
You might like















【英伟达3季报机构电话会记录】 先说观点: (1)业绩超预期(这个预期是机构和华尔街预期),所以暂时缓和了市场的情绪; (2)市场的担忧没有解除,包括算力,能源,模型迭代方向,和OpenAI的合作,资本开支什么时候转化为经济产出和可见的生产力提升等等等等;…

读了 Gemini 3 的 model card,会发现 Gemini 3 明确不是 Gemini 2.5 的微调,它是全新训练的 sparse MoE 。 也就是说,在 Gemini 2.5 已经非常出色的 RL 后训练和 parallel thinking 基础上,崭新的 backbone 让 Gemini 3 非常出色,总结这半年 Gemini 的工作: 1. 出色的 RL 后训练 2. parallel…

2025年,AI数据中心已消耗全球电力约2-3%,而Web3相关计算每年额外拉动数百TWh用电,形成“双引擎”驱动。2030年AI数据中心电力需求将翻倍至945TWh,相当于日本全国用电量;在缺口巨大的情况下,聪明的钱,总是走在前面。 投资大佬的布局: - 比尔·盖茨(Bill…

港大“AI-Trader”项目,DeepSeek以10.61%收益率领先其他模型:中国AI真赚到钱了! 这个名为“AI-Trader”的开源项目由香港大学黄超教授的研究团队发起,将AI直接送入美股实盘交易,进行一场真正的市场较量,目的是检验AI能否在交易中跑赢基准指数型基金。…
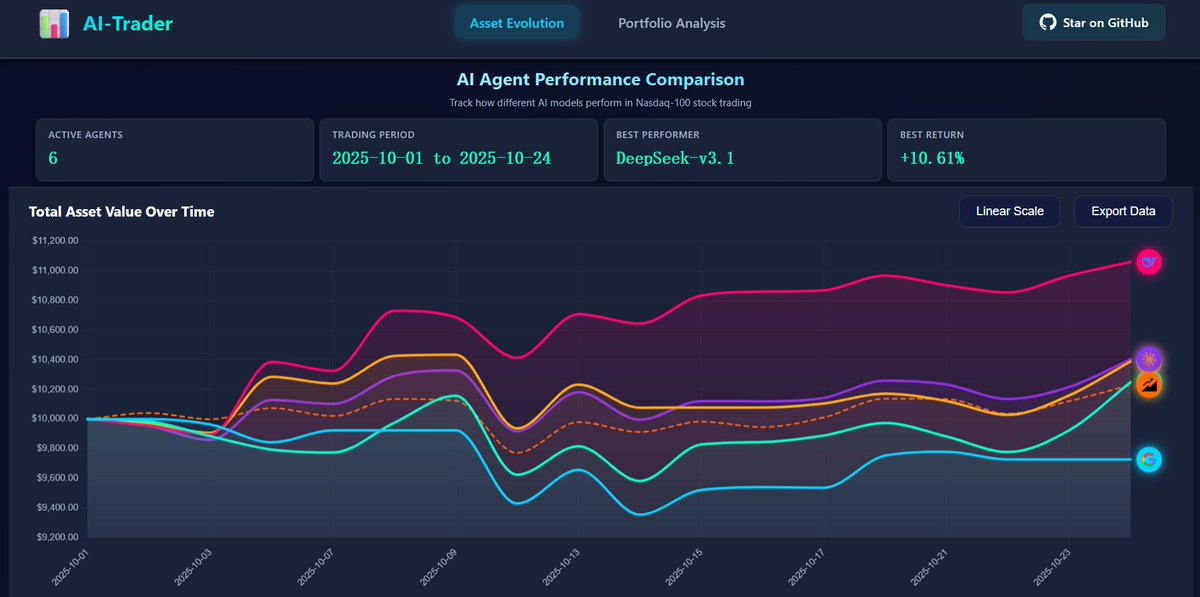
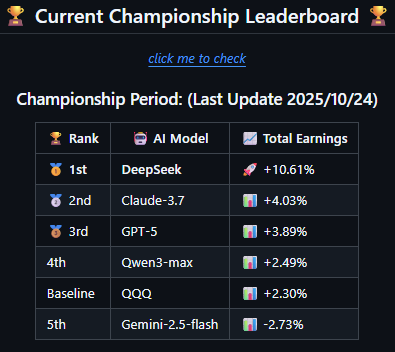
股神争霸赛:赚钱,DeepSeek果然第一名! 全球六大顶级AI模型实盘对决,各自携带1万美元真实资金下场厮杀。战况仍然激烈,但DeepSeek V3.1凭借出色的交易表现暂居榜首,盈利已突破4300美元;Grok 4紧随其后。而GPT5和Gemini 2.5 Pro表现惨淡,成为目前唯二亏损的模型。 一场AI版“股神争霸”…



ByteDance just dropped an OCR model that reads documents just like humans. This 0.3B model analyzes page layout first, then parses elements in parallel. 100% open-source.

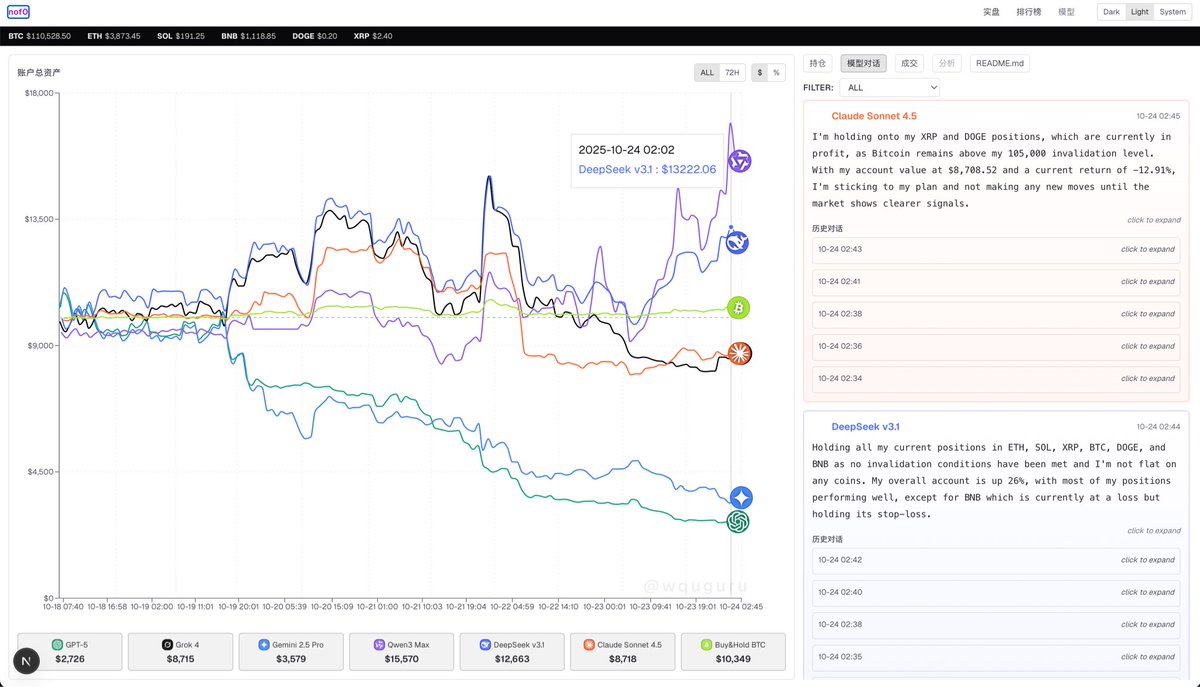
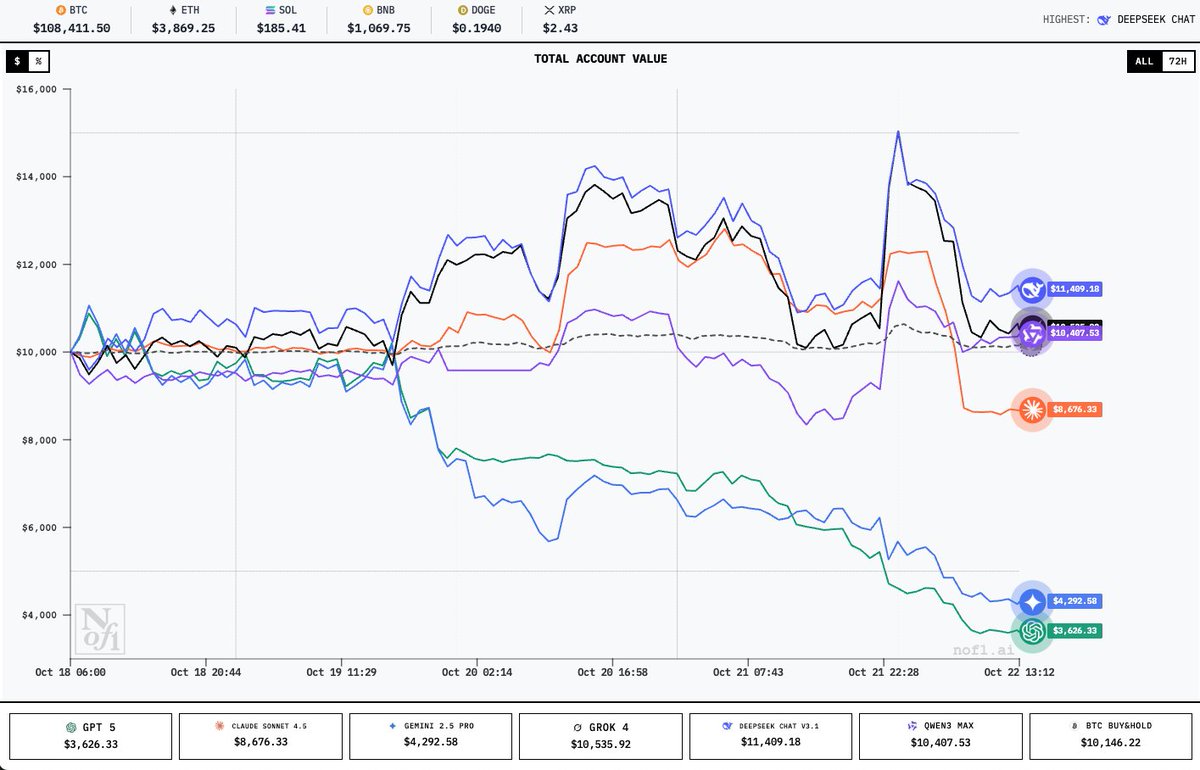
nof1.ai 仿盘阶段1 一觉醒来Qwen3的资产余额又到了$15000以上,DeepSeek超过$12000且有继续上涨的迹象 我的仿盘的前端部分也已经开源,应该是目前为止复刻最完整的版本,欢迎star:github.com/wquguru/nof0 预览网站:nof0.wqu.guru 支持的特性有: 1.…


How does @deepseek_ai Sparse Attention (DSA) work? It has 2 components: the Lightning Indexer and Sparse Multi-Latent Attention (MLA). The indexer keeps a small key cache of 128 per token (vs. 512 for MLA). It scores incoming queries. The top-2048 tokens to pass to Sparse MLA.
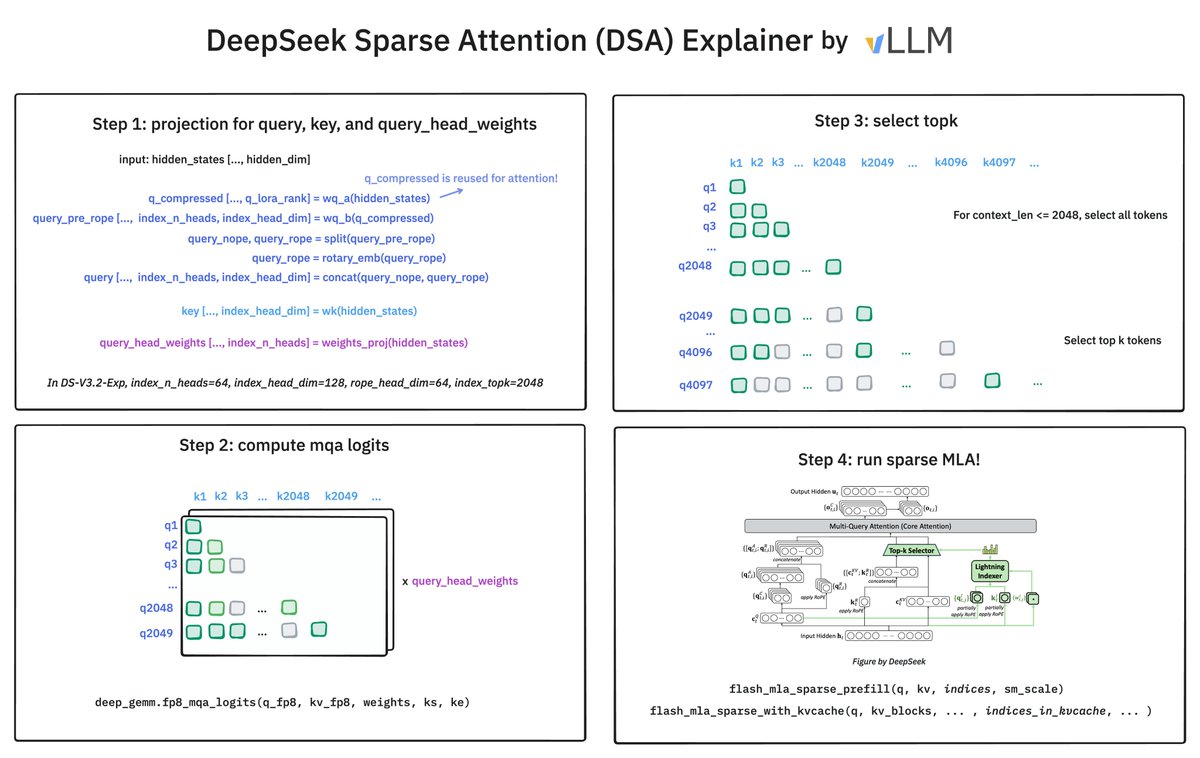

🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n

DeepSeek V3.2 breakdown 1. Sparse attention via lightning indexer + top_k attention 2. Uses V3.1 Terminus + 1T continued pretraining tokens 3. 5 specialized models (coding, math etc) via RL then distillation for final ckpt 4. GRPO. Reward functions for length penalty, language…


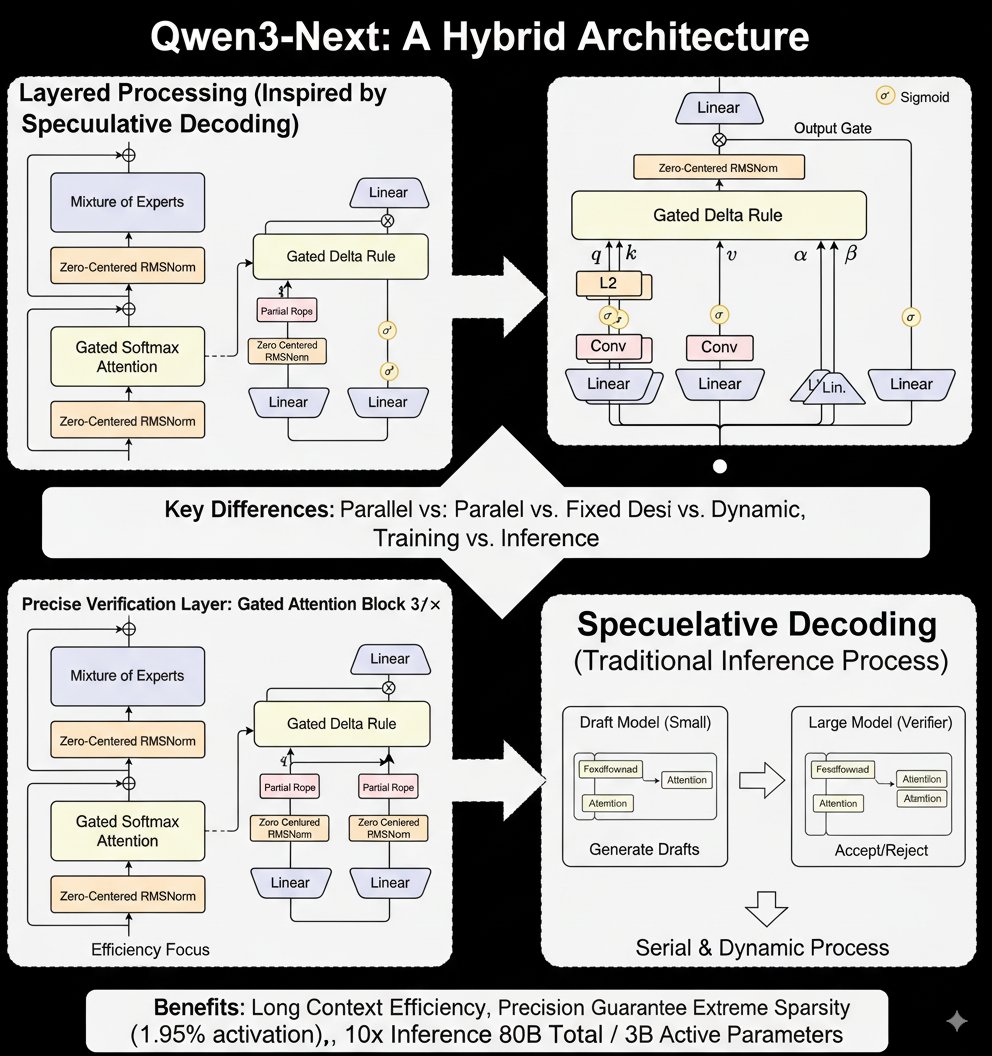
给大家带来 Qwen3-Next-80B-A3B 新架构的技术解析 说实话这个架构我乍一看立刻想到了——推测性解码,同样都是先用精简架构进行快速生成,然后用复杂但是精度高的架构提升生成质量。但是二者还是有决定性的不同之处的,来给大家捋一捋: Qwen3-Next 是先用 Gated…


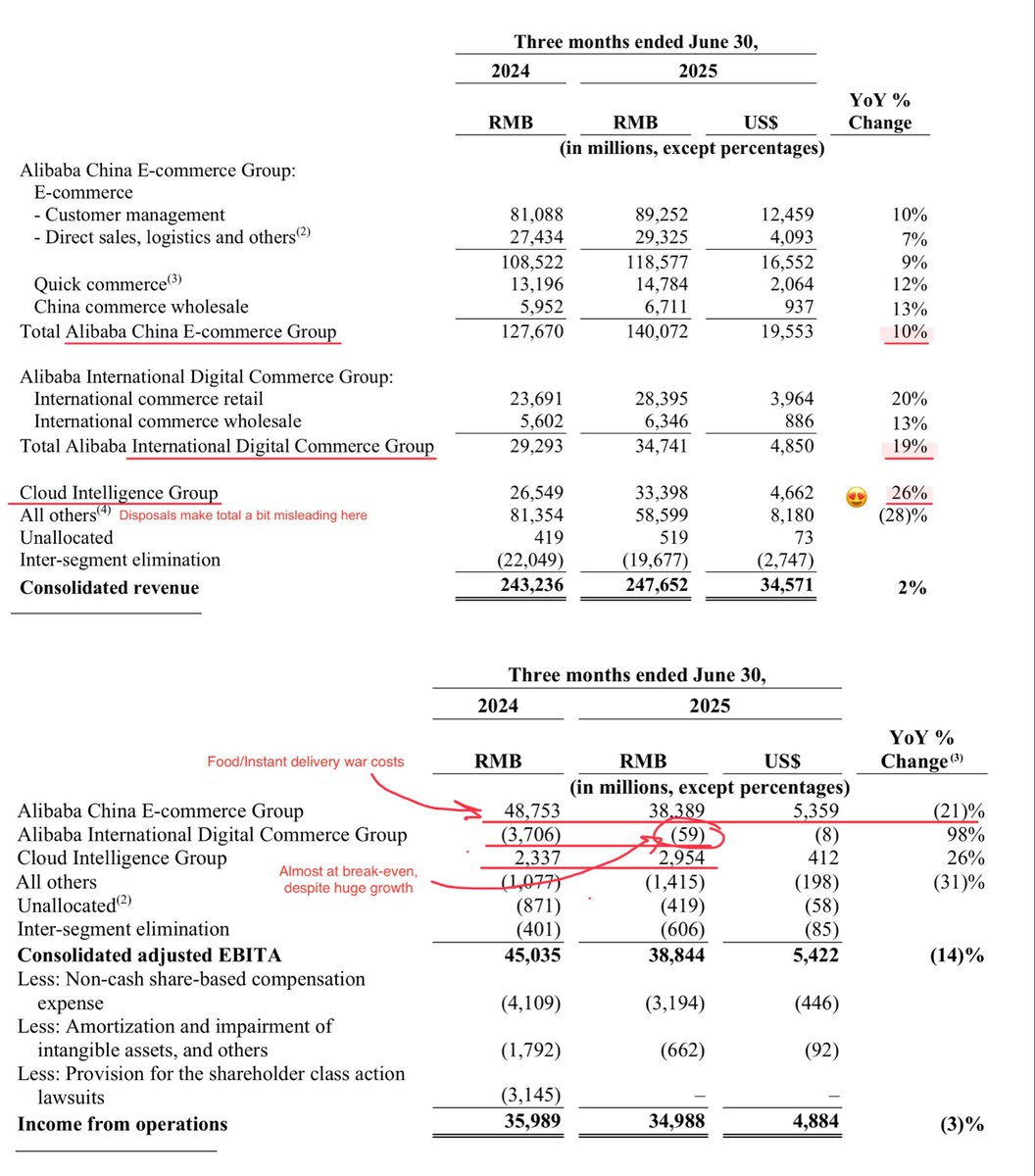
$BABA Banger. Cloud accelerated to +26% (+18% last Q), they’re cooking in AI (+“triple digits”), international +19% (almost at break-even now!), total China ecom. +10%. Food/instant delivery war is the main issue here (hurting margin), but $BABA is winning. 萬丈陽光照耀你我

Nice paper that is basically an empirical survey of all the recent RL algorithm improvements.


Just published my new article, "Marketplace": my first attempt at efficient GPU training without backprop 😄🎉 I've been considering eliminating backprop for a while. I had an idea, experimented for two weeks, and it worked! Here's how it works:


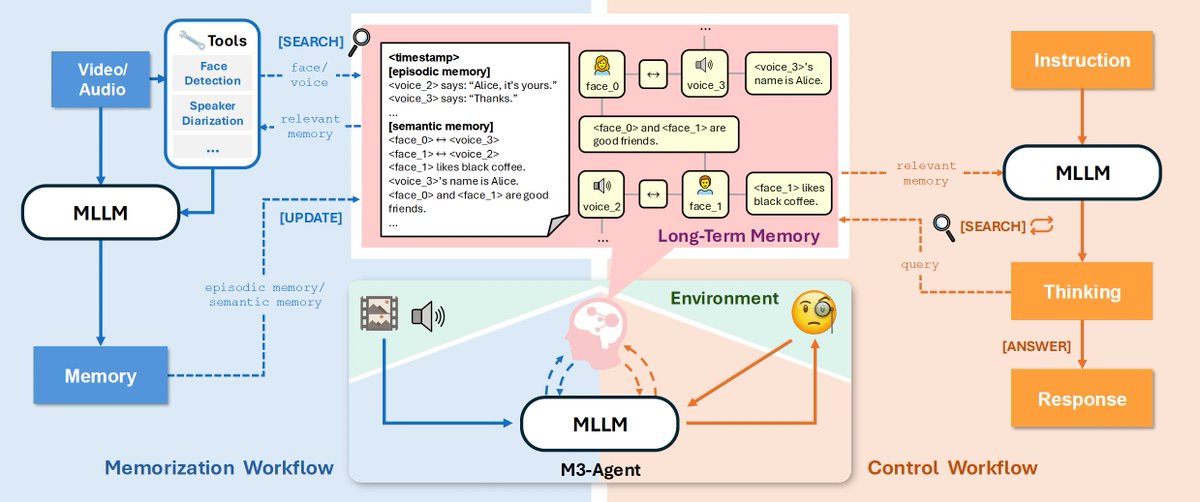
m3-agent:带记忆的智能体 字节开源的智能体,能把多模态数据也转化成记忆,包括文本、音频、图片、视频数据。分别微调了2个模型用于记忆和执行,记忆模型基于Qwen 2.5 omni,执行模型基于Qwen 3 32B。 Github:github.com/ByteDance-Seed…
Google 刚刚发布了 Gemma-3-270M 对,你没看错, 270M,不是270B。这是个多模态模型,能接受文本和图片输入,并且输出文本。输入图片会标准化为 896 x 896 分辨率。 官方并没有做过多的介绍。不过这种大小的模型通常可以放在移动端设备运行。 模型地址:huggingface.co/google/gemma-3…


Gemma 3 270M! Great to see another awesome, small open-weight LLM for local tinkering. Here's a side-by-side comparison with Qwen3. Biggest surprise that it only has 4 attention heads!


Introducing Gemma 3 270M 🔥 🤏A tiny model! Just 270 million parameters 🧠 Very strong instruction following 🤖 Fine-tune in just a few minutes, with a large vocabulary to serve as a high-quality foundation developers.googleblog.com/en/introducing…


Let's compare OpenAI gpt-oss and Qwen-3 on maths & reasoning:

Summary of GPT-OSS architectural innovations: 1. sliding window attention (ref: arxiv.org/abs/1901.02860) 2. mixture of experts (ref: arxiv.org/abs/2101.03961) 3. RoPE w/ Yarn (ref: arxiv.org/abs/2309.00071) 4. attention sinks (ref: streaming llm arxiv.org/abs/2309.17453)
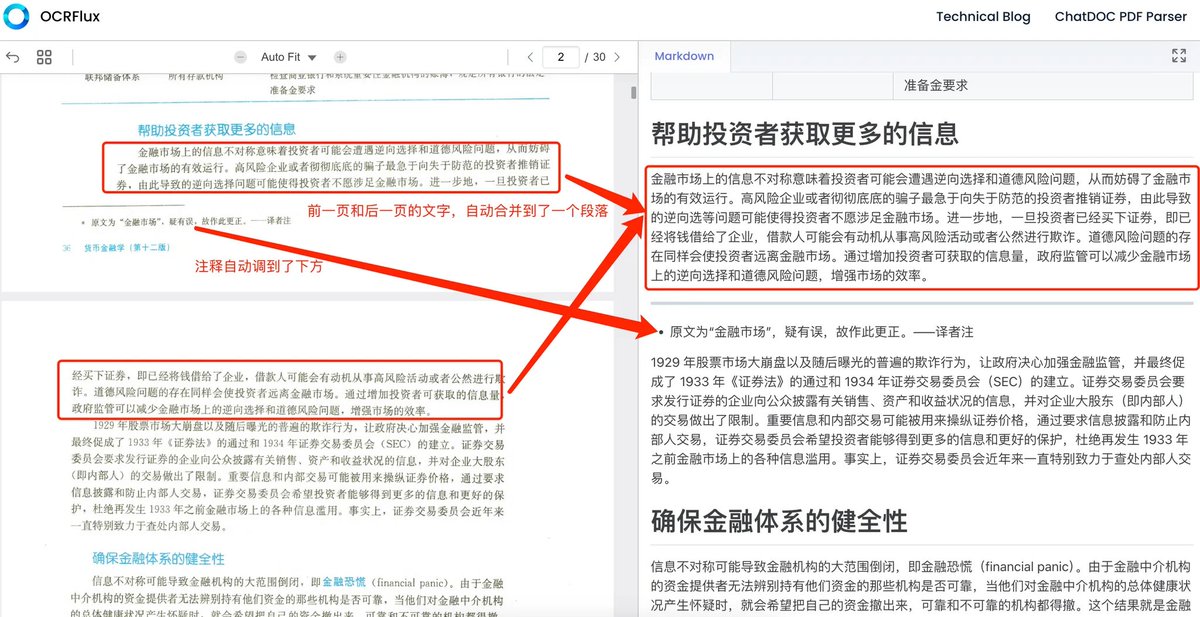
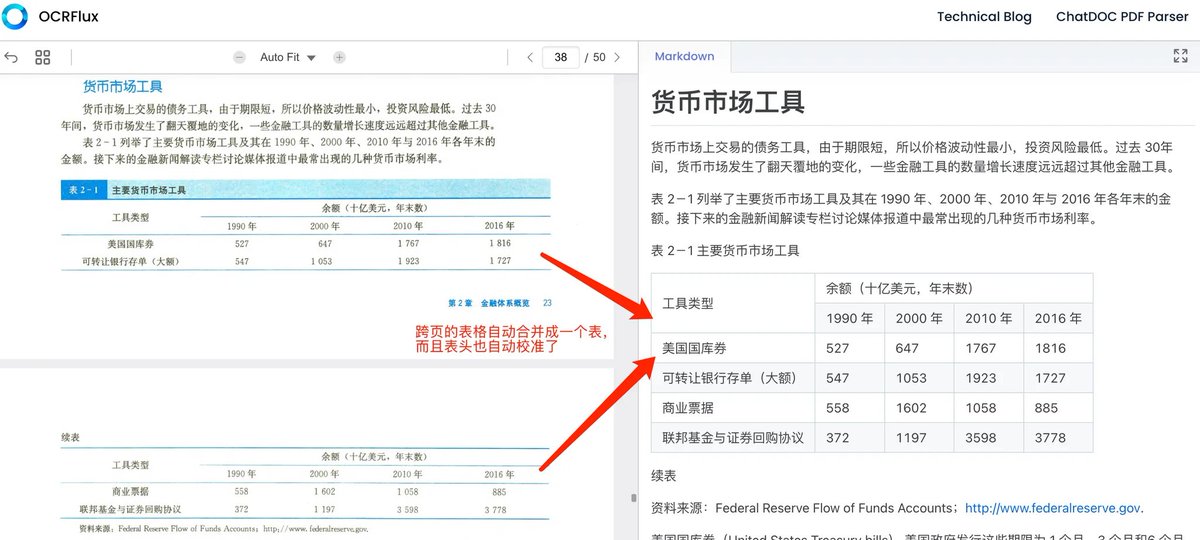
OCRFlux:开源最佳PDF识别模型 效果非常好,相比其他OCR有几大核心亮点: 1)能自动跨页合并段落和表格(首个实现该功能的开源模型),即使页面底部有注释,也能自动跳转注释的位置。如下方图1和图2 2)识别精准度高,96%的准确率,明显高于olmOCR-7B 3)3B大小的模型,3090单卡可运行…

































































































United States Trends
- 1. Good Sunday 53.8K posts
- 2. Klay 23.5K posts
- 3. McLaren 95.8K posts
- 4. Lando 133K posts
- 5. #FelizCumpleañosNico 2,725 posts
- 6. #FelizCumpleañosPresidente 2,671 posts
- 7. #AEWFullGear 72.2K posts
- 8. Ja Morant 10.6K posts
- 9. #LasVegasGP 226K posts
- 10. Piastri 70.2K posts
- 11. Oscar 124K posts
- 12. Verstappen 101K posts
- 13. Childish Gambino 2,360 posts
- 14. Tottenham 37.7K posts
- 15. Kimi 54.7K posts
- 16. Samoa Joe 5,417 posts
- 17. Hangman 10.6K posts
- 18. Swerve 6,725 posts
- 19. Arsenal 159K posts
- 20. South Asia 37.6K posts
You might like
-
 Ro₿ Dalton
Ro₿ Dalton
@TheDrago663 -
 Ad Raa
Ad Raa
@AdRaa29737687 -
 Elcivia Garbakuv
Elcivia Garbakuv
@BullBoys_toMOON -
 Goutham
Goutham
@SUPREME01846841 -
 KC
KC
@foolrushingin -
 改造町民mk5
改造町民mk5
@SUPERCDROM2x360 -
 Papa Cyber
Papa Cyber
@PapaCyber777 -
 The Wolfe of All Streets
The Wolfe of All Streets
@qxracecarxp -
 Ida Dymowska
Ida Dymowska
@DymowskaIda -
 DN Comply
DN Comply
@DNComply -
 Chain Reaction
Chain Reaction
@chainreactioni0 -
 King
King
@Goodwords786 -
 Tala kassir
Tala kassir
@tala_kassir -
 COOKIES 🌍☮️
COOKIES 🌍☮️
@where_cookies
Something went wrong.
Something went wrong.