
Burny - Effective Curiosity
@burny_tech
On the quest to understand the fundamental mathematics of intelligence and of the universe with curiosity. http://burnyverse.com Upskilling @StanfordOnline
You might like















Hey! Follow me for explorations of intelligence, mathematics, science, engineering, technology, artificial intelligence, machine learning, physics, computer science, (not only computational) neuroscience, cognitive science, transhumanism, AI engineering, AI's benefits, risks,…



Hi new followers! I’m a mathematician at Harvard. I have a YouTube channel, where I discuss math the way I think about it, with now two playlists on differential geometry and complex geometry (in progress). Comments welcome! DG: youtube.com/watch?v=rVTN7V… CG: youtube.com/watch?v=N5FQHg…



An interesting property of ARC 3 is that it is more accessible to children than ARC 1 & 2, while being much more difficult for current AI systems

2024 evals can it count letters 🥺 can it do college stuff 🤓 are its solutions diverse 👉👈 2025 evals has it worked for 30 hours yet 🦾 has it increased gdp 📈 has it discovered novel math 🧮

/Humanitys-Last-Exam/ ├─ Humanity_Last_Exam.docx ├─ Humanity_Last_Exam_final.docx ├─ Humanity_Last_Exam_FINAL.docx ├─ Humanity_Last_Exam_FINAL_FINAL.docx ├─ Humanity_Last_Exam_REAL_FINAL.docx ├─ Humanity_Last_Exam_REAL_FINAL_v2.docx ├─…

We recently wrote that GPT-5 is likely the first mainline GPT release to be trained on less compute than its predecessor. How did we reach this conclusion, and what do we actually know about how GPT-5 was trained? 🧵

sota on arc-agi-1 and -2, sota on artifical intelligence (composite), blows everything (including 4.5 sonnet) away on METR task length... it might not be forever, and it might not be for your use case, but gpt-5 is the world's best overall model; any other claim is cope




A calculation by the late physicist Freeman Dyson suggested that no plausible experiment could be conducted to confirm the existence of gravitons, the hypothetical particles of gravity. A new proposal overturns that conventional wisdom. quantamagazine.org/it-might-be-po…


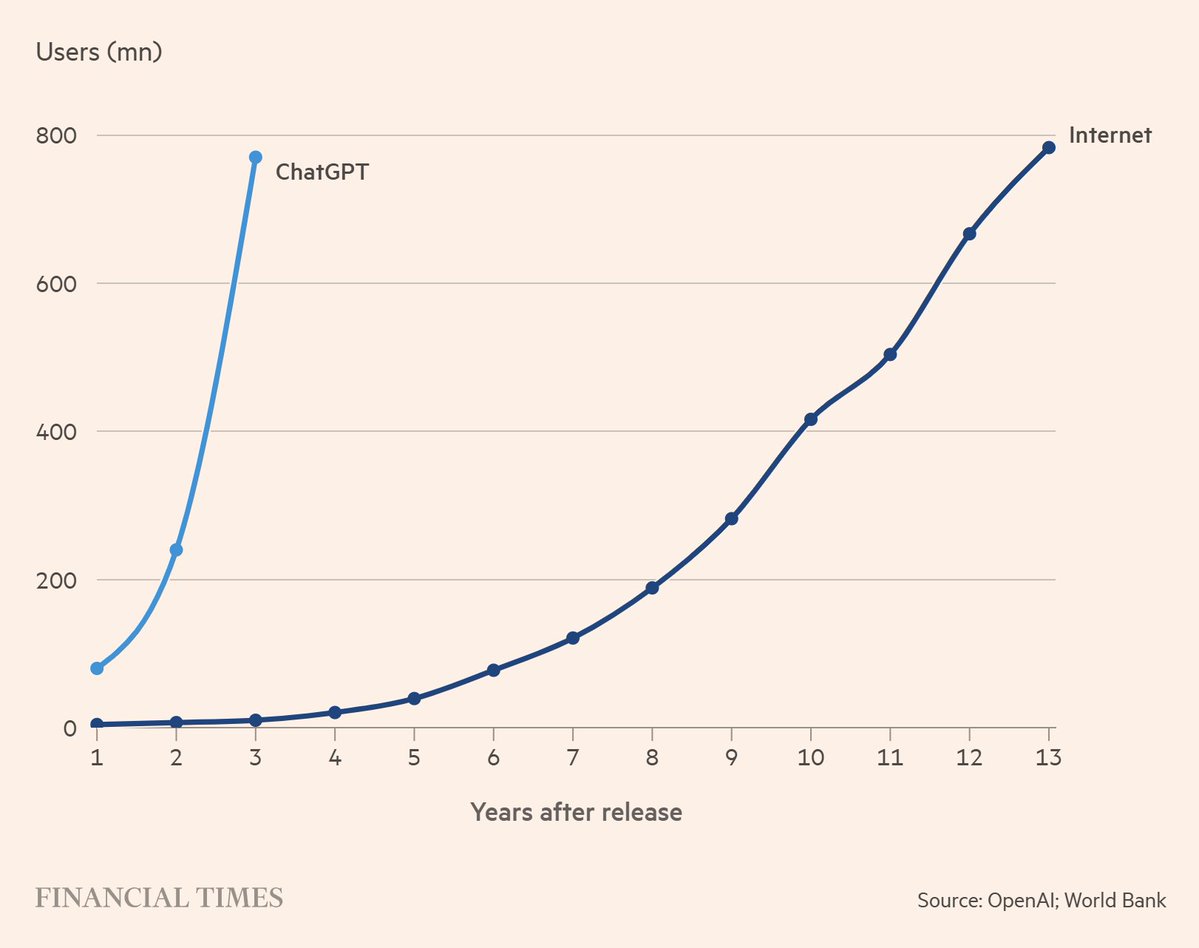
One AI year is seven Internet ones.

Official METR results for Claude 4.5 Sonnet it doesn't beat GPT-5 with 80% success rate it is even below o3, 4 and 4.1 Opus


We estimate that Claude Sonnet 4.5 has a 50%-time-horizon of around 1 hr 53 min (95% confidence interval of 50 to 235 minutes) on our agentic multi-step software engineering tasks. This estimate is lower than the current highest time-horizon point estimate of around 2 hr 15 min.

We estimate that Claude Sonnet 4.5 has a 50%-time-horizon of around 1 hr 53 min (95% confidence interval of 50 to 235 minutes) on our agentic multi-step software engineering tasks. This estimate is lower than the current highest time-horizon point estimate of around 2 hr 15 min.



New ARC-AGI SOTA: GPT-5 Pro - ARC-AGI-1: 70.2%, $4.78/task - ARC-AGI-2: 18.3%, $7.41/task @OpenAI’s GPT-5 Pro now holds the highest verified frontier LLM score on ARC-AGI’s Semi-Private benchmark


Now didnt expect such jump from non pro version?

A group of physicists say they know the entropy of what is causing gravity. youtube.com/watch?v=qNt2bh…

youtube.com
YouTube
This Paper Might Change How We See Gravity

Yann LeCun's team is continuously advancing JEPA. Their new study reveals that the anti-collapse term in Joint Embedding Predictive Architectures (JEPAs) does more than just prevent trivial representations — it implicitly estimates data density. This means any trained JEPA…


Evolution Strategies can be applied at scale to fine-tune LLMs, and outperforms PPO and GRPO in many model settings! Fantastic paper “Evolution Strategies at Scale: LLM Fine-Tuning Beyond Reinforcement Learning” by @yule_gan, Risto Miikkulainen and team. arxiv.org/abs/2509.24372


Congratulations to Michel Devoret, Google Quantum AI’s Chief Scientist of Quantum Hardware, who was awarded the 2025 Nobel Prize in Physics today. Google now has five Nobel laureates among our ranks, including three prizes in the past two years. goo.gle/46EwKaG


🧠How can LLMs self-evolve over time? They need memory. LLMs burn huge compute on each query and forget everything afterward. ArcMemo introduces abstraction memory, which stores reusable reasoning patterns and recombines them to strengthen compositional reasoning. 📈On…
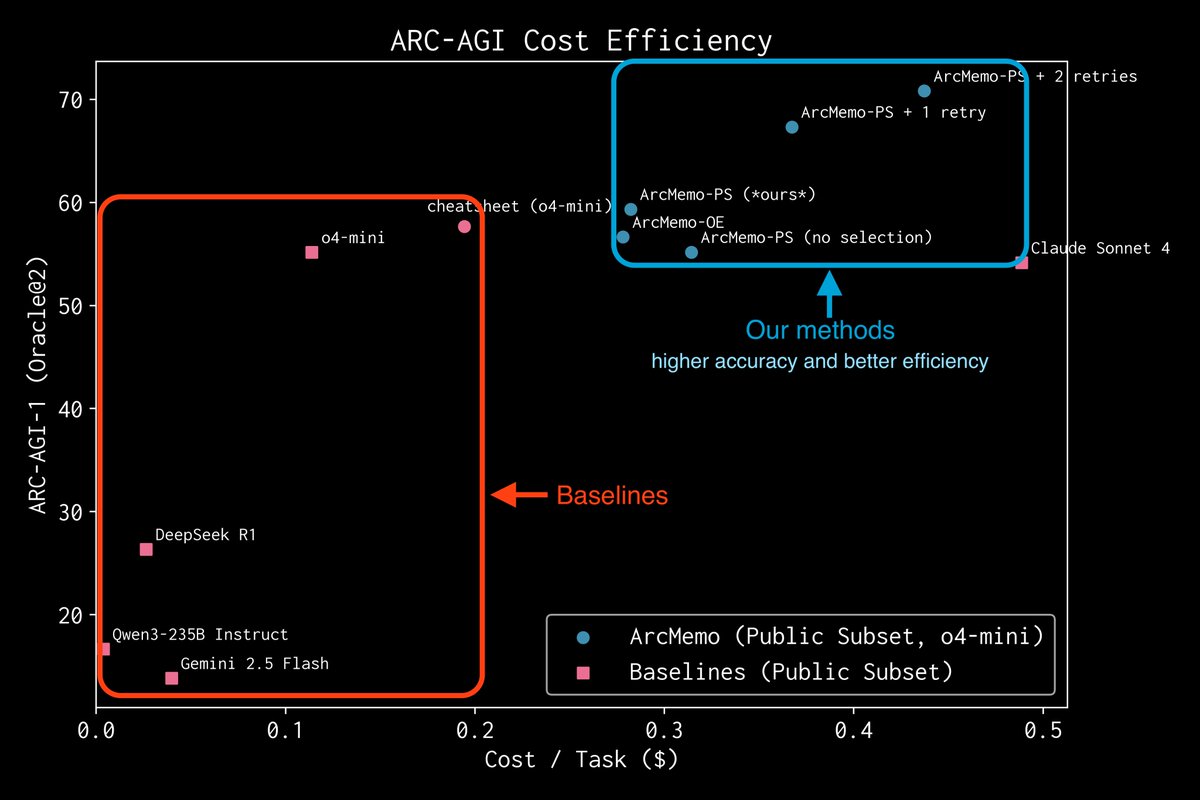

ArcMemo yields +7.5% relative on ARC-AGI vs o4-mini (same backbone). It extends the LLM idea of “compressing knowledge for generalization” into a lightweight, continually learnable abstract memory—model-agnostic and text-based. Preprint: Lifelong LM Learning via Abstract Memory

Impressive work.

My brain broke when I read this paper. A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2. It's called Tiny Recursive Model (TRM) from Samsung. How can a model 10,000x smaller be smarter? Here's how…


the new ai benchmark next year will be "when you ask a model to make you a $1b arr saas, how much money actually shows up in your bank account"
























































































































United States Trends
- 1. Auburn 45.2K posts
- 2. Brewers 64K posts
- 3. Georgia 67.9K posts
- 4. Cubs 55.7K posts
- 5. Kirby 24K posts
- 6. Arizona 42.1K posts
- 7. Utah 24.7K posts
- 8. Gilligan 5,878 posts
- 9. #AcexRedbull 3,760 posts
- 10. Michigan 63K posts
- 11. Hugh Freeze 3,218 posts
- 12. #BYUFootball N/A
- 13. #Toonami 2,586 posts
- 14. Boots 50.8K posts
- 15. Amy Poehler 4,387 posts
- 16. #GoDawgs 5,566 posts
- 17. #byucpl N/A
- 18. Kyle Tucker 3,176 posts
- 19. Dissidia 5,642 posts
- 20. Tina Fey 3,370 posts
You might like
-
 Stephen Zerfas
Stephen Zerfas
@stephen_zerfas -
 Captain Pleasure, Andrés Gómez Emilsson
Captain Pleasure, Andrés Gómez Emilsson
@algekalipso -
 Qualia Research Institute
Qualia Research Institute
@QualiaRI -
 Cube Flipper
Cube Flipper
@cube_flipper -
 Shinkyū
Shinkyū
@durdfarm -
 RomeoStevens
RomeoStevens
@RomeoStevens76 -
 Na Ro
Na Ro
@peak_valley_pea -
 Matthew Dub
Matthew Dub
@5matthewdub -
 Rudra Dakini
Rudra Dakini
@the_wilderless -
 Robert Fox
Robert Fox
@RobertFox_420 -
 Loopy
Loopy
@strangestloop -
 Samswara
Samswara
@samswoora -
 rosalind lucy
rosalind lucy
@wholebodyprayer -
 Fractal Authenticity 4/1000 cranes
Fractal Authenticity 4/1000 cranes
@FractalAuth -
 Jake Orthwein
Jake Orthwein
@JakeOrthwein
Something went wrong.
Something went wrong.