
내가 좋아할 만한 콘텐츠



We’re launching SWE-fficiency to eval whether LMs can speed up real GitHub repos on real workloads! ⏱️ 498 optimization tasks across 9 data-science, ML, and HPC repos — each with a real workload to speed up. Existing agents struggle to match expert level optimizations!

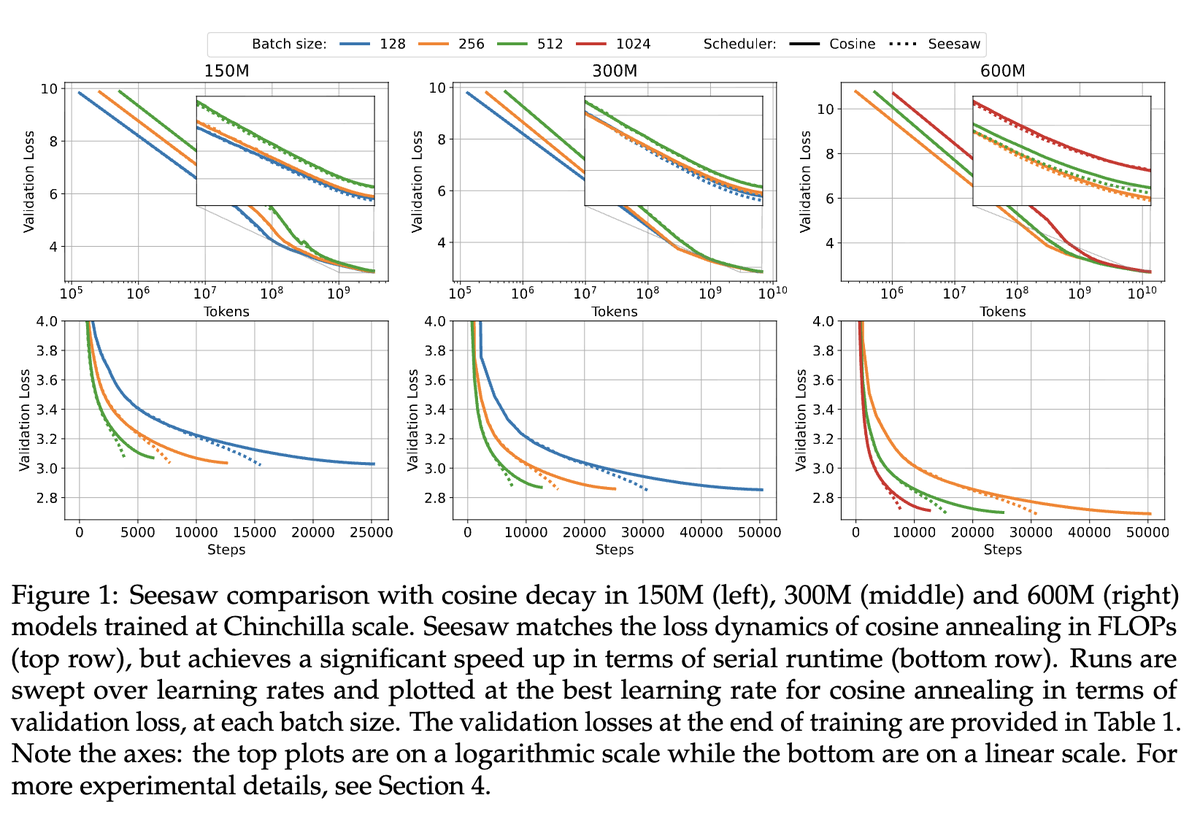
(1/9) Diagonal preconditioners such as Adam typically use empirical gradient information rather than true second-order curvature. Is this merely a computational compromise or can it be advantageous? Our work confirms the latter: Adam can outperform Gauss-Newton in certain cases.

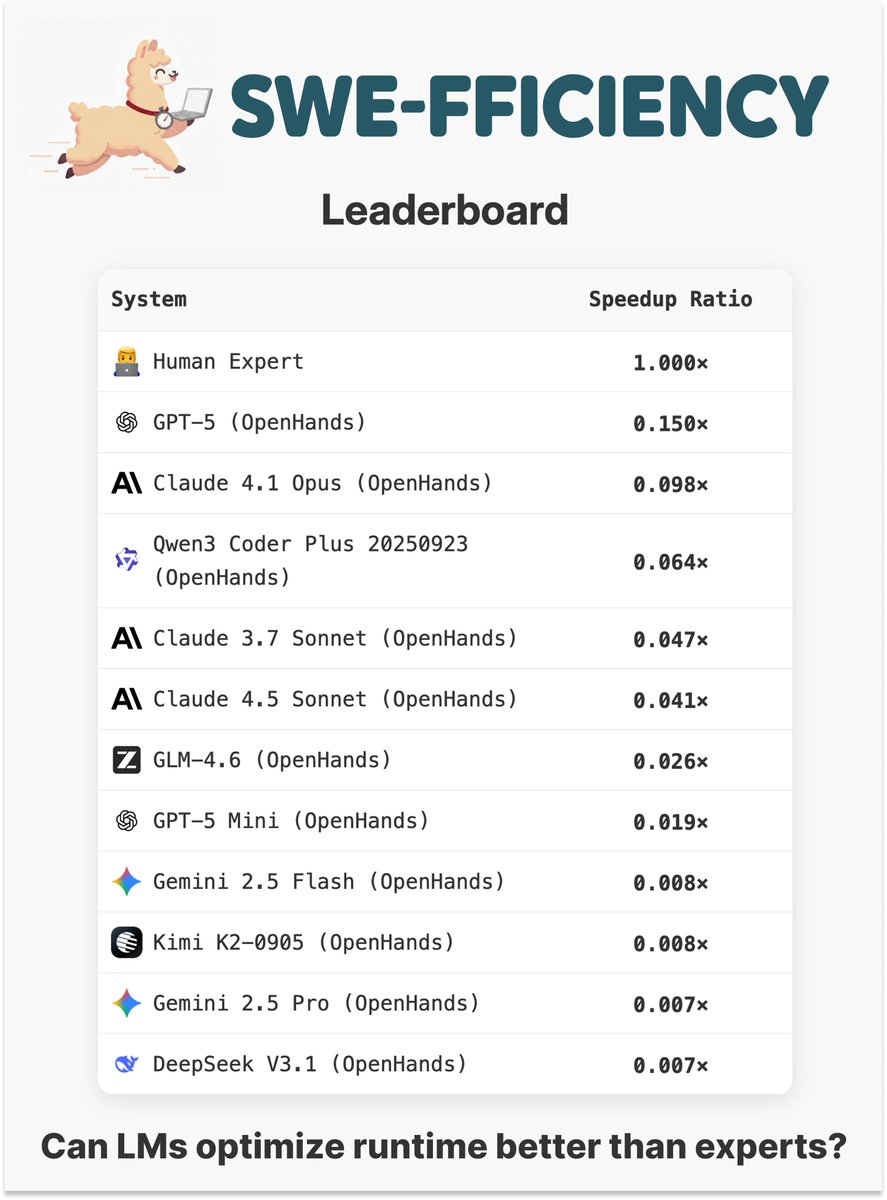
1/6 Introducing Seesaw: a principled batch size scheduling algo. Seesaw achieves theoretically optimal serial run time given a fixed compute budget and also matches the performance of cosine annealing at fixed batch size.

We found a new way to get language models to reason. 🤯 No RL, no training, no verifiers, no prompting. ❌ With better sampling, base models can achieve single-shot reasoning on par with (or better than!) GRPO while avoiding its characteristic loss in generation diversity.

LOTION is the balm
1/9 Introducing LOTION (Low-precision optimization via stochastic-noise smoothing), a principled alternative to Quantization-Aware Training (QAT) that explicitly smooths the quantized loss surface while preserving all global minima of the true quantized loss. Details below:

Happy to share this work on quantization, where taking inspiration from Nesterov smoothing, we directly smooth the quantization loss landscape, while preserving the global minima. It shows better quantized performance than the standard QAT methods. More details in this thread.
1/9 Introducing LOTION (Low-precision optimization via stochastic-noise smoothing), a principled alternative to Quantization-Aware Training (QAT) that explicitly smooths the quantized loss surface while preserving all global minima of the true quantized loss. Details below:
Low precision is critical for serving models, but how should we do optimization when quantization zeroes gradients almost everywhere? We introduce LOTION, a principled way to smooth the quantized loss while preserving global minima. See Sham’s🧵 for details, paper and blogpost!
1/9 Introducing LOTION (Low-precision optimization via stochastic-noise smoothing), a principled alternative to Quantization-Aware Training (QAT) that explicitly smooths the quantized loss surface while preserving all global minima of the true quantized loss. Details below:
1/8 Second Order Optimizers like SOAP and Muon have shown impressive performance on LLM optimization. But are we fully utilizing the potential of second order information? New work: we show that a full second order optimizer is much better than existing optimizers in terms of…

I respectfully disagree with Ed. Was Kepler's planetary analysis "real" mathematics or just astronomy? Are IMO problems "real" mathematics or just puzzles for high school students? Is photography "real" art or just tool use? The label "real" is a personal, aesthetic judgment,…

This is an unwise statement that can only make people confused about what LLMs can or cannot do. Let me tell you something: Math is NOT about solving this kind of ad hoc optimization problems. Yeah, by scraping available data and then clustering it, LLMs can sometimes solve some…

Interested in the latest work from the #KempnerInstitute? Check out papers and preprints from June's Research Roundup. kempnerinstitute.harvard.edu/kempner-commun… Abstracts and links below. 🧵 (1/21) #AI #neuroscience #NeuroAI
'Decomposing Elements of Problem Solving: What "Math" Does RL Teach?' Tian Qin, @corefpark, Mujin Kwun, @aaronwalsman, @EranMalach, @nikhil_anand91, @Hidenori8Tanaka , @elmelis doi.org/10.48550/arXiv… (15/21)

New in the #DeeperLearningBlog: Kempner researchers Nikhil Anand (@nikhil_anand91) and Chloe Su (@Huangyu58589918) discuss new work on how numerical precision can impact the accuracy and stability of #LLMs. kempnerinstitute.harvard.edu/research/deepe… #AI (1/2)
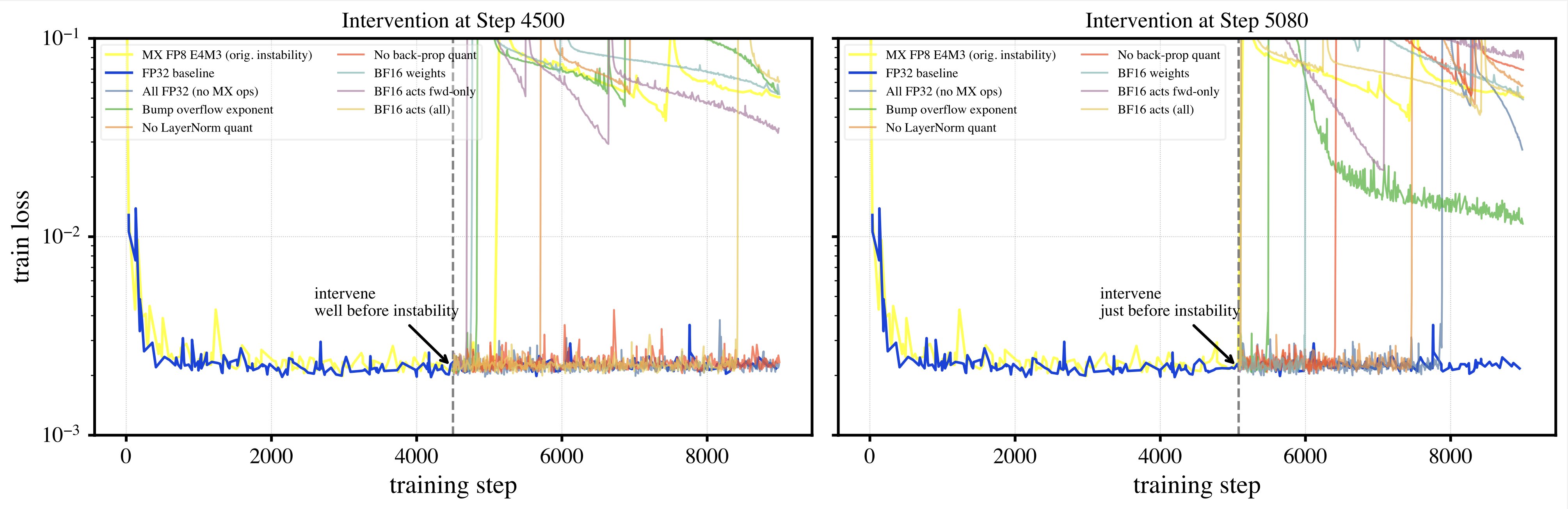
Excited to share this work on understanding low-precision instabilities in model training! See our thread below for more details. Paper: arxiv.org/abs/2506.20752 Blogpost: tinyurl.com/lowprecinstabi…

What precision should we use to train large AI models effectively? Our latest research probes the subtle nature of training instabilities under low precision formats like MXFP8 and ways to mitigate them. Thread 🧵👇


🚨 New preprint! TL;DR: Backtracking is not the "holy grail" for smarter LLMs. It’s praised for helping models “fix mistakes” and improve reasoning—but is it really the best use of test-time compute? 🤔

How does RL improve performance on math reasoning? Studying RL from pretrained models is hard, as behavior depends on choice of base model. 🚨 In our new work, we train models *from scratch* to study the effect of the data mix on the behavior of RL. arxiv.org/abs/2504.07912

At NeurIPS? Come discuss loss-to-loss prediction and scaling laws with us!
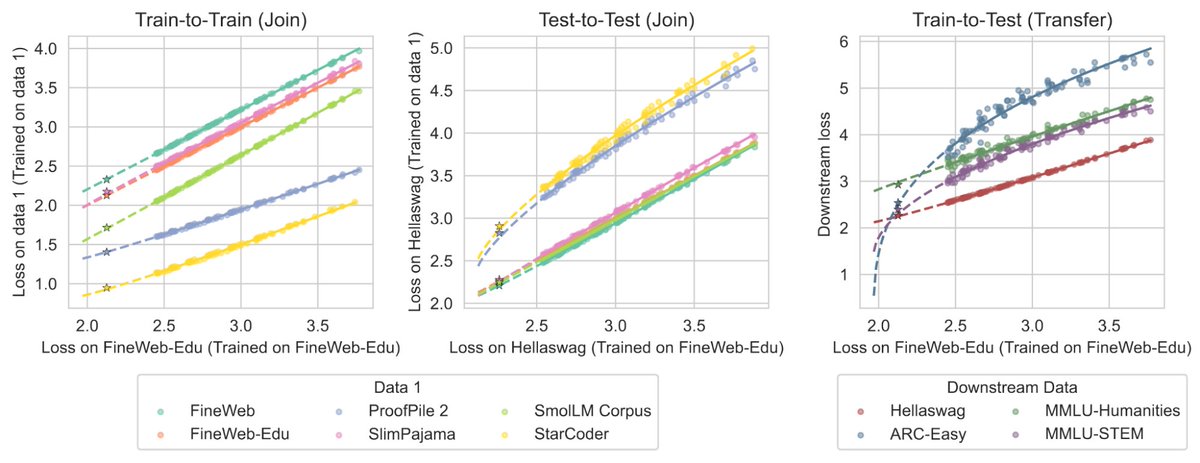
NEW in the #KempnerInstitute blog: A method to predict how #LLMs scale w/ compute across different datasets from @brandfonbrener, @nikhil_anand91, @vyasnikhil96, @eranmalach, & @ShamKakade6. Read it here: buff.ly/4iqPw9o
How do different data distributions interact with scaling laws? And how does training data affect test loss? We find simple shifted power law fits can relate performance across (sometimes very disparate) datasets and losses. See David's thread for more details!

How does test loss change as we change the training data? And how does this interact with scaling laws? We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.
MoEs increase parameter count but not FLOPs. Do they offer "free lunch", improving performance without paying in compute? Our answer: for memorization, MoEs give performance gains "for free", but have limited benefit for reasoning! Arxiv: arxiv.org/pdf/2410.19034 🦜🦜🦜

Really cool work led by Devin Kwok (McGill/Mila) on making sense of example difficulty. Addresses some key ?s: E.g, How consistent is measured difficulty across inits and for different architectures? Can we fingerprint models using a few key sensitive/hard examples?

[LG] Dataset Difficulty and the Role of Inductive Bias arxiv.org/abs/2401.01867 This paper investigates the role of dataset difficulty and inductive bias. By comparing the rankings of different scoring methods over multiple training runs and model architectures, it is found…
![fly51fly's tweet image. [LG] Dataset Difficulty and the Role of Inductive Bias
arxiv.org/abs/2401.01867
This paper investigates the role of dataset difficulty and inductive bias. By comparing the rankings of different scoring methods over multiple training runs and model architectures, it is found…](https://pbs.twimg.com/media/GDRWOAobgAALlSi.jpg)
![fly51fly's tweet image. [LG] Dataset Difficulty and the Role of Inductive Bias
arxiv.org/abs/2401.01867
This paper investigates the role of dataset difficulty and inductive bias. By comparing the rankings of different scoring methods over multiple training runs and model architectures, it is found…](https://pbs.twimg.com/media/GDRWOAoasAArYNy.jpg)
Happy to share our EMNLP paper w/ @jtan189 where we apply Variance of Gradients (VoG) – originally developed by @_cagarwal, @mrdanieldsouza, and @sarahookr – for selecting important data in language-based tasks. At EMNLP? Let's connect to discuss data quality and/or LLMs! #EMNLP

This work by @AmazonScience combines our VoG method with data pruning successfully. It fun because VoG we proposed a few years ago in a computer vision context -- fun to see it generalize to language-based tasks using pretrained models. successfully. amazon.science/publications/i…



















































































United States 트렌드
- 1. Delap 16.9K posts
- 2. Good Saturday 29.1K posts
- 3. Guiu 7,004 posts
- 4. Andrey Santos 4,474 posts
- 5. Burnley 36.2K posts
- 6. Chelsea 107K posts
- 7. #SaturdayVibes 4,089 posts
- 8. #Caturday 3,096 posts
- 9. Enzo 33.4K posts
- 10. Gittens 9,282 posts
- 11. #BURCHE 21.1K posts
- 12. Neto 23.7K posts
- 13. Joao Pedro 6,898 posts
- 14. Maresca 19.1K posts
- 15. #askdave N/A
- 16. #MeAndTheeSeriesEP2 622K posts
- 17. Tosin 8,650 posts
- 18. The View 101K posts
- 19. Chalobah 4,541 posts
- 20. Somali 87.8K posts


Something went wrong.
Something went wrong.