
David J Wu
@lightvector1
Researcher, game AI enthusiast, author of KataGo (https://katagotraining.org/)
You might like















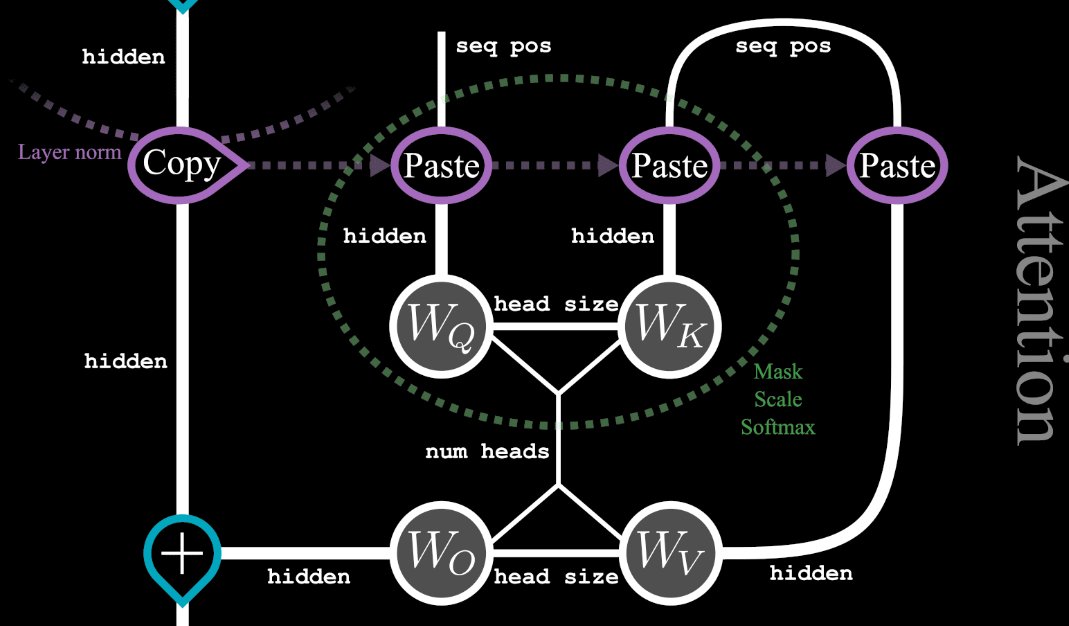
Wooo, tensor diagrams are cool. (Transformer self-attention layer, from greaterwrong.com/posts/BQKKQiBm…)

I always found the tensor notation in Fast Matrix Multiplication algorithms confusing. But using tensor diagrams it's pretty easy to see what's going on:

Even though we've known from word2vec and much work since that LLM representations correlate well with human concepts (both in linear additivity, distance/clustering, etc), I still find it cool that it holds up with larger models so far. Lots of space to explore further.

New Anthropic research paper: Scaling Monosemanticity. The first ever detailed look inside a leading large language model. Read the blog post here: anthropic.com/research/mappi…

SOTA AI for games like poker & Hanabi rely on search methods that don’t scale to games w/ large amounts of hidden information. In our ICLR paper, we introduce simple search methods that scale to large games & get SOTA for Hanabi w/ 100x less compute. 1/N arxiv.org/abs/2304.13138

There are tons of articles on MCTS, which wastes compute whenever paths lead to the same state, but few on Monte-Carlo *Graph* Search, which doesn't. But implementing MCGS soundly can be tricky! Here's a doc on how to do it, and the theory behind it: github.com/lightvector/Ka…
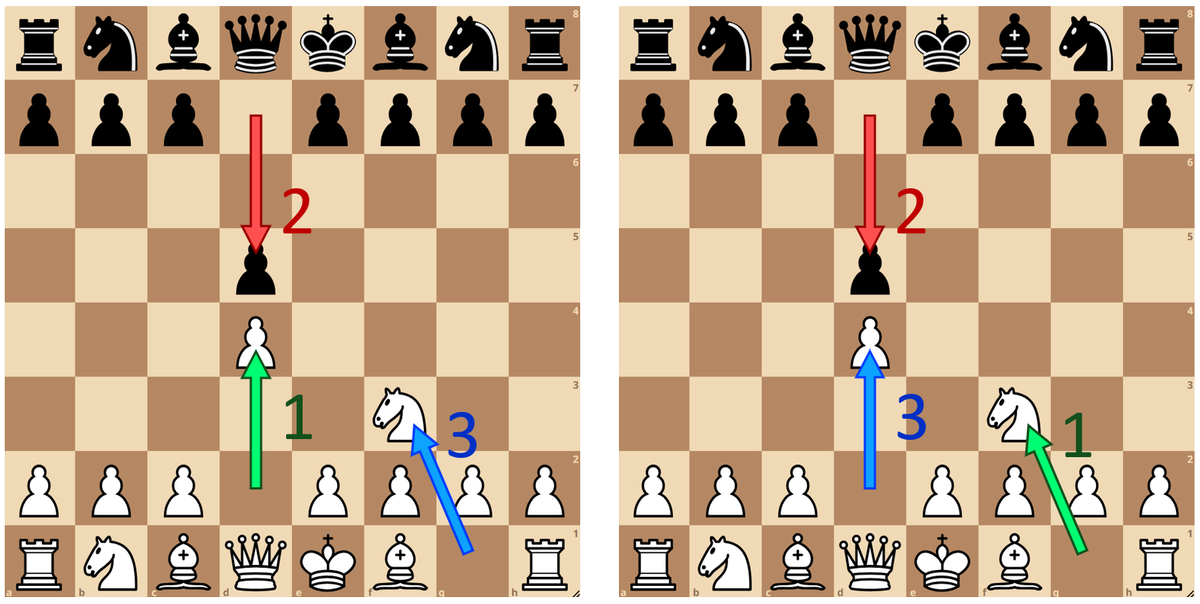

In the recent paper arxiv.org/abs/2402.04494 @GoogleDeepMind introduced a transformer chess network, but didn't include Lc0 in their comparison. We've used transformers for a while, and our network is stronger with fewer parameters. More details soon.

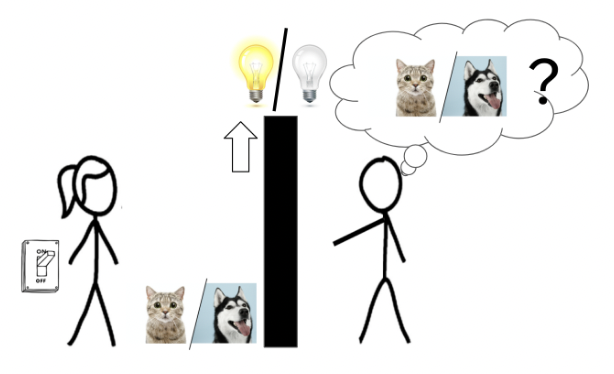
There are two shapes below: one is named “kiki” and one is named “bouba”. Which is which? This is the puzzle we consider in our ICML paper: Learning Intuitive Policies Using Action Features. 1/N arxiv.org/abs/2201.12658 ⚫ ✴
221 vote · Final results

What is off-belief learning and how does it help us build agents that coordinate only in grounded ways ? Part 1 of a new blog series on intuitive summaries of key ideas in multi-agent RL: eugenevinitsky.github.io/posts/Off-Beli…

Here's my conversation with Noam Brown (@polynoamial), co-creator of AI systems that achieve superhuman level performance in games of poker and Diplomacy that involves strategic negotiations with humans. This was a fascinating, technical conversation. youtube.com/watch?v=2oHH4a…


Did you know, that you can build a virtual machine inside ChatGPT? And that you can use this machine to create files, program and even browse the internet? engraved.blog/building-a-vir…

We know that search can be a powerful RL policy improvement method, (e.g. search outperforms the raw policy by 2000 Elo in AlphaGoZero!). One challenge is how to get this kind of RL to be robust when also needing to remain compatible with humans or other agents. Our work on how:

After building on years of work from MILA, DeepMind, ourselves, and others, our AIs are now expert-human-level in no-press Diplomacy and Hanabi! Unlike Go and Dota, Diplomacy/Hanabi involve *cooperation*, which breaks naive RL. arxiv.org/abs/2210.05492 arxiv.org/abs/2210.05125 🧵👇

We have a new paper out! It is well-known that in many games the raw policy of an SL model can blunder in silly ways even after extensive training. Search seems to capture a component of human planning that deep neural nets have difficulty fitting or modeling on their own.
⭐New paper⭐ How do you build AI agents that are both strong and human-like? Regularize search towards a human policy! In chess, Go and no-press Diplomacy, we get SOTA human prediction accuracy while being much stronger than imitation learning. arxiv.org/abs/2112.07544 (1/9)🧵👇

























































































United States Trends
- 1. Ellison N/A
- 2. Marner N/A
- 3. Macklin Celebrini N/A
- 4. Real ID N/A
- 5. #thursdayvibes N/A
- 6. Czechia N/A
- 7. #SpiderNoir N/A
- 8. Sakkari N/A
- 9. Augusta N/A
- 10. Mark Stone N/A
- 11. Brody King N/A
- 12. Bo Horvat N/A
- 13. Ron Johnson N/A
- 14. Dostal N/A
- 15. McDavid N/A
- 16. Gemini 3 Deep Think N/A
- 17. Max Muncy N/A
- 18. ATMs N/A
- 19. Team Canada N/A
- 20. The Dow N/A
You might like
-
 Weiyan Shi
Weiyan Shi
@shi_weiyan -
 Mike Lewis
Mike Lewis
@ml_perception -
 Barret Zoph
Barret Zoph
@barret_zoph -
 Athul Paul Jacob
Athul Paul Jacob
@apjacob03 -
 Qinqing Zheng
Qinqing Zheng
@qqyuzu -
 Colin Flaherty
Colin Flaherty
@colin__flaherty -
 Jack Parker-Holder
Jack Parker-Holder
@jparkerholder -
 Minae Kwon
Minae Kwon
@MinaeKwon -
 Daniel Fried
Daniel Fried
@dan_fried -
 Archit Sharma
Archit Sharma
@archit_sharma97 -
 Emily Dinan
Emily Dinan
@em_dinan -
 Hugh Zhang
Hugh Zhang
@hughbzhang -
 Jonathan Gray
Jonathan Gray
@jgrayatwork -
 Samuel Sokota
Samuel Sokota
@ssokota -
 Alexis Ross
Alexis Ross
@alexisjross
Something went wrong.
Something went wrong.