
Ray Strode
@halfartificial
@halfline alt account for ai related discourse

chinese bros back at it again - train a Decoder-Only transformer < 3 hrs on a 3090 - fully studded with LoRA, DPO, SFT. - well documented training - vision, moe, and other goodies also avail.


Knowledge Graphs give LLMs the context they need to understand your code better This paper presents a novel approach to improve software repository question-answering by combining LLMs with knowledge graphs. The research demonstrates how knowledge graphs can enhance LLMs'…

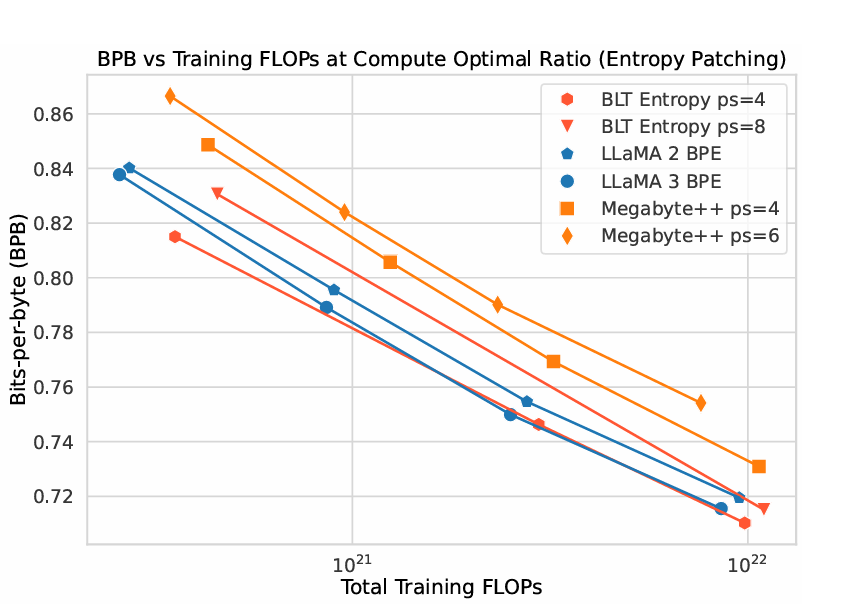
bye bye byte pair encoding. you've served as well, but your time has come.

META JUST KILLED TOKENIZATION !!! A few hours ago they released "Byte Latent Transformer". A tokenizer free architecture that dynamically encodes Bytes into Patches and achieves better inference efficiency and robustness! (I was just talking about how we need dynamic…




canvas is now available to all chatgpt users, and can execute code! more importantly it can also still emojify your writing.
Open-sourced local LLM based RAG, chatting with your documents with open-source LLMs. ✨ It trended at Number-1 in Github for quite sometime. And a clean & customizable RAG UI for chatting with your documents. → Open-source RAG UI for document QA → Supports local LLMs and…


As R&D staff @answerdotai, I work a lot on boosting productivity with AI. A common theme that always comes up is the combination of human+AI. This combination proved to be powerful in our new project ShellSage, which is an AI terminal buddy that learns and teaches with you. A 🧵


Welcome PaliGemma 2! 🤗 Google released PaliGemma 2, best vision language model family that comes in various sizes: 3B, 10B, 28B, based on Gemma 2 and SigLIP, comes with transformers support day-0 🎁 Saying this model is amazing would be an understatement, keep reading ✨

this has instructlab vibes
The First Globally Trained 10B Parameter Model is released. 👏👏 INTELLECT-1 is a groundbreaking 10B parameter LLM trained collaboratively across multiple continents globally using distributed computing, representing a 10x scale-up from previous research. → The model achieved…
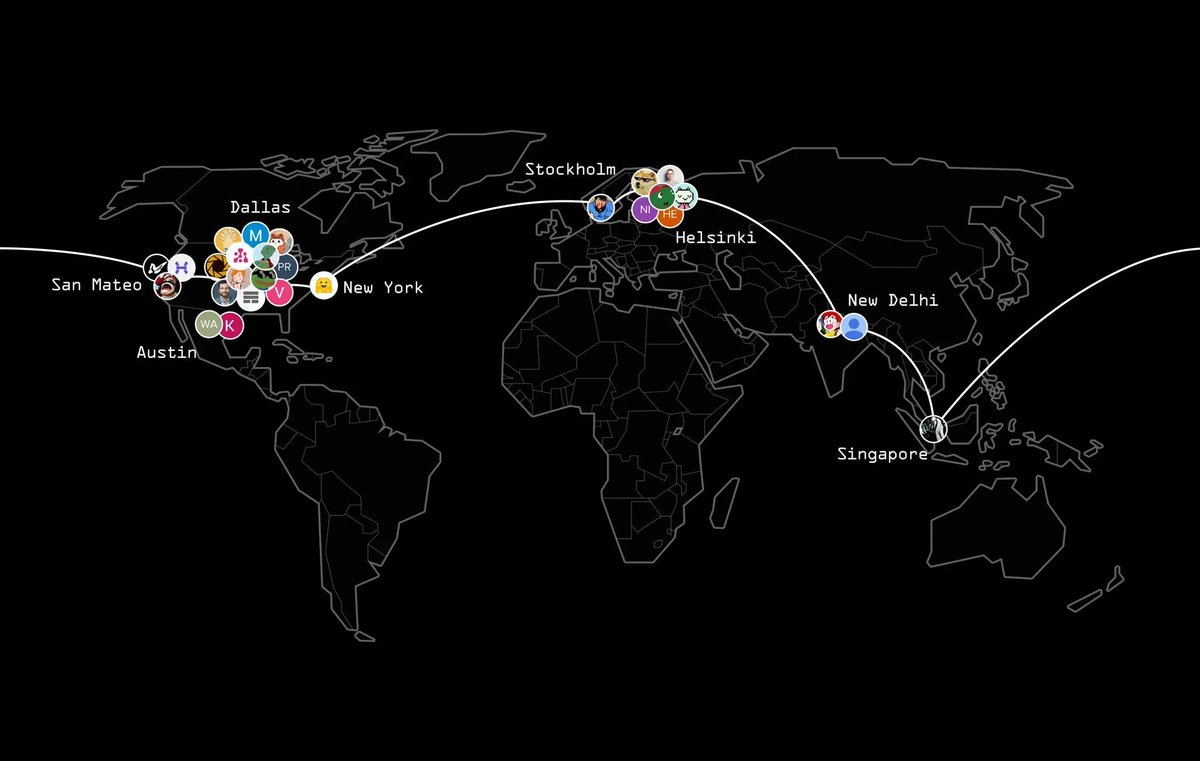

Releasing INTELLECT-1: We’re open-sourcing the first decentralized trained 10B model: - INTELLECT-1 base model & intermediate checkpoints - Pre-training dataset - Post-trained instruct models by @arcee_ai - PRIME training framework - Technical paper with all details

ollama run qwq 🤯 an experimental 32B model by the Qwen team that is competitive with o1-mini and o1-preview in some cases. ollama.com/library/qwq Note: This is the pronunciation of QwQ: /kwju:/ , similar to the word “quill”




Adding rule-based guidance doubles RAG's performance in document retrieval and answer generation. Basically, RAG gets a proper manual on how to use its knowledge. It's like giving RAG a GPS instead of letting it wander around blindly. 🎯 Original Problem: Current…


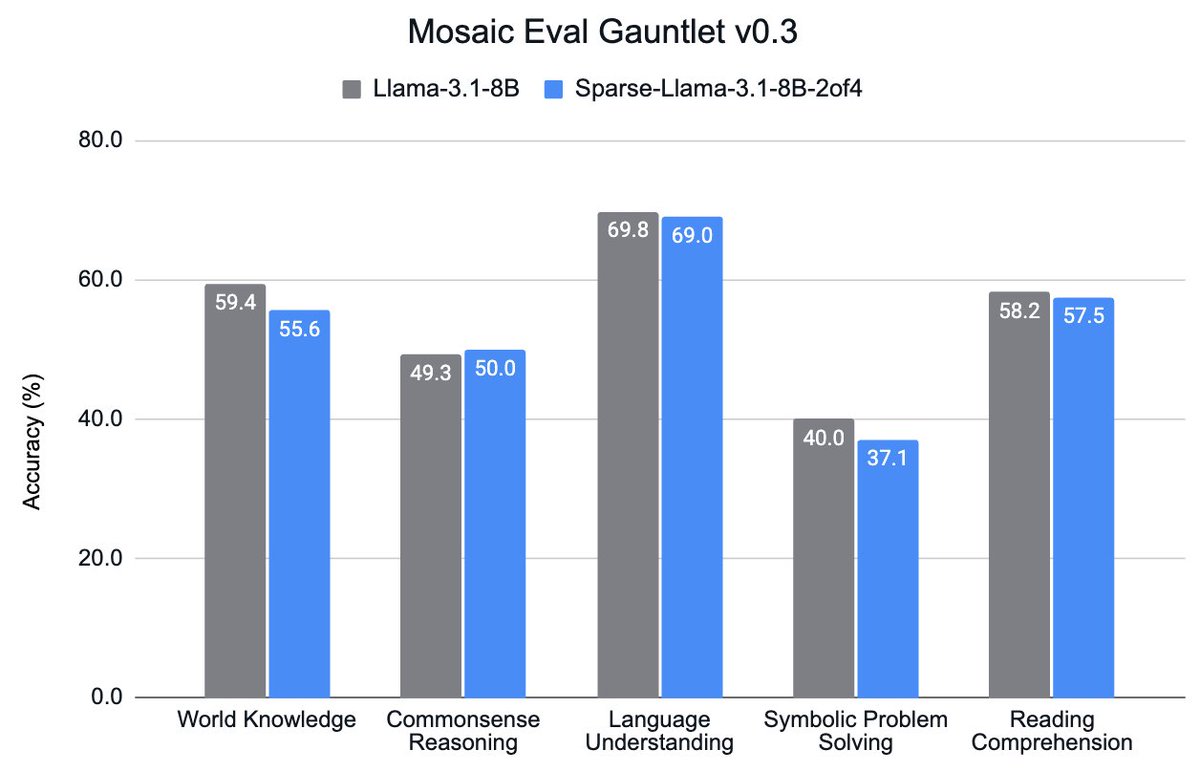
2:4 Sparsity + @AIatMeta Llama-3.1: At @neuralmagic, we've developed a recipe to produce very competitive sparse LLMs, and we are starting by open-sourcing the first one: Sparse-Llama-3.1-8B-2of4. We also show how to leverage it for blazingly fast inference in @vllm_project.

Introducing the Model Context Protocol (MCP) An open standard we've been working on at Anthropic that solves a core challenge with LLM apps - connecting them to your data. No more building custom integrations for every data source. MCP provides one protocol to connect them all:


Hunyuan-Large by Tencent is a 389B param MOE (52B active). It's the largest open-weights MOE. In some benchmarks it exceeds Llama 3.1 405B. With MLX's new 3-bit quant it just barely fits on a single 192GB M2 Ultra! And runs at a very decent >15 toks/sec:

Lightricks just dropped the fastest text-to-video generation mode ever. It can generate videos faster than the time it takes to watch them! Code: github.com/Lightricks/LTX…
llama.cpp/vllm in a container ready to go. cross platform support. models stored in OCI compatible container registries like quay.io

Been working on a new RamaLama project last couple of months. Goal is to make running AI Models inside of containers super easy. Get your AI Models anywhere. This blog announces the today. Try it out. Love to hear your feedback @redhat @openshift @ibm developers.redhat.com/articles/2024/…

"real" and open source reinforcement learning recipe that uses verifiable rewards called tulu is released. Will be used on molmo soon.

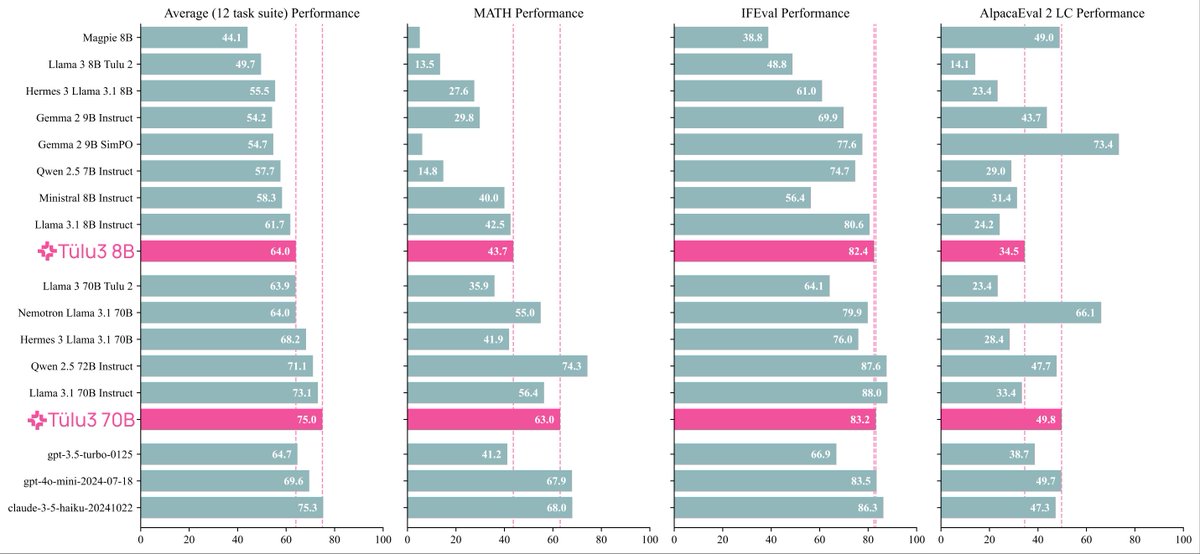
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1…
as with many things, the devil is in the details, and that, includes sparse retrievers like BM25, apparently. Of course, the wider point is to do your own benchmarks and don't rely on feature matrices when choosing an implementation.

chain of thought reasoning exhibited in normally discarded top-k results
Can LLMs reason effectively without prompting? Great paper by @GoogleDeepMind By considering multiple paths during decoding, LLMs show improved reasoning without special prompts. It reveals LLMs' natural reasoning capabilities. LLMs can reason better by exploring multiple…

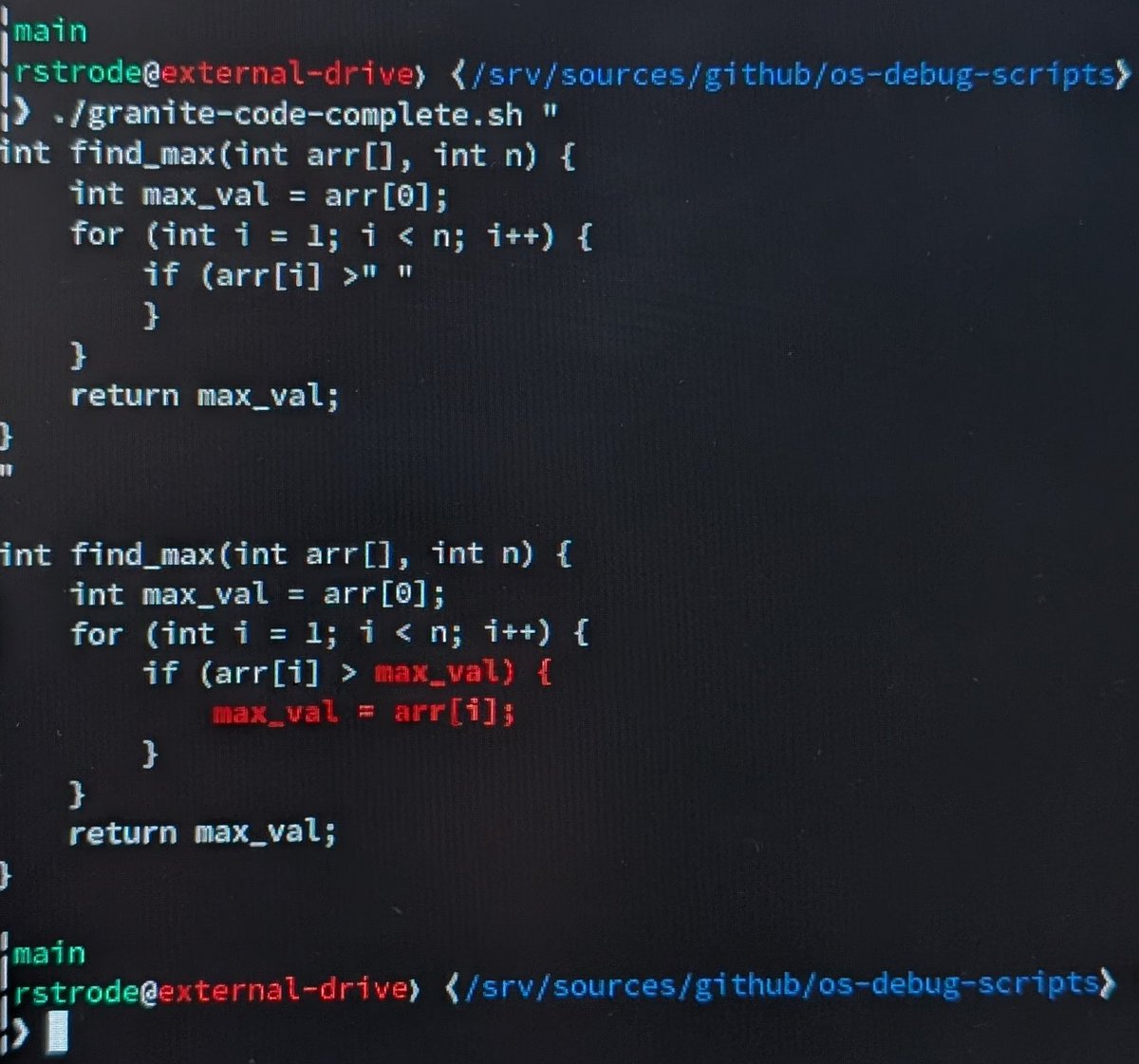
fun little toy script i wrote that uses the granite model to complete a chunk of code github.com/halfline/os-de…








































































United States Trends
- 1. Treylon Burks 6,483 posts
- 2. Bo Nix 5,970 posts
- 3. #BaddiesUSA 12.6K posts
- 4. Mariota 4,077 posts
- 5. Broncos 20.6K posts
- 6. #RaiseHail 3,245 posts
- 7. #RHOP 8,129 posts
- 8. Chicharito 13.5K posts
- 9. Tomlin 22.9K posts
- 10. #Married2Med 2,420 posts
- 11. Steelers 61.4K posts
- 12. Riley Moss 1,104 posts
- 13. #ITWelcomeToDerry 9,367 posts
- 14. Vikings 36.3K posts
- 15. Mark Stoops 4,669 posts
- 16. Maxey 3,778 posts
- 17. Collinsworth N/A
- 18. Chrisean 5,657 posts
- 19. Sean Payton N/A
- 20. Jalen Johnson 3,700 posts
Something went wrong.
Something went wrong.