
Pablo Montalvo
@m_olbap
ML Engineer @HuggingFace. Previously ML R&D @ Rakuten. Computer vision and NLP mixer, ex-physicist. Dice thrower, dreamer, learner. He/him. Usually friendly :)
You might like
















A few days ago, @thinkymachines released “LoRA Without Regret”, showing that LoRA can match full fine-tuning performance when configured right. Naturally, we decided to reproduce the results with TRL and release a guide

You need to try this tool! 🫡 My colleague @m_olbap built an interactive HF Space to explore the modular support of open models in transformers over time 👀 You’ll spot things like 🦙 llama defining many models or which ones could be modular next

Why is your KV so small? 🤏 In continuous batching, if you increase the max number of tokens per batch, you must decrease the memory allocated for your cache. In transformers, we make sure they are perfectly balanced (as all things should be). No matter how big your model is🦠🐋
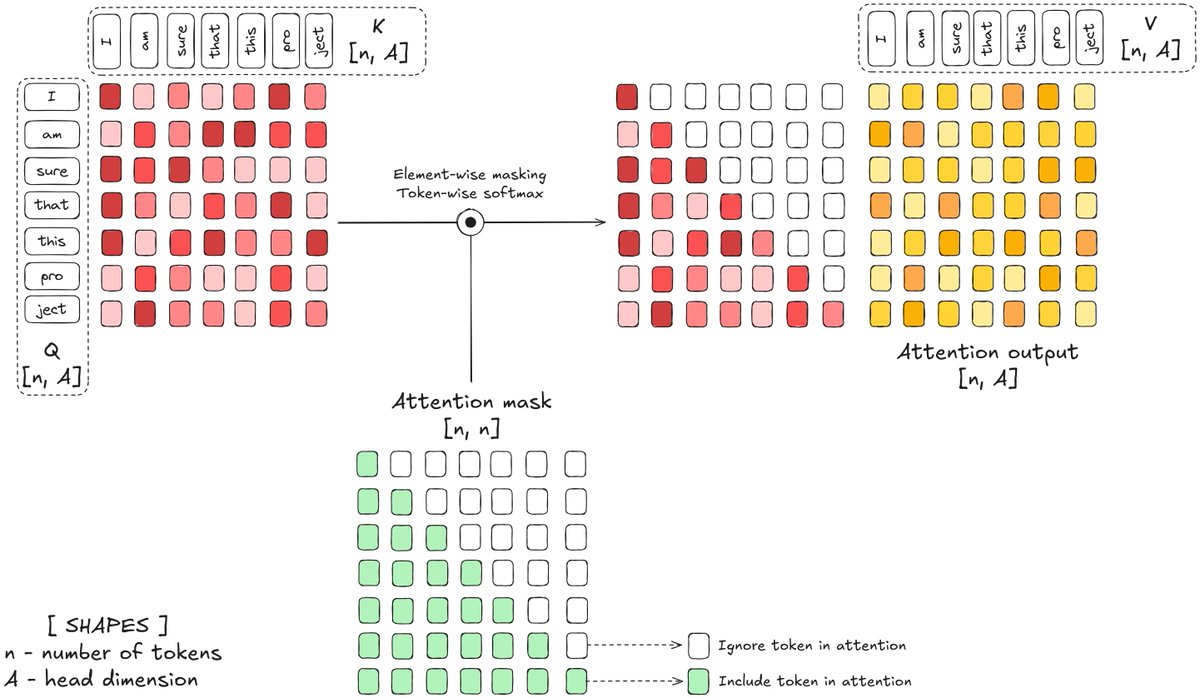
You have no idea what attention looks like 🤥 Many talk about attention like it's simple, but few know how it actually works. Even basic stuff like shapes and prefill / decode are not that easy to grasp. Good thing HF is cooking a blogpost to help you out 🫂
Ever wondered how models actually see an image? Been playing with some visualizations of patch extraction, token layouts, how they affect predictions too. Planning a short visual deep dive comparing how different models process images. Would love thoughts before I go on.

A quick update on the future of the `transformers` library! In order to provide a source of truth for all models, we are working with the rest of the ecosystem to make the modeling code the standard. A joint effort with vLLM, LlamaCPP, SGLang, Mlx, Qwen, Glm, Unsloth, Axoloth,…

The Transformers library is undergoing it's largest pivot to date 🙌 It now cements its role as the central model definition, irrespective of the backend and runner. One ground truth to bring more reliability across the ecosystem. Why is this important?




























































































United States Trends
- 1. Auburn 43.8K posts
- 2. Brewers 61.5K posts
- 3. Georgia 66.7K posts
- 4. Cubs 54.4K posts
- 5. Kirby 23.2K posts
- 6. Arizona 41.2K posts
- 7. Michigan 62.1K posts
- 8. Hugh Freeze 3,130 posts
- 9. #BYUFOOTBALL N/A
- 10. Gilligan 5,526 posts
- 11. Boots 50K posts
- 12. #GoDawgs 5,475 posts
- 13. Kyle Tucker 3,105 posts
- 14. Amy Poehler 3,790 posts
- 15. #ThisIsMyCrew 3,188 posts
- 16. Utah 23.3K posts
- 17. Tina Fey 2,788 posts
- 18. #Toonami 1,887 posts
- 19. #MalimCendari3D 3,500 posts
- 20. Jackson Arnold 2,161 posts
You might like
-
 Adina Yakup
Adina Yakup
@AdinaYakup -
 Adam 🤗
Adam 🤗
@lunarflu1 -
 Clémentine Fourrier 🍊
Clémentine Fourrier 🍊
@clefourrier -
 Leandro von Werra
Leandro von Werra
@lvwerra -
 Jingfeng Yang
Jingfeng Yang
@JingfengY -
 Wauplin
Wauplin
@Wauplin -
 Luc Georges
Luc Georges
@LucSGeorges -
 Costa Huang
Costa Huang
@vwxyzjn -
 Madisen Taylor
Madisen Taylor
@madisenxtaylor -
 Marc Sun
Marc Sun
@_marcsun -
 Hugo Laurençon
Hugo Laurençon
@HugoLaurencon -
 William Steele
William Steele
@willjsteele -
 Yoach
Yoach
@yoachlacombe -
 Régis Gisré
Régis Gisré
@GisreRegis -
 PlatoJobs
PlatoJobs
@platojobs
Something went wrong.
Something went wrong.