

Google TPUv7: - 4.6 PFLOP/s FP8 - 192 GB HBM @ 7.4 TB/s - 600 GB/s (unidi) ICI - ~1000 watts Nvidia GB200: - 5 PFLOP/s FP8 / 10 PFLOP/s FP4 - 192 GB HBM @ 8 TB/s - 900 GB/s (unidi) NVLink - ~1200 watts blog.google/products/googl…


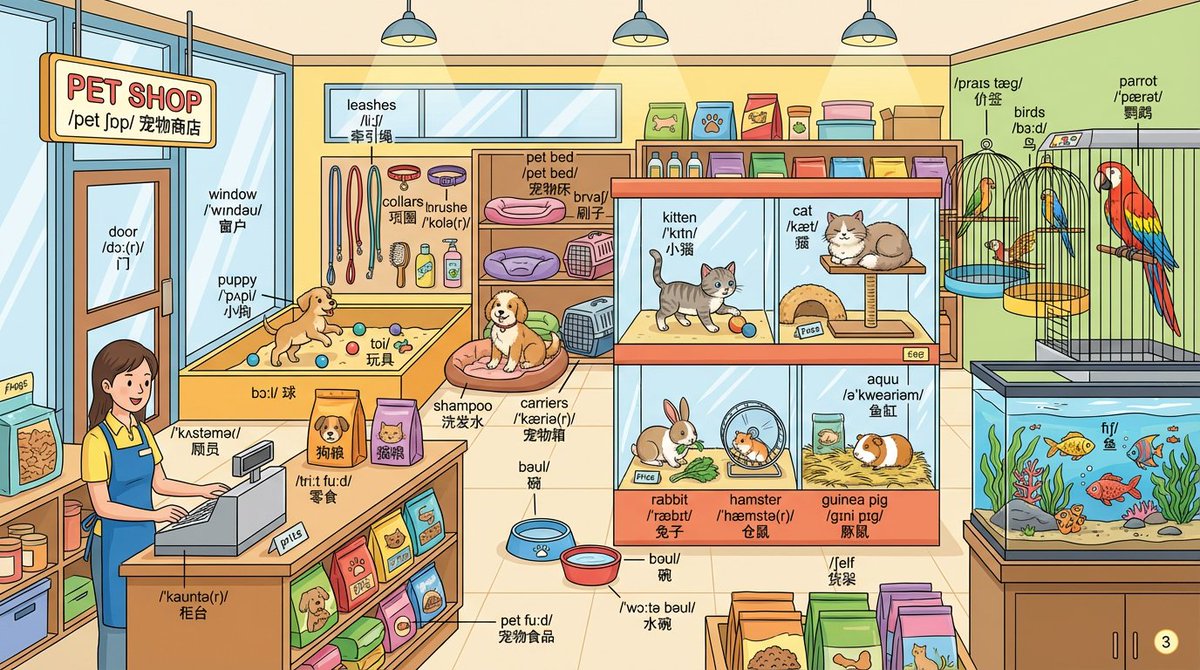
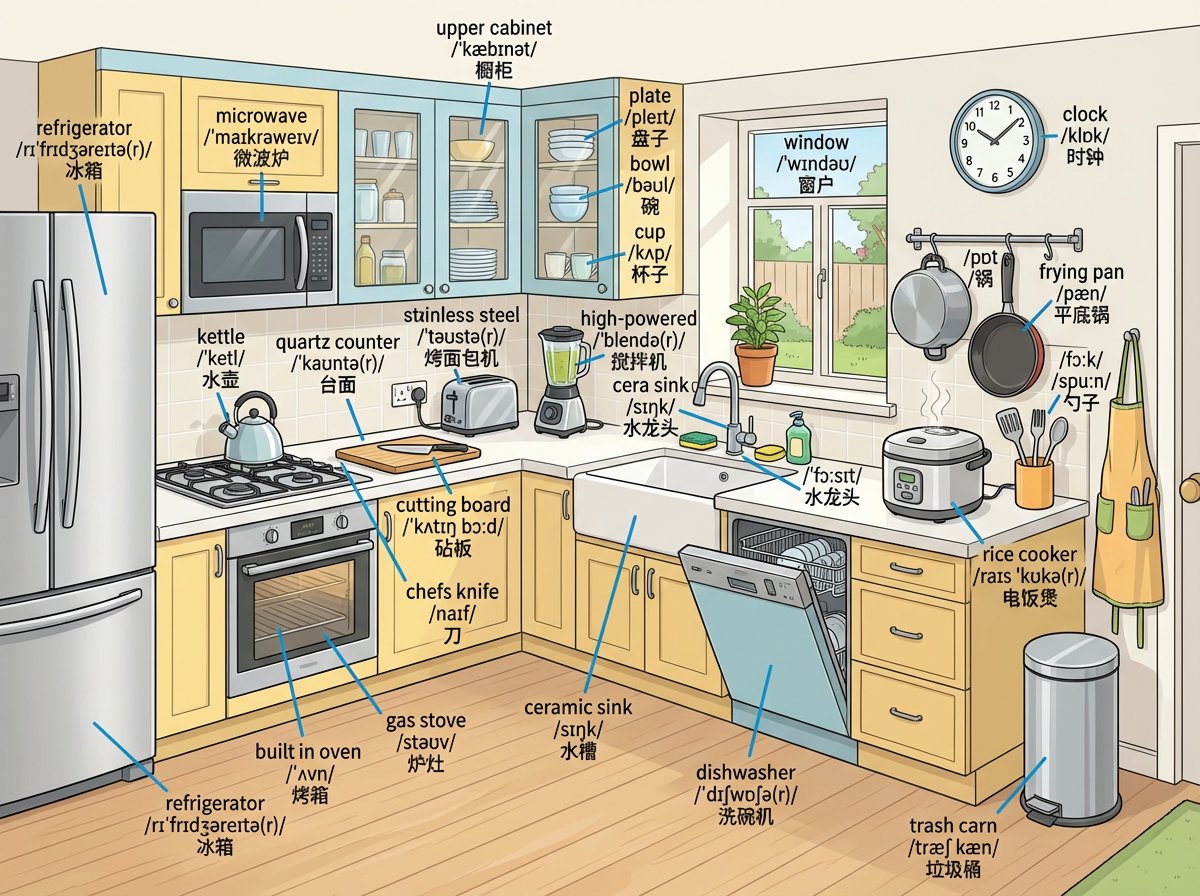
Another super impressive use case... Nano banana is killing the game 🥲 It's so luck to be a language learner in this era. > Prompt: Draw a detailed {{pet shop}} scene and label every object with English words. Label format: - First line: English word - Second line: IPA…


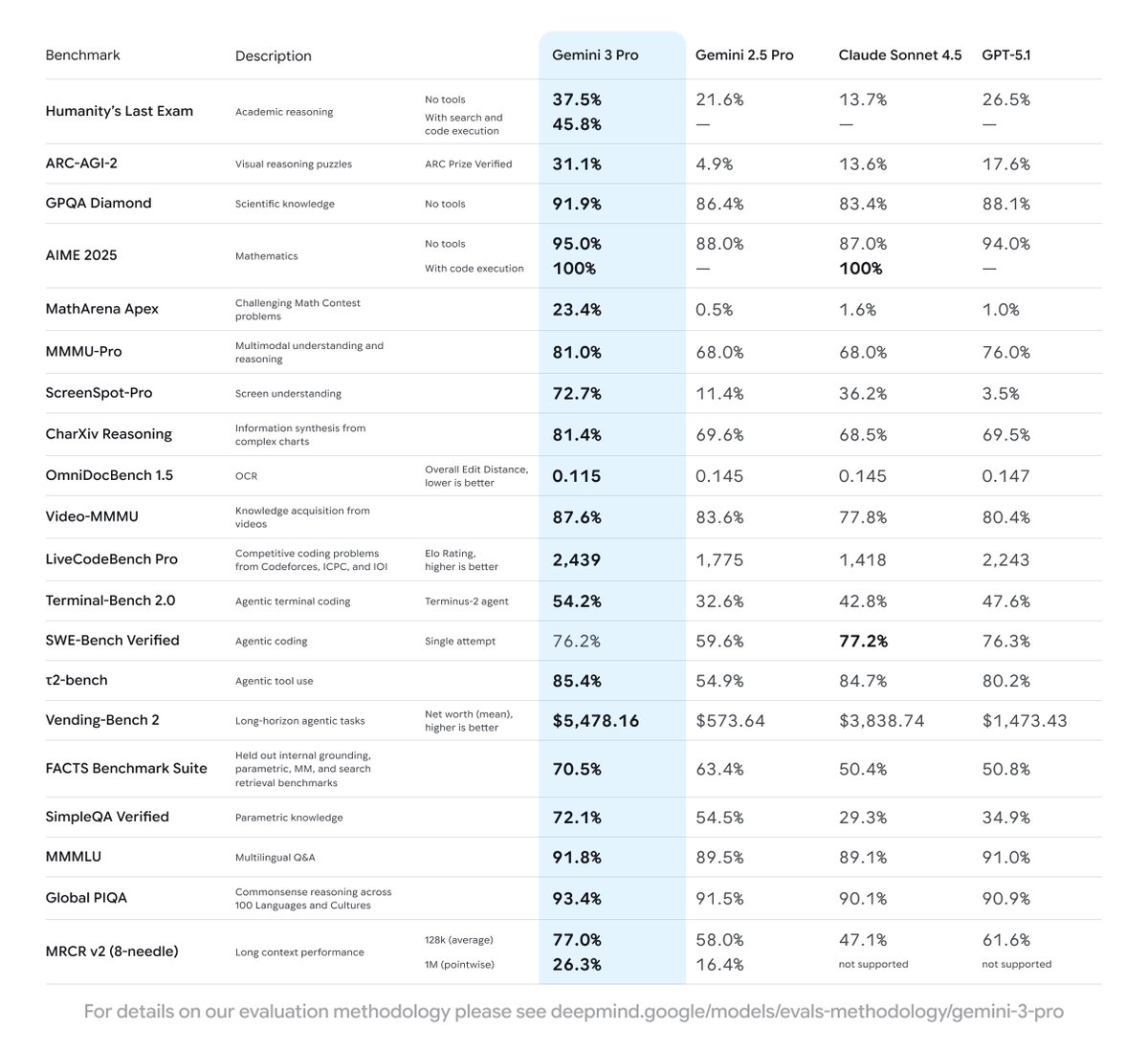
The secret behind Gemini 3? Simple: Improving pre-training & post-training 🤯 Pre-training: Contra the popular belief that scaling is over—which we discussed in our NeurIPS '25 talk with @ilyasut and @quocleix—the team delivered a drastic jump. The delta between 2.5 and 3.0 is…

life is 10x better when you're obsessed w/ building something

Designing an inference chip for robots is actually very difficult. In data centers each chip is bathed in jacuzzi and babysat by nannies. If they died it would be hot swapped by one of their clones. The fault rate of GPUs in datacenter is actually quite high. Industrial average…

I see a lot of bad takes on X about PhDs and frontier labs (not just this quoted tweet), so let me chime in. For context, I didn't do a prestigious undergrad, worked a bit in a startup as an applied ML engineer, then did a PhD, and now work in a frontier lab. A PhD isn't…

HOT TAKE: Reality is, you can't actually work in top-quality ML research labs without a PhD. Top research labs still look for people with PhDs and excellence in maths, stats, PyTorch, neural networks, and CUDA kernels. In India, quality ML research labs are virtually…

I would like to clarify a few things. First, the obvious one: we do not have or want government guarantees for OpenAI datacenters. We believe that governments should not pick winners or losers, and that taxpayers should not bail out companies that make bad business decisions or…

My posts last week created a lot of unnecessary confusion*, so today I would like to do a deep dive on one example to explain why I was so excited. In short, it’s not about AIs discovering new results on their own, but rather how tools like GPT-5 can help researchers navigate,…


What are the top 1-3 papers/projects/blogposts/tweets/apps/etc that you have seen on Agentic AI (design/generation of workflows, evals, optimization) in the past year, and why? (Please feel free to recommend your own work)

> be Chinese lab > post model called Qwen3-235B-A22B-Coder-Fast > trained on 100 trillion tokens of synthetic RLHF > open-weights, inference engine, 85-page tech report with detailed ablations > tweet gets 6 likes > Western AI crowd still debating if Gemini plagiarized a…


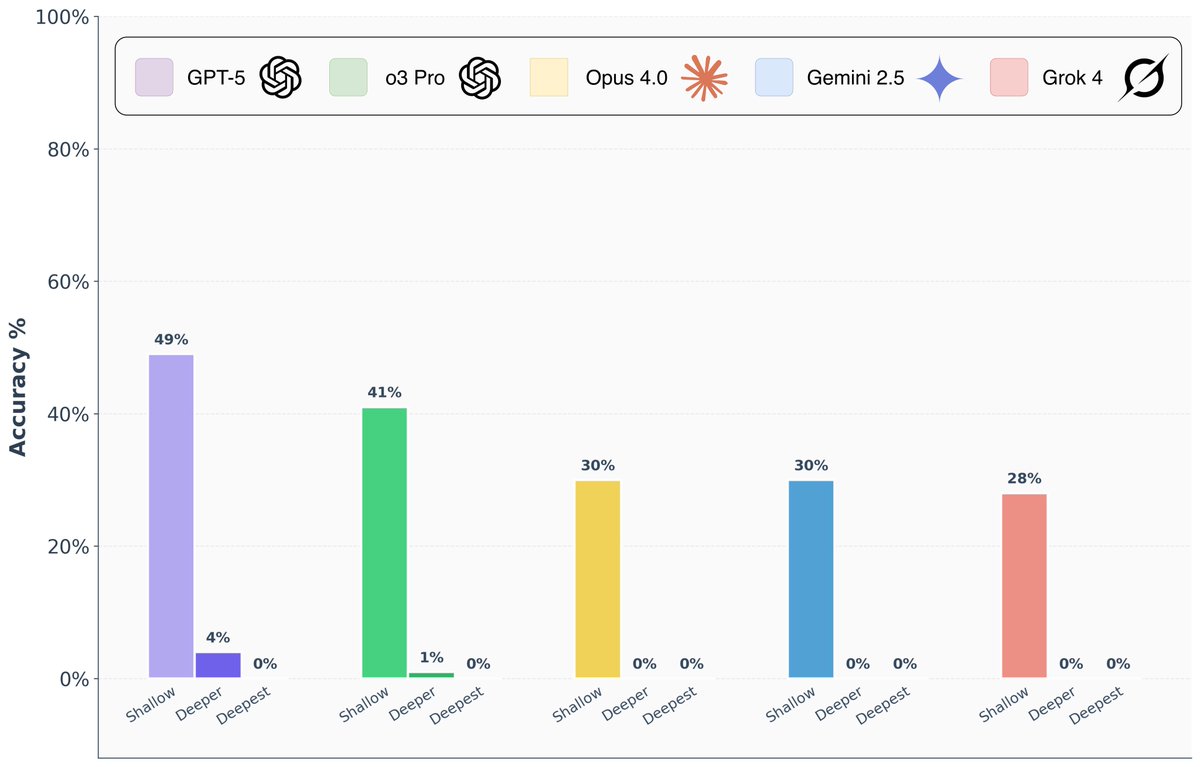
Are frontier AI models really capable of “PhD-level” reasoning? To answer this question, we introduce FormulaOne, a new reasoning benchmark of expert-level Dynamic Programming problems. We have curated a benchmark consisting of three tiers, in increasing complexity, which we call…
“But one thing I do know for sure - there's no AGI without touching, feeling, and being embodied in the messy world.”

I've been a bit quiet on X recently. The past year has been a transformational experience. Grok-4 and Kimi K2 are awesome, but the world of robotics is a wondrous wild west. It feels like NLP in 2018 when GPT-1 was published, along with BERT and a thousand other flowers that…


What a finish! Gemini 2.5 Pro just completed Pokémon Blue!  Special thanks to @TheCodeOfJoel for creating and running the livestream, and to everyone who cheered Gem on along the way.
Counterpoint to Maverick hype.

“and even remembering your day in video” wow!

Apple and Meta have published a monstruously elegant compression method that encodes model weights using pseudo-random seeds. The trick is to approximate model weights as the linear combination of a randomly generated matrix with fixed seed, and a smaller vector t.

elegant






































































United States Xu hướng
- 1. Brian Cole 37K posts
- 2. #TrumpAffordabilityCrisis 5,987 posts
- 3. Eurovision 114K posts
- 4. #EndRevivalInParis 15.6K posts
- 5. Tong 19K posts
- 6. #OlandriaxHarvard 2,122 posts
- 7. #Kodezi 1,192 posts
- 8. Capitol 24.4K posts
- 9. #NationalCookieDay 1,721 posts
- 10. Rwanda 35.2K posts
- 11. Woodbridge 5,960 posts
- 12. Wray 15.3K posts
- 13. Jalen Carter 1,695 posts
- 14. Sidwell N/A
- 15. Sadie 19.6K posts
- 16. Black Album 2,222 posts
- 17. Legend Bey 1,509 posts
- 18. $SMX 2,055 posts
- 19. Dalot 3,097 posts
- 20. Chadwick 1,168 posts
Something went wrong.
Something went wrong.