
You might like
















🫡 new paper neurons can be a sparse and interpretable basis for circuit tracing, once you make the right decisions about which neurons and how you circuit trace! i'm excited for how this affects future progress on circuits + automating interp

Is your LM secretly an SAE? Most circuit-finding interpretability methods use learned features rather than raw activations, based on the belief that neurons do not cleanly decompose computation. In our new work, we show MLP neurons actually do support sparse, faithful circuits!


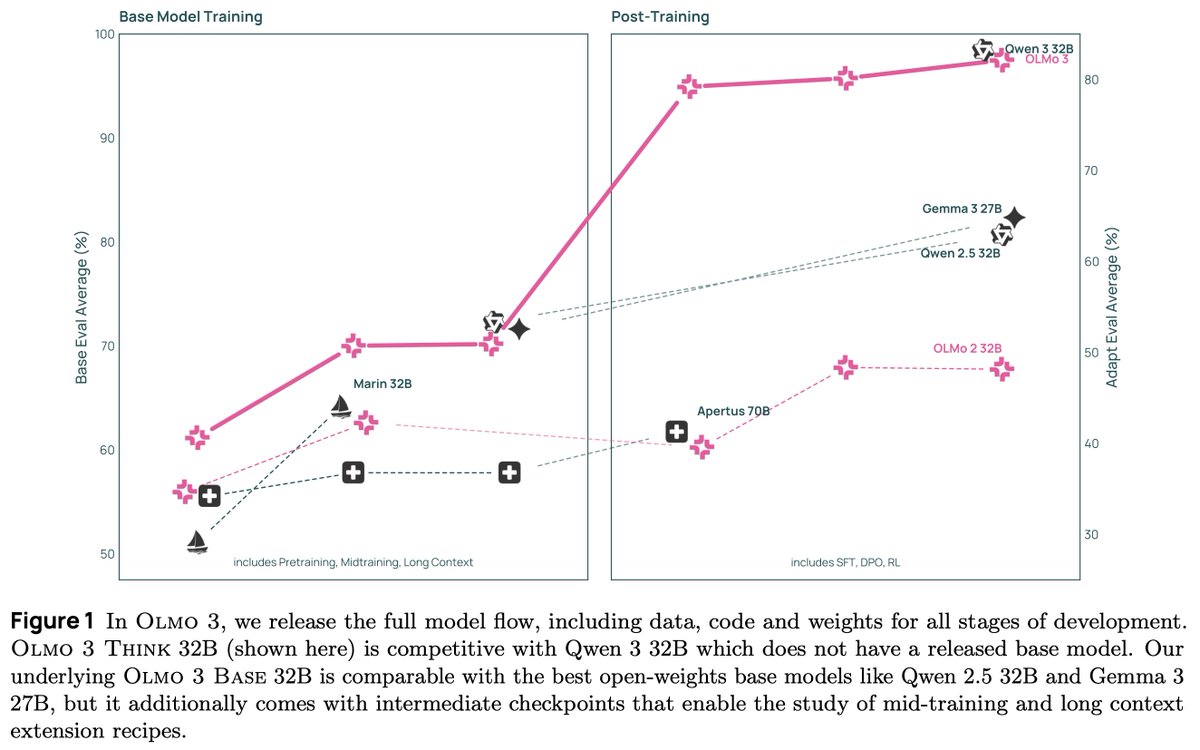
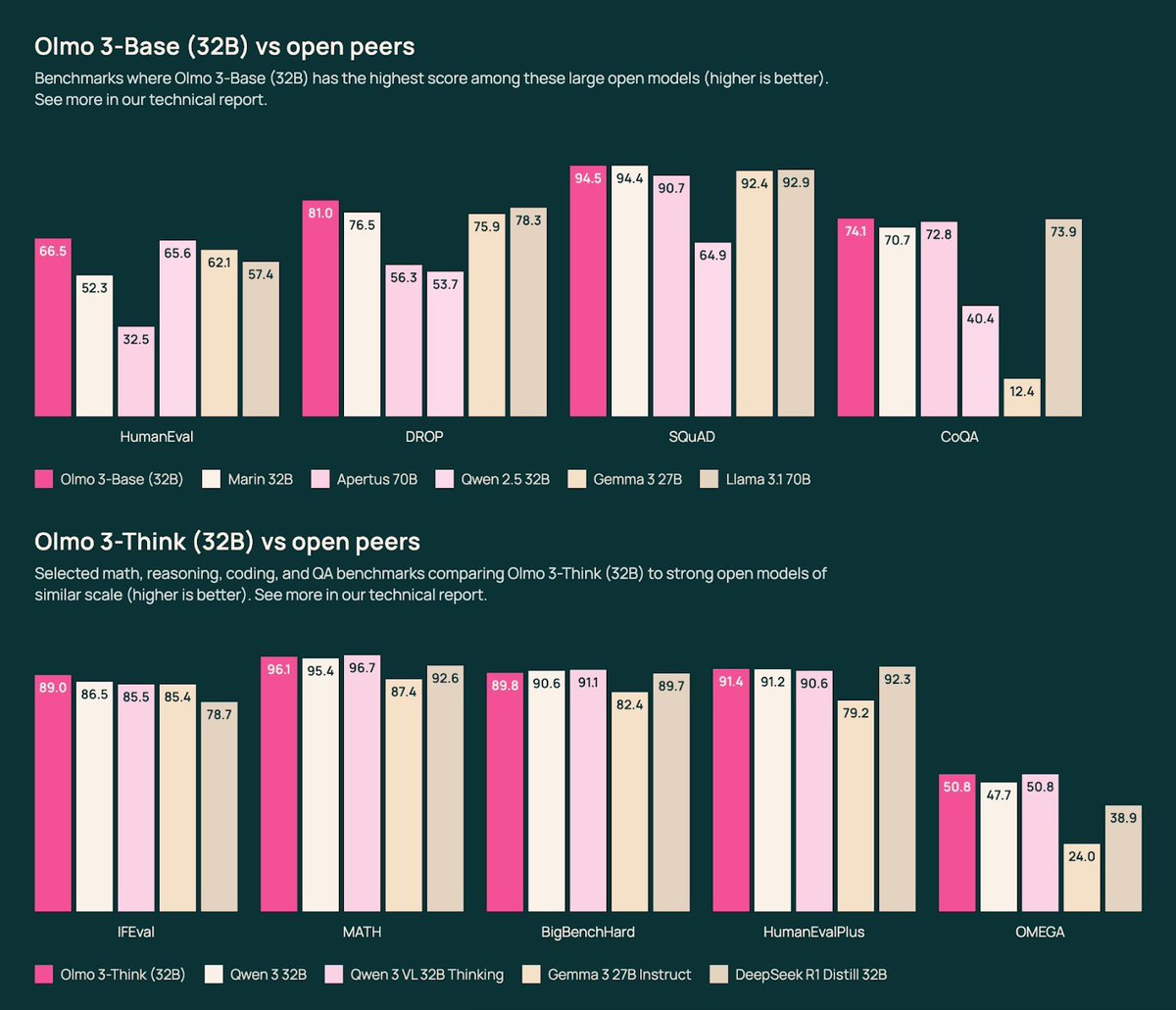
We present Olmo 3, our next family of fully open, leading language models. This family of 7B and 32B models represents: 1. The best 32B base model. 2. The best 7B Western thinking & instruct models. 3. The first 32B (or larger) fully open reasoning model. This is a big…


Video: youtu.be/Tgq7E4YcPKQ
youtube.com
YouTube
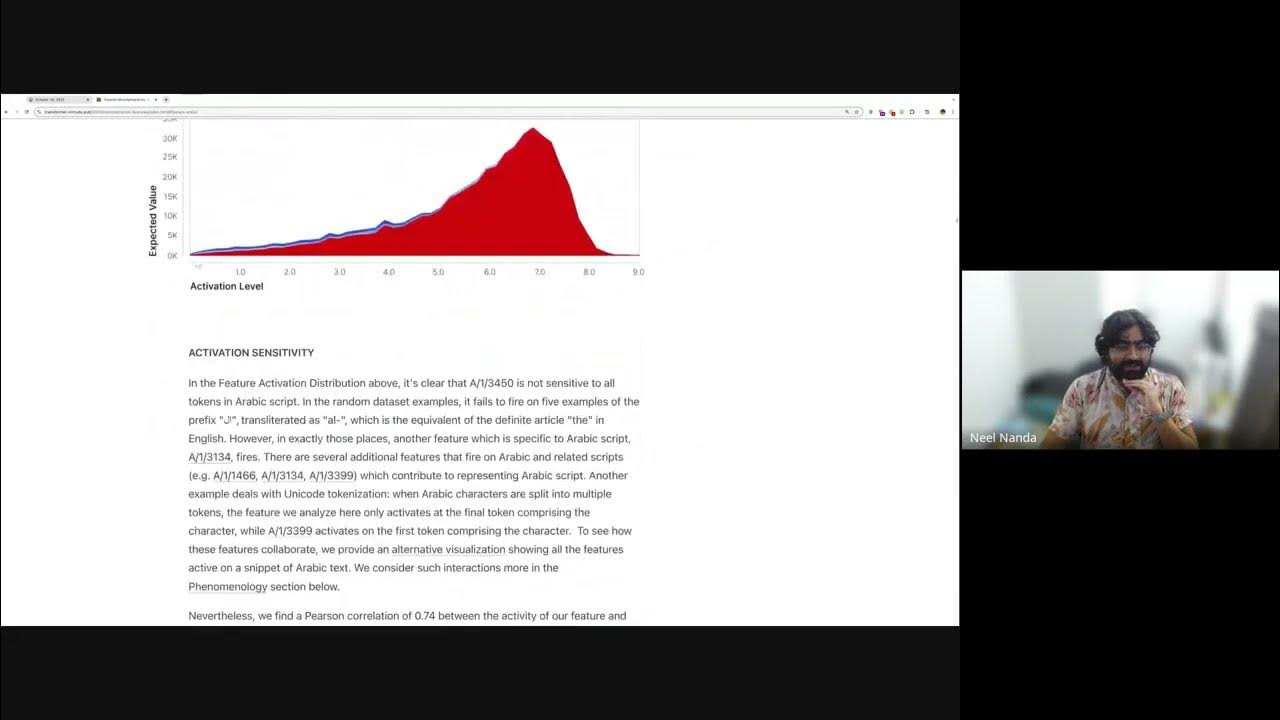
What Happened With Sparse Autoencoders?
New video: What happened with sparse autoencoders? SAEs were a big craze in mech interp, then suddenly weren't. In this talk, I give the story of SAEs as I experienced it, reflect on mistakes I made, how I think about them now and ways they're over AND under hyped and next steps



update: wrote a triton kernel for this - has correct tiled layout for scale factors - uses inline ptx for conversion - 4x faster than torch compiled version triton is absolutely amazing for writing memory bound kernels tbh


try 4.6 very soon
GLM 4.5 air running on 4x 3090 with 28 tokens/sec Pipeline parallelism over PCIe(no nvlink)

We need a transcoder trained for glm 4.5 air. One of the best local models. Would be super practical to have a skip transcoder and able to steer individual circuits.
GLM 4.5 Air running in ~60tok/sec on 4x 3090! 3090s are still great cards to buy if you want to run inference with 100b models, locally, for your own use x.com/monoidconcat/s…
Upgraded my setup to 1x 5090+ 4x 3090, going to test run GLM 4.5 air on this Considering to add another 5090 in a near future(whenever I can get one)


Due to popular demand, we've released more REAP models! @Zai_org ➡️GLM4.6-FP8 REAP@25% ➡️GLM4.6-FP8 REAP@30% ➡️GLM4.6-FP8 REAP@40% REAP is a one-shot pruning technique developed and open sourced by Cerebras. It compresses MoEs by up to 50% with minimal loss in coding ability.…
Upgraded my setup to 1x 5090+ 4x 3090, going to test run GLM 4.5 air on this Considering to add another 5090 in a near future(whenever I can get one)


My notes on nanochat, including links to the training data it uses simonwillison.net/2025/Oct/13/na…


Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…


nanochat day 1: sharing everything we have: - we've got an org on the hub to share resources and discuss learning - we've trained a tokenizer and published it on the hub. - integrated base training with trackio for free logging. curves! if you're also working on this. join the…

Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single,…

















































































































United States Trends
- 1. #IDontWantToOverreactBUT N/A
- 2. Thanksgiving 140K posts
- 3. Jimmy Cliff 20.7K posts
- 4. #GEAT_NEWS 1,190 posts
- 5. #WooSoxWishList N/A
- 6. $ENLV 14.7K posts
- 7. #MondayMotivation 12.4K posts
- 8. Victory Monday 3,585 posts
- 9. Good Monday 49.5K posts
- 10. DOGE 224K posts
- 11. Monad 164K posts
- 12. #NutramentHolidayPromotion N/A
- 13. $GEAT 1,149 posts
- 14. The Harder They Come 2,925 posts
- 15. Feast Week 1,619 posts
- 16. TOP CALL 4,670 posts
- 17. Bowen 16.3K posts
- 18. Many Rivers to Cross 2,571 posts
- 19. Soles 95.7K posts
- 20. $NVO 3,424 posts
You might like
-
 Noam Cohen
Noam Cohen
@noamwithveto -
 Bora
Bora
@boratheworld -
 Interweb, Inc.
Interweb, Inc.
@interweb_inc -
 Marko Polo
Marko Polo
@MarkoBaricevic_ -
 Simon Warta
Simon Warta
@simon_warta -
 bez
bez
@aleksb3z -
 Misang
Misang
@misangmadrid -
 Andy Nogueira
Andy Nogueira
@andynog -
 AARON
AARON
@aaronxkong -
 JeremyParish69
JeremyParish69
@JeremyParish69 -
 Friederike Ernst 🦉
Friederike Ernst 🦉
@tw_tter -
 Dan
Dan
@Daniel_Farinax -
 Jorge
Jorge
@jhernandezb_ -
 Maurits | Full-Stack web3 Dev
Maurits | Full-Stack web3 Dev
@MbBrainz -
 davidfeiock
davidfeiock
@davidfeiock
Something went wrong.
Something went wrong.