
Gaurav
@gauravisnotme
Good model @xAI | prev. d-matrix, @Google. I was pre-trained like this. Still figuring out the framework for my fine-tuning. and, opinions my own. Please.
We are now in the era where salary scaling laws are prevailing over model scaling. We are already past Llama-3.2-3B.

Saturday scoop: Thinking Machines Lab co-founder Andrew Tulloch has joined Meta, the startup confirmed. W/ @keachhagey

How and why do startups, with mere pre-seed or seed funding, spend tens of thousands of dollars to give free cocktails to a bunch of nerds? What kind of marketing strategy is this and has this ever worked?


Introducing RND1, the most powerful base diffusion language model (DLM) to date. RND1 (Radical Numerics Diffusion) is an experimental DLM with 30B params (3B active) with a sparse MoE architecture. We are making it open source, releasing weights, training details, and code to…
Given that I haven't worked with JAX very extensively in the past, this is a huge "Today I Learned" moment for me. But let's see how many get it. How much memory do you think this simple statement reserve on the underlying GPU device?

A curious thing I observed in regards to Waymo's Zeekr Fleet is they are always with a human driver in control of the steering wheel. Which makes me wonder - is the autonomous driver that is trained and and being served on the current Jaguar Fleet not transferrable to a…

The Sora 2 app now has an average rating of 2.9. What’s the reason?

Our new Grok Imagine is a step function better than the original. Genuinely kind of mind blowing And it’s free for everyone! No invite codes needed😄
First PyTorch and now React. This is a really good arc where they incubate a stack internally while pushing actively to upstream and once mature, hand it over to none other than the lords of open-source, Linux Foundation. Allows for a lot more neutral governance and more…

Over 10 years ago, we open-sourced React. And now, we’re excited to announce the next chapter: React & React Native are transitioning to the React Foundation under the Linux Foundation. Meta is committing $3M+ and a 5-year partnership to support this next chapter of innovation.…

Big news for developers! Grok Code Fast 1 is now available in Visual Studio. This advanced AI model brings smarter, faster coding assistance right into your favorite IDEs via GitHub Copilot Chat. Available in public preview for Copilot Pro, Pro+, Business, and Enterprise plans,…


The Grid meets reality in this first-of-its-kind partnership between @X, @xai @Tesla, and @WaltDisneyCo, live on X and the TRON: ARES red carpet. The TRON: ARES universe comes alive through an immersive digital world powered by cutting-edge xAI tech, Tesla's Optimus robots, and…


Optimus at the Tron premiere

😂😂😂 Before curing cancer, we need to cure delusion.

There is no inference moat Hasn’t been since 2023 with model compilation from torch 2.0 and consolidation to transformers from DiT Nvidia loses inference market long term on batch to lower TCO (AMD) and real-time (TPU, ASICS)
A quick glance through the SF Tech week event calendar and you see "Yoga for founders", "swimming with founders", "soulcycle with founders and builders", and so on. Now I have the answer to why SF needs a tech week. They are all trying to find people to go to the gym with.
Here's a sneak-peek into my chat with @grok today. It brings all pieces of information, including the visuals right in the chat. Further, I can just select parts from the chat and ask follow-up questions, branch-off to tangential topics and much more. P.S.: Grok strongly…
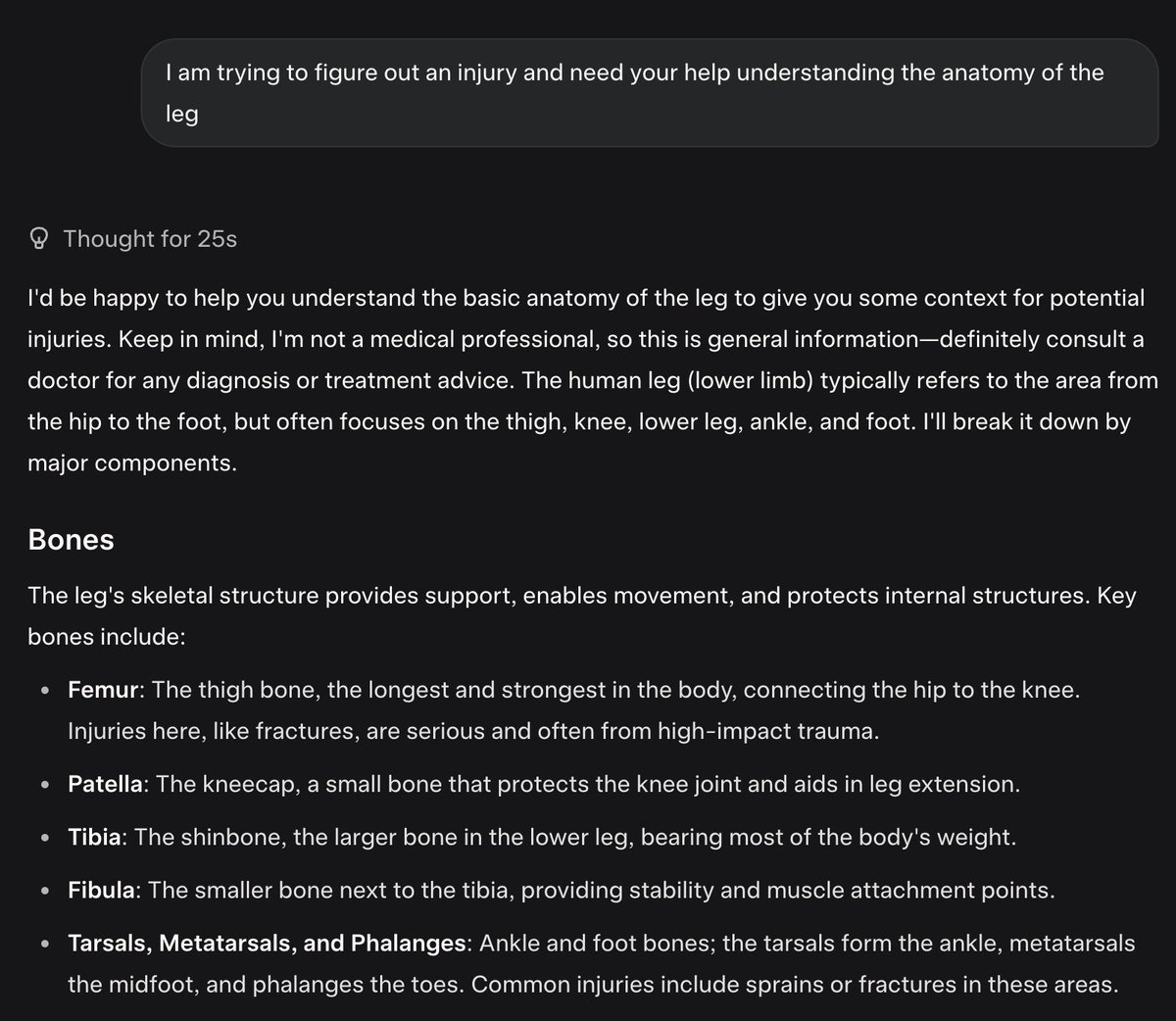

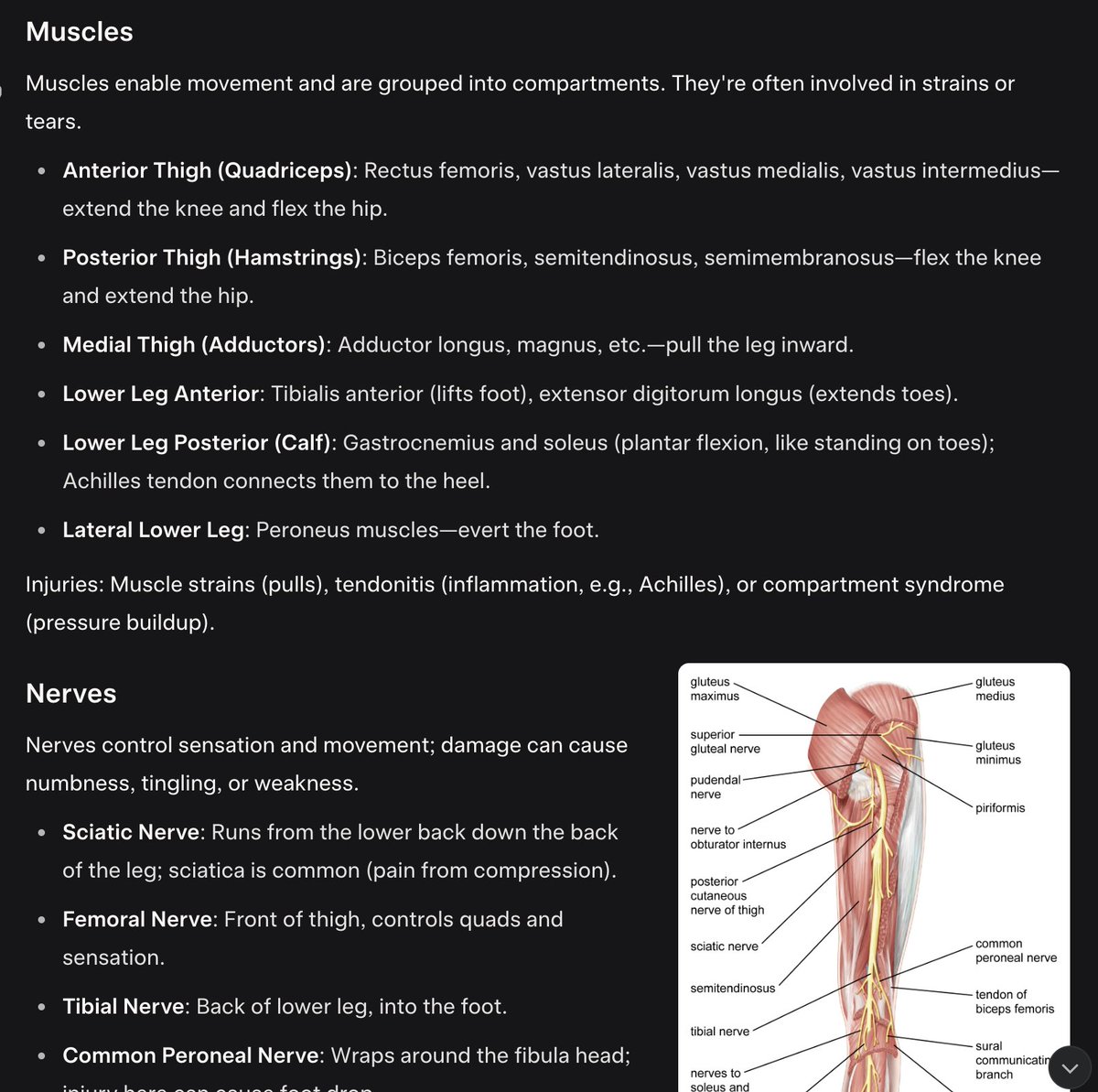
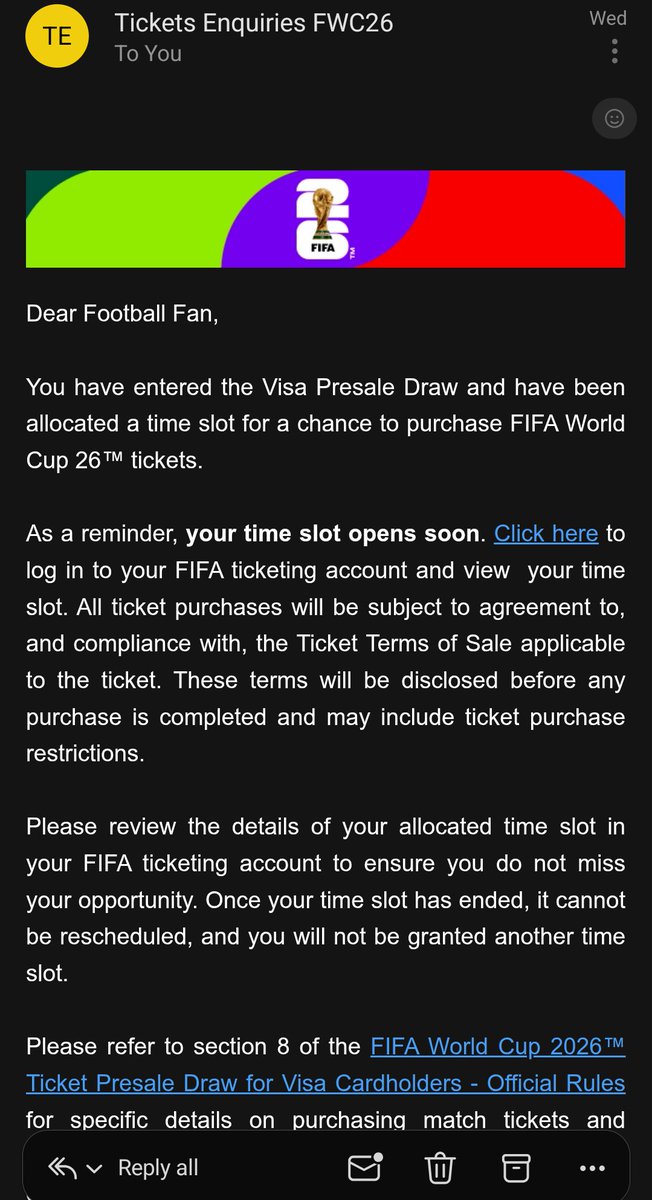
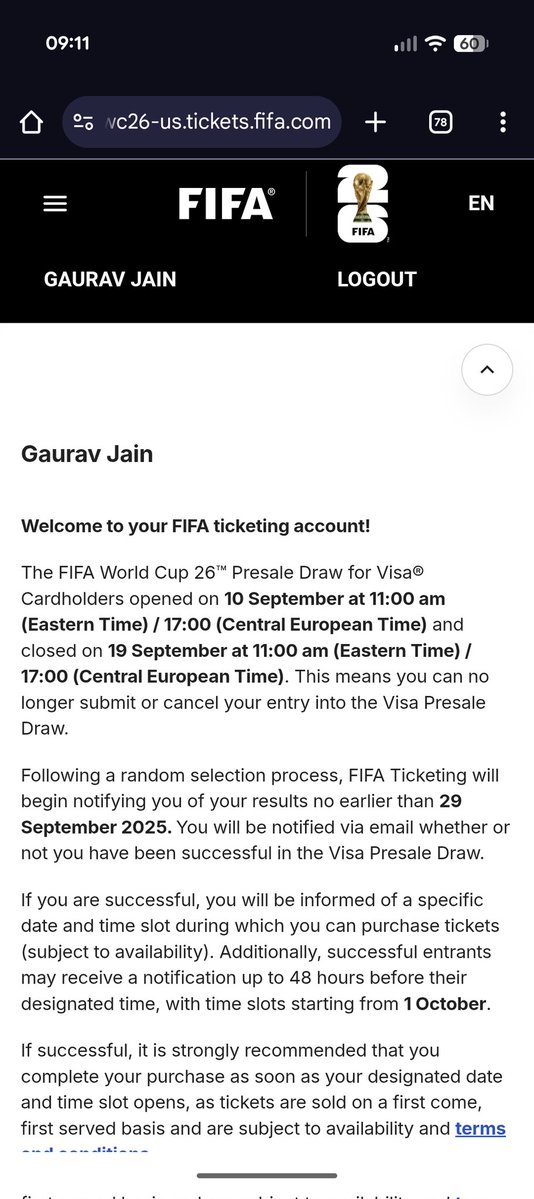
Can someone tell @FIFAcom to get their house in order? They send me one email, just one email about me getting a time slot allocated in the @Visa presale draw and that's all. NO TIME SLOT information on the website, NO INFORMATION in the email, NO CUSTOMER SUPPRT to answer any…
Folks who were online during the browser wars - What made people switch from Internet Explorer and Netscape to Google Chrome? What convinced windows-heavy users to say, well we have a new browser that is not bad, let's give it a try? Do you think a similar thing could be…
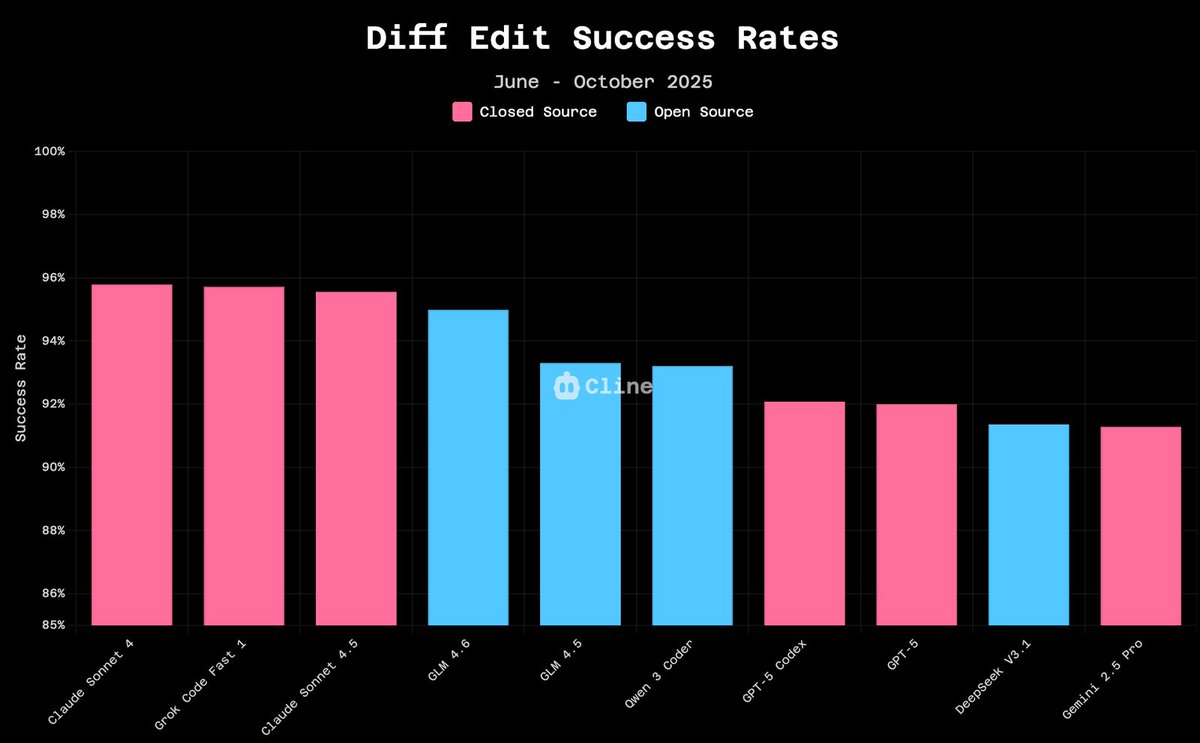
Grok Code Fast is right up there. Higher diff edit success rate than Claude 4.5 and GPT-5 Codex and much much cheaper if I may add. Try it out, don't stop using it and keep sending all that feedback our way. It's only going to get better.

so we analyzed millions of diff edits from cline users and apparently GLM-4.6 hits 94.9% success rate vs claude 4.5's 96.2%. to be clear, diff edits are not the end-all-be-all metric for coding agents. but what's interesting is three months ago this gap was 5-10 points. open…
Very interesting proposition. Variants similar to this have existed but this seems to be way more comprehensive since it offers distributed support from the start. Wondering what's the next obvious step after fine-tuning - RL Training and Environments? And if that's the case,…

Introducing Tinker: a flexible API for fine-tuning language models. Write training loops in Python on your laptop; we'll run them on distributed GPUs. Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!…


























































































United States Trends
- 1. Auburn 42.3K posts
- 2. Brewers 59.2K posts
- 3. Georgia 65.4K posts
- 4. Cubs 54.1K posts
- 5. Kirby 22.3K posts
- 6. Michigan 60.7K posts
- 7. Hugh Freeze 2,998 posts
- 8. #GoDawgs 5,334 posts
- 9. Kyle Tucker 3,017 posts
- 10. Boots 48.9K posts
- 11. #ThisIsMyCrew 3,124 posts
- 12. Amy Poehler 3,073 posts
- 13. Gilligan 5,261 posts
- 14. Jackson Arnold 2,114 posts
- 15. Tina Fey 2,141 posts
- 16. Arizona 41K posts
- 17. #MalimCendari3D 3,047 posts
- 18. Sherrone Moore 2,021 posts
- 19. Nuss 5,634 posts
- 20. #MagicBrew 12K posts
Something went wrong.
Something went wrong.