
Jaehoon Lee
@hoonkp
Researcher in machine learning with background in physics; Member of Technical Staff @AnthropicAI; Prev. Research scientist @GoogleDeepMind/@GoogleBrain.
قد يعجبك















Claude 4 models are here 🎉 From research to engineering, safety to product - this launch showcases what's possible when the entire Anthropic team comes together. Honored to be part of this journey! Claude has been transforming my daily workflow, hope it does the same for you!

Introducing the next generation: Claude Opus 4 and Claude Sonnet 4. Claude Opus 4 is our most powerful model yet, and the world’s best coding model. Claude Sonnet 4 is a significant upgrade from its predecessor, delivering superior coding and reasoning.


@ethansdyer and I have started a new team at @AnthropicAI — and we’re hiring! Our team is organized around the north star goal of building an AI scientist: a system capable of solving the long-term reasoning challenges and core capabilities needed to push the scientific…

woot woot 🎉

Going to be at ICLR next week in Singapore! Excited to see everyone there! If you are interested in test-time scaling, come check out some of our recent work with @sea_snell, @hoonkp, @aviral_kumar2 during the Oral Session 1A! iclr.cc/virtual/2025/o…
Tour de force led by @_katieeverett investigating the interplay between neural network parameterization and optimizers; the thread/paper includes lot of gems (theory insight, extensive empirics, and cool new tricks)!

It was a pleasure working on Gemma 2. The team is relatively small but very capable. Glad to see it get released. On the origin of techniques: 'like Grok', 'like Mistral', etc. is a weird way to describe them as they all originated at Google Brain/DeepMind and the way they ended…

Just analyzed Google's new Gemma 2 release! The base and instruct for 9B & 27B is here! 1. Pre & Post Layernorms = x2 more LNs like Grok 2. Uses Grok softcapping! Attn logits truncated to (-30, 30) & logits (-50, 50) 3. Alternating 4096 sliding window like Mistral & 8192 global…

We recently open-sourced a relatively minimal implementation example of Transformer language model training in JAX, called NanoDO. If you stick to vanilla JAX components, the code is relatively straightforward to read -- the model file is <150 lines. We found it useful as a…

Ever wonder why we don’t train LLMs over highly compressed text? Turns out it’s hard to make it work. Check out our paper for some progress that we’re hoping others can build on. arxiv.org/abs/2404.03626 With @blester125, @hoonkp, @alemi, Jeffrey Pennington, @ada_rob, @jaschasd

Is Kevin onto something? We found that LLMs can struggle to understand compressed text, unless you do some specific tricks. Check out arxiv.org/abs/2404.03626 and help @hoonkp, @alemi, Jeffrey Pennington, @ada_rob, @jaschasd, @noahconst and I make Kevin’s dream a reality.

Proud of this work. Here's my 22min video explanation of the paper: youtube.com/watch?v=TuZhU1…
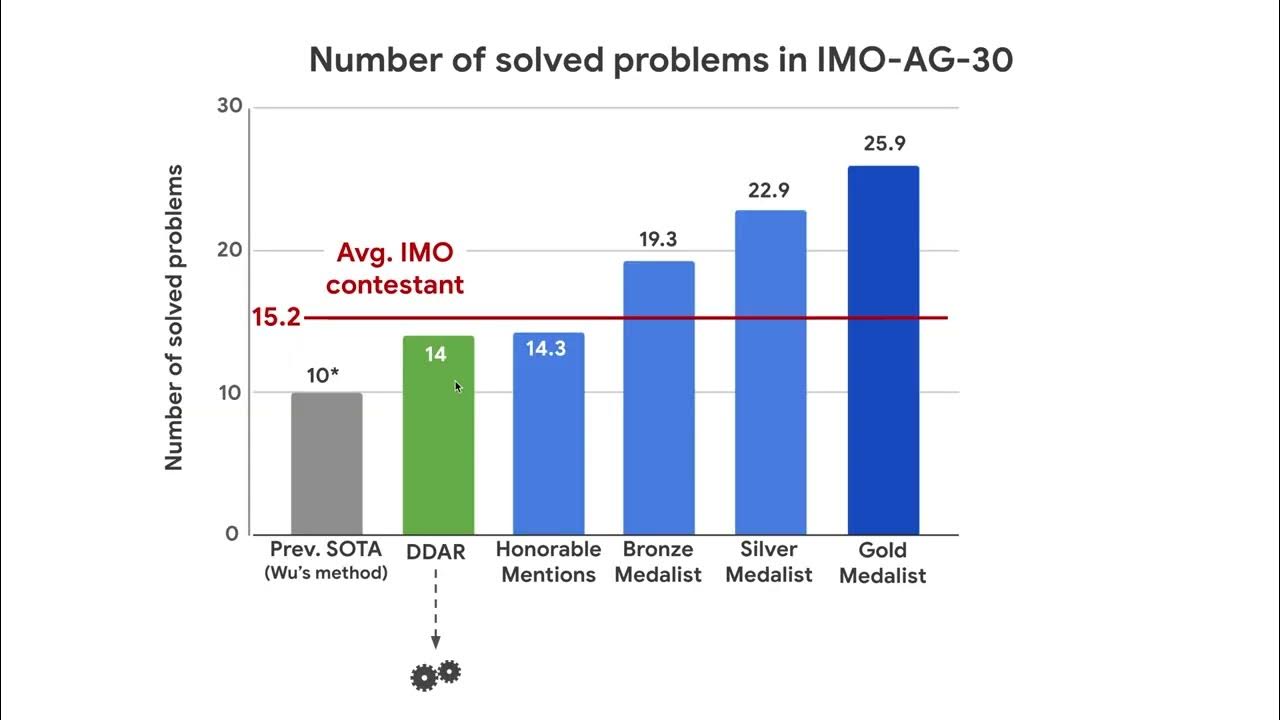
youtube.com
YouTube
AlphaGeometry
This is an awesome opportunity to work with strong collaborators on an impactful science problem! Highly recommended!

Materials Discovery team at Google DeepMind is hiring. If interested, please apply via the link below: boards.greenhouse.io/deepmind/jobs/…
Analyzing training instabilities in Transformers made more accessible by awesome work by @Mitchnw during his internship at @GoogleDeepMind! We encourage you to think more on understanding the fundamental cause and effect of training instabilities as the models scale up!

Sharing some highlights from our work on small-scale proxies for large-scale Transformer training instabilities: arxiv.org/abs/2309.14322 With fantastic collaborators @peterjliu, @Locchiu, @_katieeverett, many others (see final tweet!), @hoonkp, @jmgilmer, @skornblith! (1/15)

This is amazing opportunity to work on impactful problems in Large Language Models with cool people! Highly recommended!
Interested in Reasoning with Large Language Models? We are hiring! Internship: forms.gle/fZzFhsy5yVH6R9… Full-Time Research Scientist: forms.gle/9NB5LaCHjQgXR1… Full-Time Research Engineer: forms.gle/rCRnh5Q1nWmoAK… Learn more about Blueshift Team: research.google/teams/blueshif…

Jasper @latentjasper talking about the ongoing journey towards BIG Gaussian processes! A team effort with @hoonkp, Ben Adlam, @shreyaspadhy and @zacharynado. Join us at NeurIPS GP workshop neurips.cc/virtual/2022/w…

Today at 11am CT, Hall J #806 we are presenting our paper on infinite width neural network kernels! We have methods to compute NTK/NNGP for extended set of activations + sketched embeddings for efficient approximation (100x) for compute intensive conv kernels! See you there!

Most infinitely wide NTK and NNGP kernels are based on the ReLU activation. In arxiv.org/pdf/2209.04121…, we propose a method of computing neural kernels with *general* activations. For homogeneous activations, we approximate the kernel matrices by linear-time sketching algorithms.

Tired of tuning your neural network optimizer? Wish there was an optimizer that just worked? We’re excited to release VeLO 🚲, the first hyperparameter-free learned optimizer that outperforms hand-designed optimizers on real-world problems: velo-code.github.io 🧵
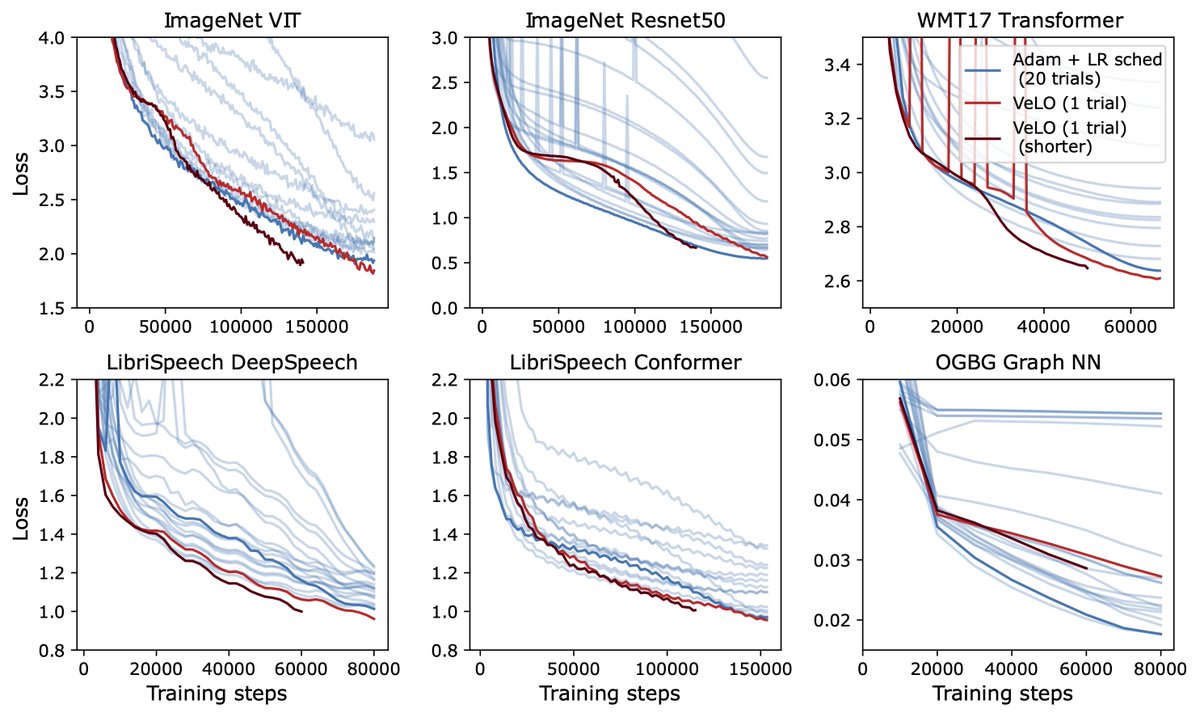
Very interesting paper by @jamiesully2, @danintheory and Alex Maloney investigating theoretical origin of neural scaling laws! Happy to read the 97p paper and learn about new tools in RMT and insights of how statistics of natural datasets are translated into power-law scaling.

New work on the origin of @OpenAI's neural scaling laws w/ Alex Maloney and @jamiesully2: we solve a simplified model of scaling laws to gain insight into how scaling behavior arises and to probe its behavior in regimes where scaling laws break down. arxiv.org/abs/2210.16859 1/

the deadline for applying to the OpenAI residency is tomorrow. if you are an engineer or researcher from any field who wants to start working on AI, please consider applying. many of our best people have come from this program! boards.greenhouse.io/openai/jobs/46… boards.greenhouse.io/openai/jobs/46…

🧮 I finally spent some time learning what exactly Neural Tangent Kernel (NTK) is and went through some mathematical proof. Hopefully after reading this, you will not feel all the math behind NTK is that scaring, but rather, quite intuitive. lilianweng.github.io/posts/2022-09-…

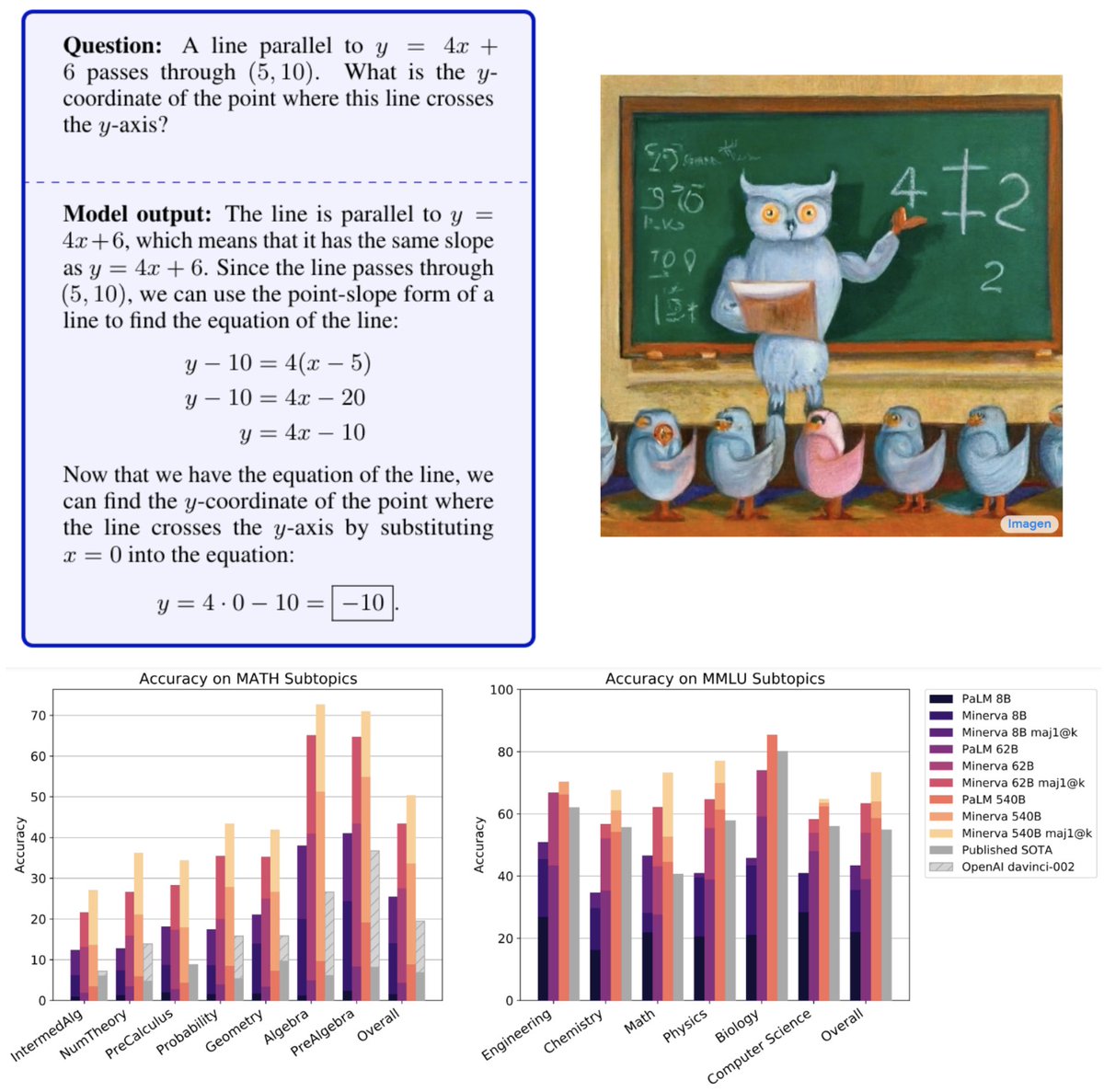
1/ Super excited to introduce #Minerva 🦉(goo.gle/3yGpTN7). Minerva was trained on math and science found on the web and can solve many multi-step quantitative reasoning problems.


Very excited to present Minerva🦉: a language model capable of solving mathematical questions using step-by-step natural language reasoning. Combining scale, data and others dramatically improves performance on the STEM benchmarks MATH and MMLU-STEM. goo.gle/3yGpTN7





















































































































United States الاتجاهات
- 1. Jets 78.9K posts
- 2. Jets 78.9K posts
- 3. Justin Fields 8,027 posts
- 4. Aaron Glenn 4,280 posts
- 5. #HardRockBet 3,301 posts
- 6. Sean Payton 1,928 posts
- 7. London 201K posts
- 8. Garrett Wilson 3,208 posts
- 9. Bo Nix 3,024 posts
- 10. HAPPY BIRTHDAY JIMIN 143K posts
- 11. Tyrod 1,515 posts
- 12. #OurMuseJimin 187K posts
- 13. #DENvsNYJ 2,059 posts
- 14. #JetUp 1,890 posts
- 15. Peart 1,896 posts
- 16. #30YearsofLove 164K posts
- 17. Bam Knight N/A
- 18. Kurt Warner N/A
- 19. Rich Eisen N/A
- 20. Anthony Richardson N/A
قد يعجبك
-
 Jascha Sohl-Dickstein
Jascha Sohl-Dickstein
@jaschasd -
 Greg Yang
Greg Yang
@TheGregYang -
 Tengyu Ma
Tengyu Ma
@tengyuma -
 Sham Kakade
Sham Kakade
@ShamKakade6 -
 Ofir Nachum
Ofir Nachum
@ofirnachum -
 Sam Schoenholz
Sam Schoenholz
@sschoenholz -
 Ben Poole
Ben Poole
@poolio -
 Tom Rainforth
Tom Rainforth
@tom_rainforth -
 Lechao Xiao
Lechao Xiao
@Locchiu -
 Ricky T. Q. Chen
Ricky T. Q. Chen
@RickyTQChen -
 Luke Metz
Luke Metz
@Luke_Metz -
 Yuhuai (Tony) Wu
Yuhuai (Tony) Wu
@Yuhu_ai_ -
 yingzhen
yingzhen
@liyzhen2 -
 Matthew Johnson
Matthew Johnson
@SingularMattrix -
 Rianne van den Berg
Rianne van den Berg
@vdbergrianne
Something went wrong.
Something went wrong.