Cristina
@biologeek
Metabolomics, #Rstats and feature importance curiosity 🤔
Talvez você curta





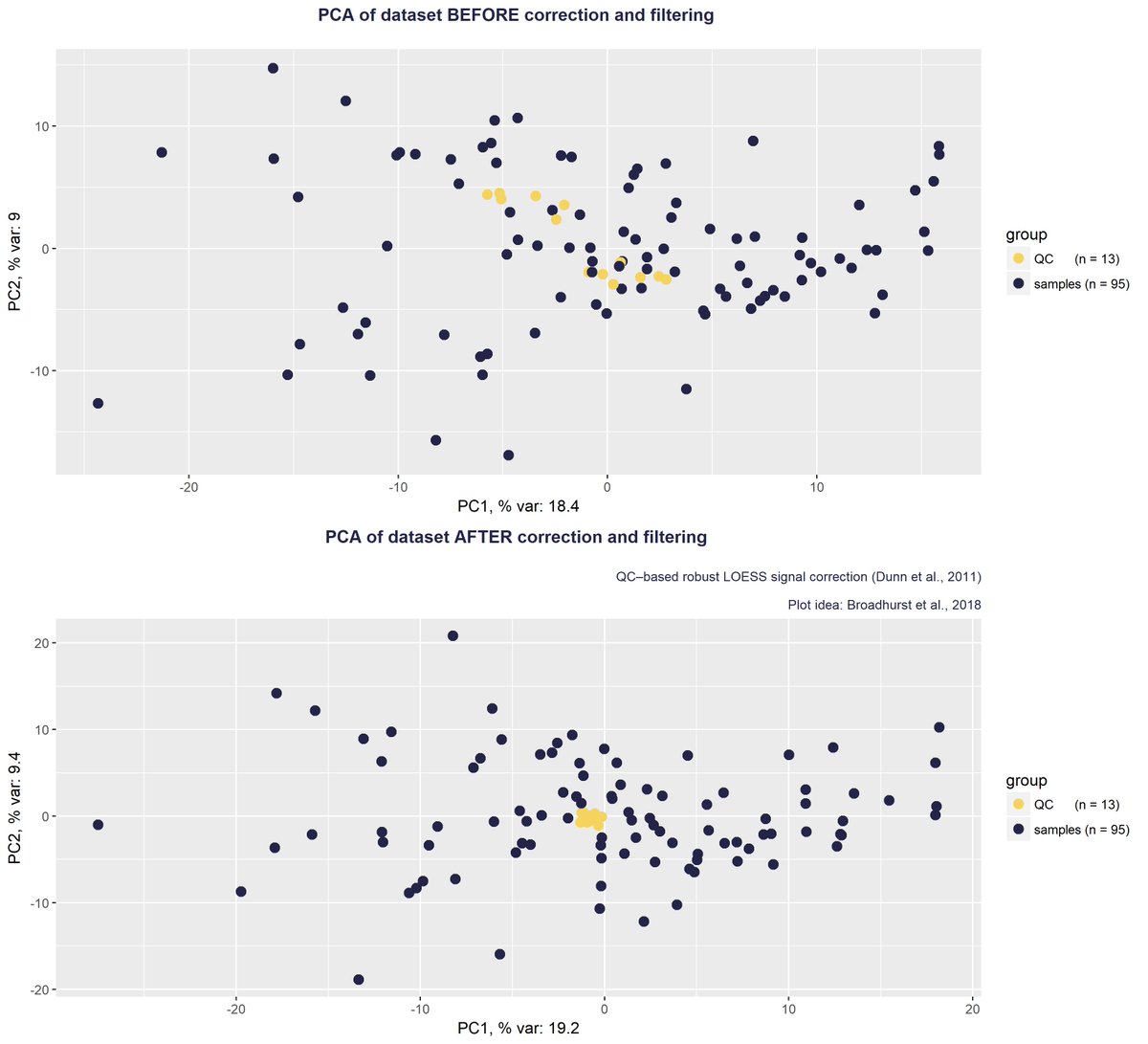
Ok! PCA before + after correction done! Or should I say Dunn? :) Big thanks to @BroadhurstDavid for communicating their work. Current work based on Dunn et al., 2011 but in forthcoming analyses, a thing or 2 are eligible for update based on Broadhurst et al., 2018 #metabolomics

It never ceases to amaze me what people can make with gganimate #rstats

#RStats — Can we scrape the online documentation of an API to automate the creation of an R wrapper 📦? Spoiler: yes. "Automate the Creation of an API Wrapper package by Scraping its Online Documentation" colinfay.me/fun-from-api-d…

I think dplyr::all_equal() should do most of that. Not sure about types


upvoting qs- handles any R object and comparable to fst in speed. The main difference from fst is qs doesn’t support random access, eg how fst allows reading only specific cols/rows. But read/write speeds overall close. I think they share a bunch of implementation strategies.

Retweeting because I am really excited about this. I am willing to bet that 1) thinking about the next hypothesis you will test in machine readable terms will immediately improve what you are doing, and 2) better meta-data will make science massively more efficient.
New preprint with @LisaDeBruine where we make the case for machine readable hypothesis tests psyarxiv.com/5xcda/. We give a real-life example, argue this would improve the rigour and falsifiability of hypothesis tests, as well as facilitate the re-use of key info in articles.


TIL: I learnt about the conflicted 📦 My filter function always gets masked, so my solution till today was dplyr::filter. But there is a better way! You can set your function:library preference at the top of your script! 😭🙏 e.g. conflict_prefer("filter", "dplyr") #rstats



A thread of classifiers learning a decision rule. Dashed line is optimal boundary. Animations with #gganimate by @thomasp85 and @drob. #rstats Logistic regression {stats::glm} with each class having normally distributed features. (1/n)

I finally got around to looking up the linear algebra of matrix rotations for my PCA explanation.

We explain the concept of calibration in the link below. In short, calibration is about the predicted risks (probabilities) that come out of your prediction model and whether or not these risks are consistent with the proportion of events you observed
Sorry for the shameless plug, but you might be interested in this: bmcmedicine.biomedcentral.com/articles/10.11…
You can read about it in @ESteyerberg's book, and @BenVanCalster wrote quite a few things about it, see: ncbi.nlm.nih.gov/pubmed/26772608 ncbi.nlm.nih.gov/pubmed/31842878


Instead of referring to myself as self-taught, I'm gonna start referring to myself as community-taught. The sites, the blogs, the books, the user groups, the confs, the forums ... all community efforts that I used to learn and advance my programming and data science knowledge.
Computer: change your password Me: ********** Computer: new password does not meet requirements Me: **************** Computer: new password does not meet requirements Me: ************************** Computer: new password does not meet requirements Me:

The null-coalescing operator %||% is in the miscellany section of this talk on making conditional logic easier to read and maintain (links to a specific slide): speakerdeck.com/jennybc/code-s… %||% is key to some nice design patterns eg, using NULL as the default val of optional args.

This is awesome! And happy to see @thomasp85 #geneRativeart projects included in the list 🎨💻
Sorry for the shameless plug, but you might be interested in this: bmcmedicine.biomedcentral.com/articles/10.11…

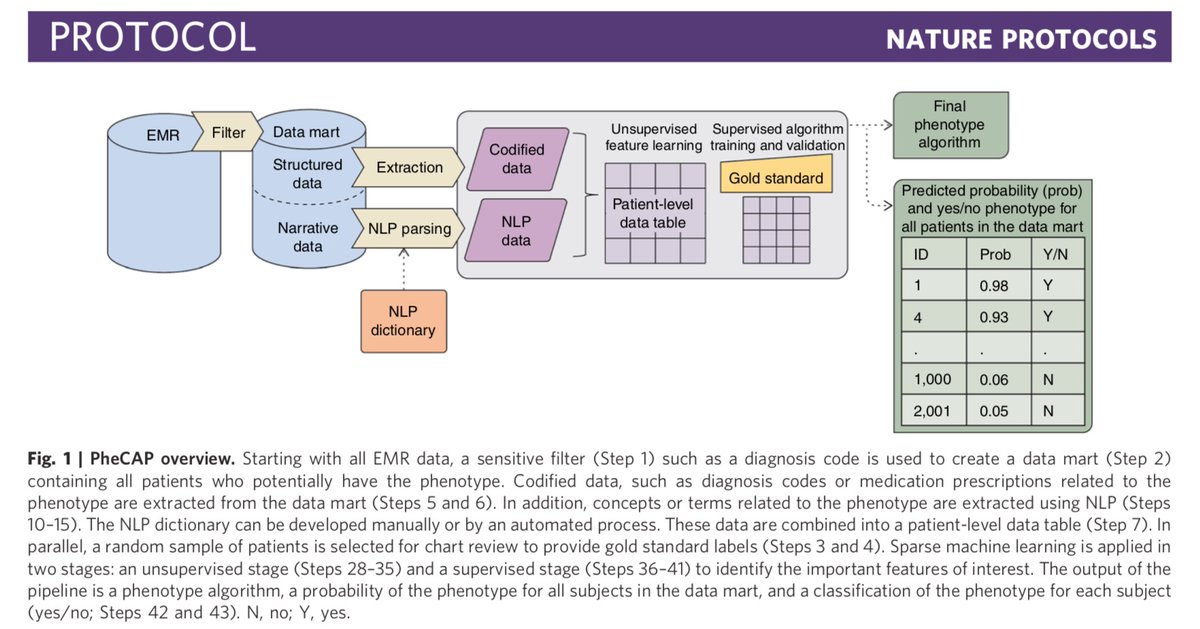
Introducing PheCAP, a high-throughput semi-supervised phenotyping pipeline. PheCAP starts with EMR data (structured and NLP) and outputs a phenotype algorithm, the probability of the phenotype for all patients, and a phenotype classification (yes or no). nature.com/articles/s4159…

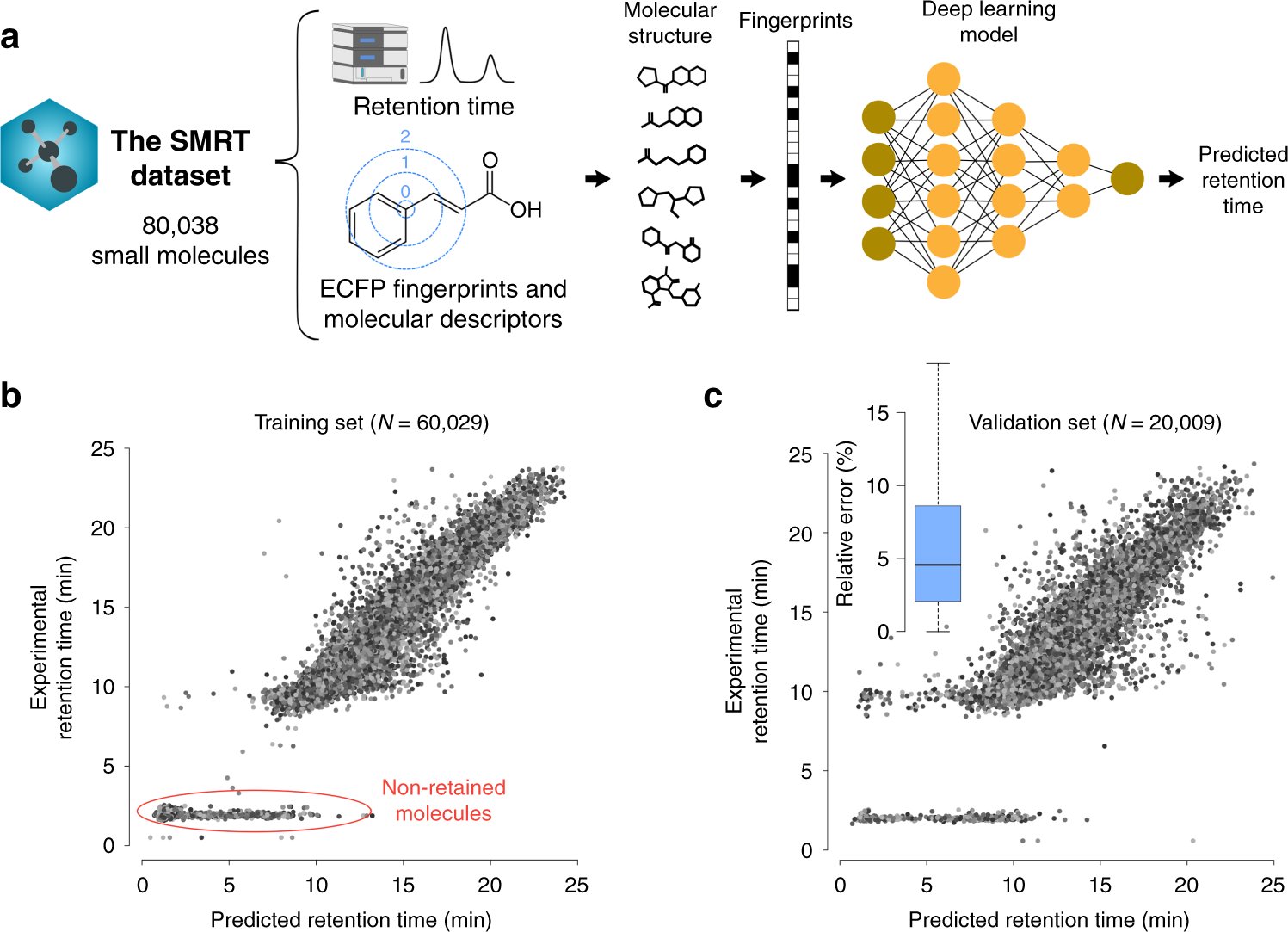
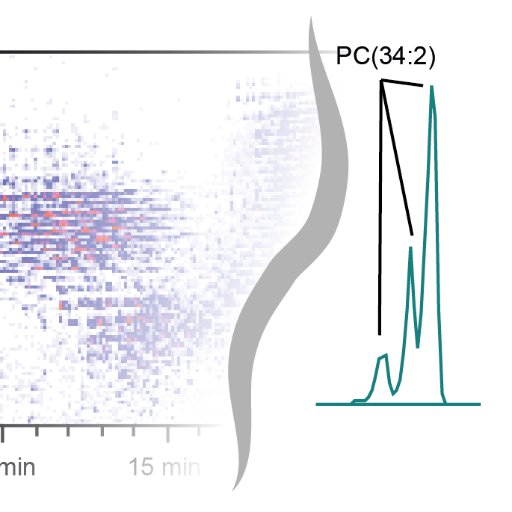
Interested in small molecule retention time prediction? Check out our new paper in @NatureComms introducing the SMRT dataset, containing the experimental RT of 80K molecules generated in @kadzuis lab at @scrippsresearch #metabolomics #MachineLearning nature.com/articles/s4146…

genome-wide analysis identifies molecular systems and 149 genetic loci associated with believing GWAS results are biologically meaningful



















































































































United States Tendências
- 1. Friendly 61K posts
- 2. SNAP 699K posts
- 3. Big Dom 1,650 posts
- 4. #JUNGKOOKXCALVINKLEIN 39.4K posts
- 5. Jamaica 110K posts
- 6. Jessica 27.3K posts
- 7. Riley Gaines 33.3K posts
- 8. Mazie 1,258 posts
- 9. Runza N/A
- 10. Crash Bandicoot 6,266 posts
- 11. MRIs 7,529 posts
- 12. 53 Republicans 4,334 posts
- 13. Roberto Clemente 1,815 posts
- 14. RIP Beef 1,654 posts
- 15. Sports Equinox 12.8K posts
- 16. #NationalBlackCatDay 4,970 posts
- 17. Heal 37.9K posts
- 18. Sonic Prime 1,290 posts
- 19. 7 Democrats 5,392 posts
- 20. Monday Night Football 6,378 posts





Something went wrong.
Something went wrong.