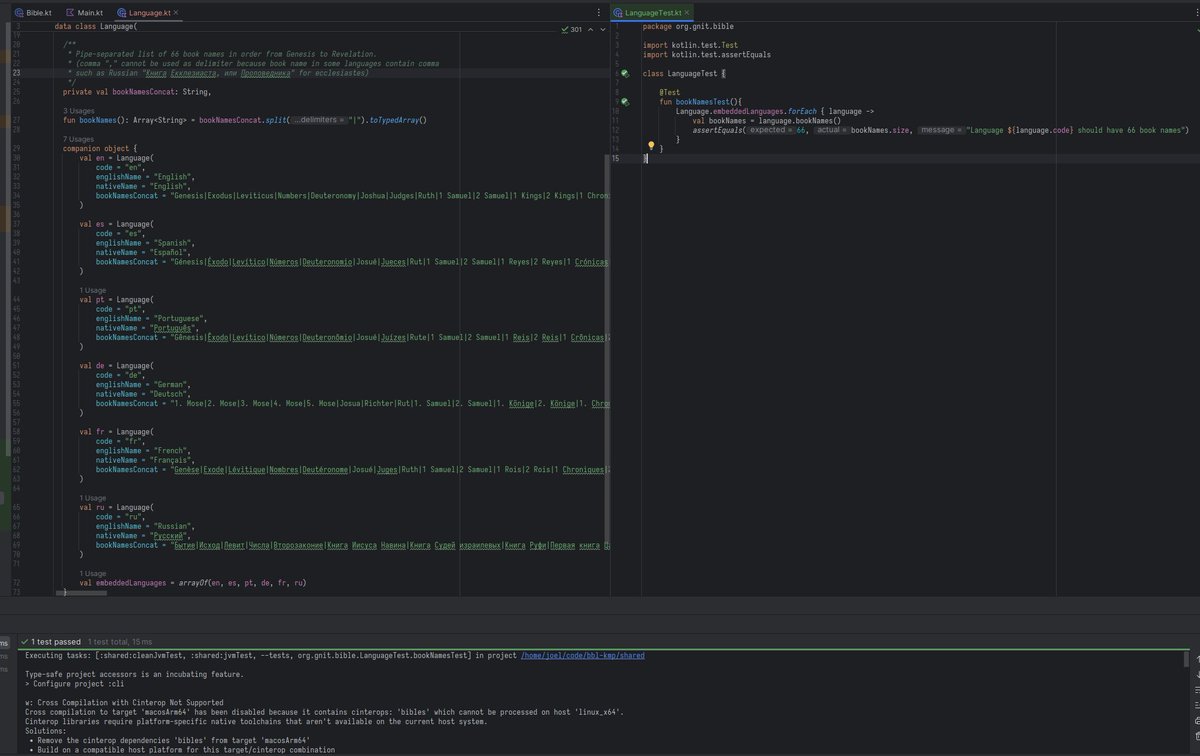
これで心配になってくるのは「パイプ記号を聖書の書名に使う言語は存在するのか?」という命題。存在したら単体テストが落ちるので気づくでしょう。なのでカンマ問題は解決したのでこのままでとりあえず実装を続ける。
bbl-kmpに埋め込まれている聖書の各言語での書名をハードコーディングしている。ハードコーディング元のデータはbbl-androidにすでにあるので、移植。ただ、データ構造を読みやすい今回変更することにした。で、カンマで分かち書きにしたらテスト落ちた。ロシア語の書名はカンマ含むからパイプに変更。


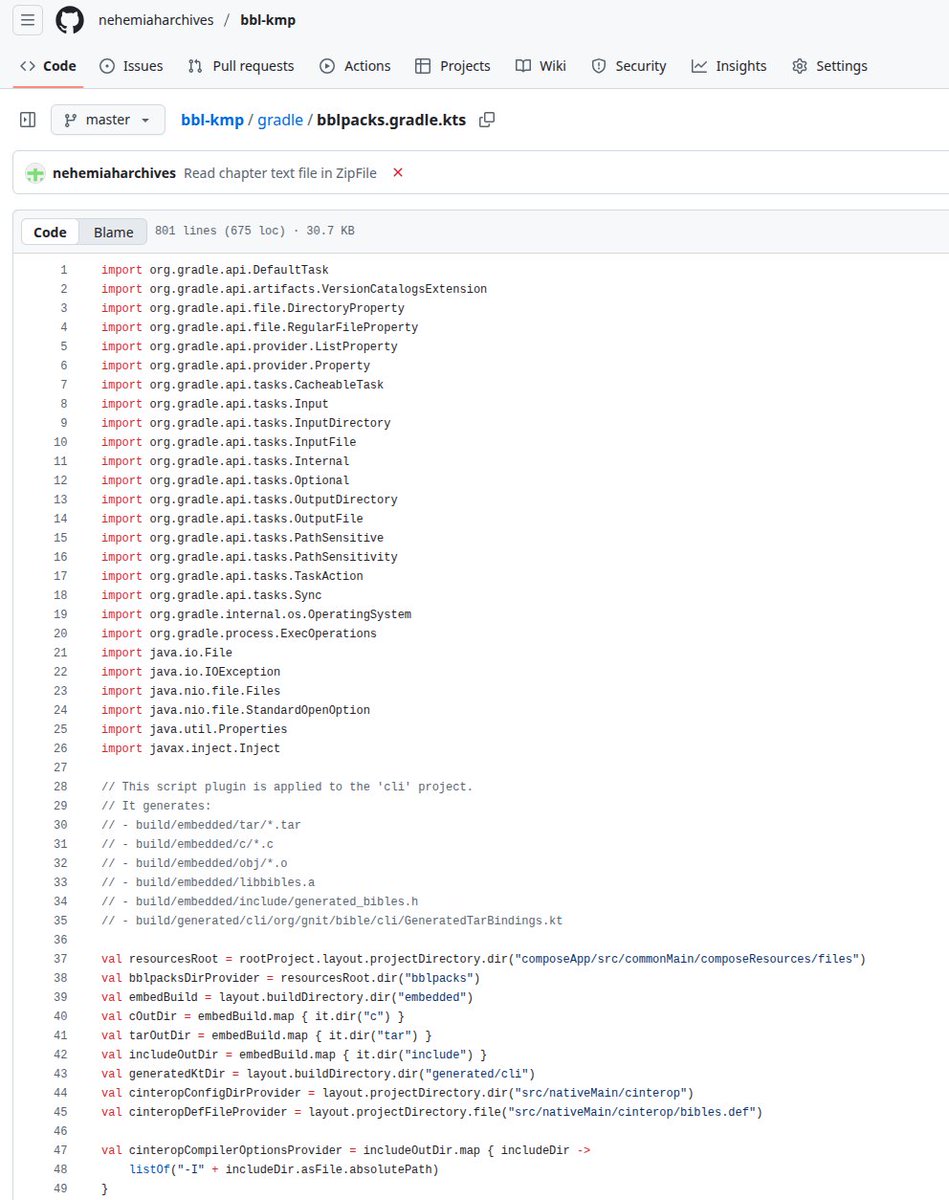
これ。やらざるを得なかった。kotlin multiplatformにはresourcesをkotlin/nativeから読み込む手段が実装されてない。ので、AIにむりくり作らせた。やってみたらえ動いたのでそのまま使ってる。ダーティーハック上等よ!コードはここ:github.com/nehemiaharchiv…

生成AI関係なく古の時代から「ダーティハック」というのがあるじゃないですか。その場しのぎのとか、とりあえず動けばいいみたいな。あまり良いものとしては捉えられてないわけなんだけど、それは本当は調べれば最もいい方法がわかるのに手を抜いているからみたいなニュアンスだとおもうのだけど、今の…
昔(2023年)の論文だけど、今見つけたので読んだ。

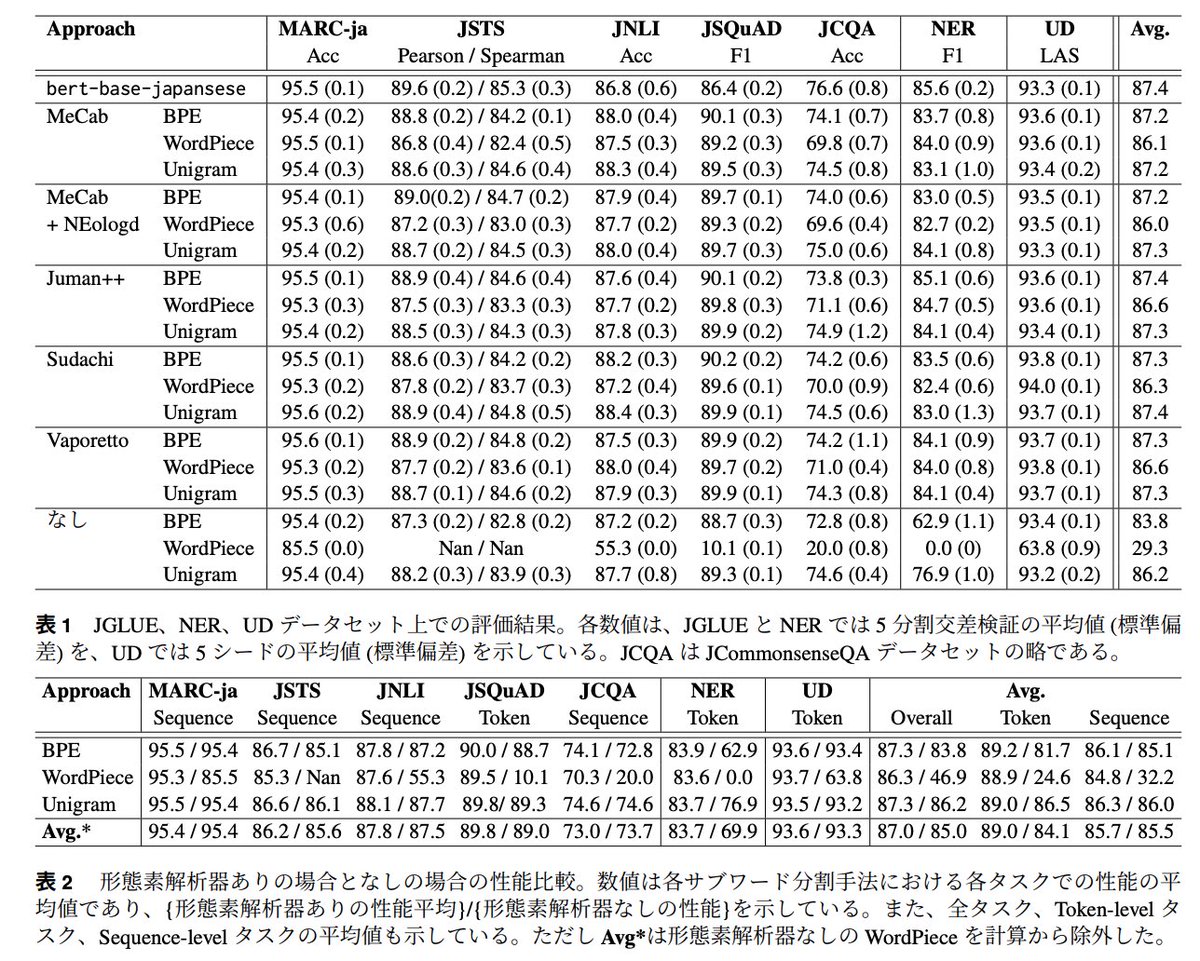
#NLP2023 の「日本語Tokenizerの違いは下流タスク性能に影響を与えるか?」が非常に素晴らしかった tokenizerと辞書の組み合わせ18種類について **事前学習 + fine-tuning** を行い、日本語タスクによる網羅的な評価で形態素解析器の有無による性能差等を明らかにしている anlp.jp/proceedings/an…
































































































United States Tendances
- 1. Halo 119K posts
- 2. PlayStation 55.5K posts
- 3. $BIEBER 1,294 posts
- 4. Xbox 69.2K posts
- 5. #WorldSeries 52.6K posts
- 6. #HitTheBuds 2,571 posts
- 7. Jasper Johnson N/A
- 8. #CashAppPools 1,667 posts
- 9. Purdue 3,517 posts
- 10. Cole Anthony N/A
- 11. Reagan 230K posts
- 12. Ashley 159K posts
- 13. Rajah N/A
- 14. Combat Evolved 5,033 posts
- 15. Megan 72.7K posts
- 16. Master Chief 7,124 posts
- 17. Kensington 6,742 posts
- 18. End of 1 13.5K posts
- 19. Layne Riggs N/A
- 20. Tish 19.4K posts
Something went wrong.
Something went wrong.