
You might like








Excited to share our work “Better Hessians Matter: Studying the Impact of Curvature Approximations in Influence Functions,” presented as a Spotlight at the NeurIPS 2025 Mechanistic Interpretability Workshop earlier this month :) ! 🧵👇 Paper: arxiv.org/abs/2509.23437

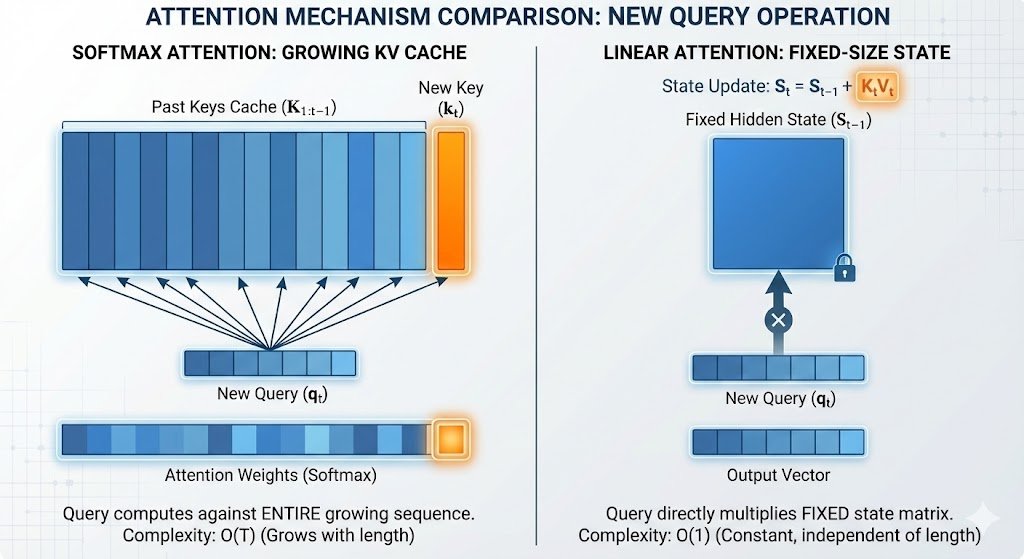
We (@lawrence_cjs, @yuyangzhao_ , @shanasaimoe) from the SANA team just posted a blog on the core of Linear Attention: how it achieves infinite context lengths with global awareness but constant memory usage! We explore state accumulation mechanics, the evolution from Softmax to…
The training/ Inference code and checkpoints are released. Welcome to try! github.com/NVlabs/Sana


Can we understand the chain-of-thought (CoT) of latent reasoning LLMs using current mech interp techniques? It turns out we can uncover interpretable structure, at least on simple math problems! In a short study we show that latent vectors represent eg. intermediate calculations


If anyone asks for the best AI paper of the week, it’s definitely this elegant work: arxiv.org/pdf/2512.16922

New work on evaluating the quality of chain-of-thought monitorability. Chain-of-thought monitorability is a very encouraging opportunity for safety and alignment, making it easy to see what models are thinking:

To preserve chain-of-thought (CoT) monitorability, we must be able to measure it. We built a framework + evaluation suite to measure CoT monitorability — 13 evaluations across 24 environments — so that we can actually tell when models verbalize targeted aspects of their…

my ultimate career goal is to meet tri dao for a coffee in saigon

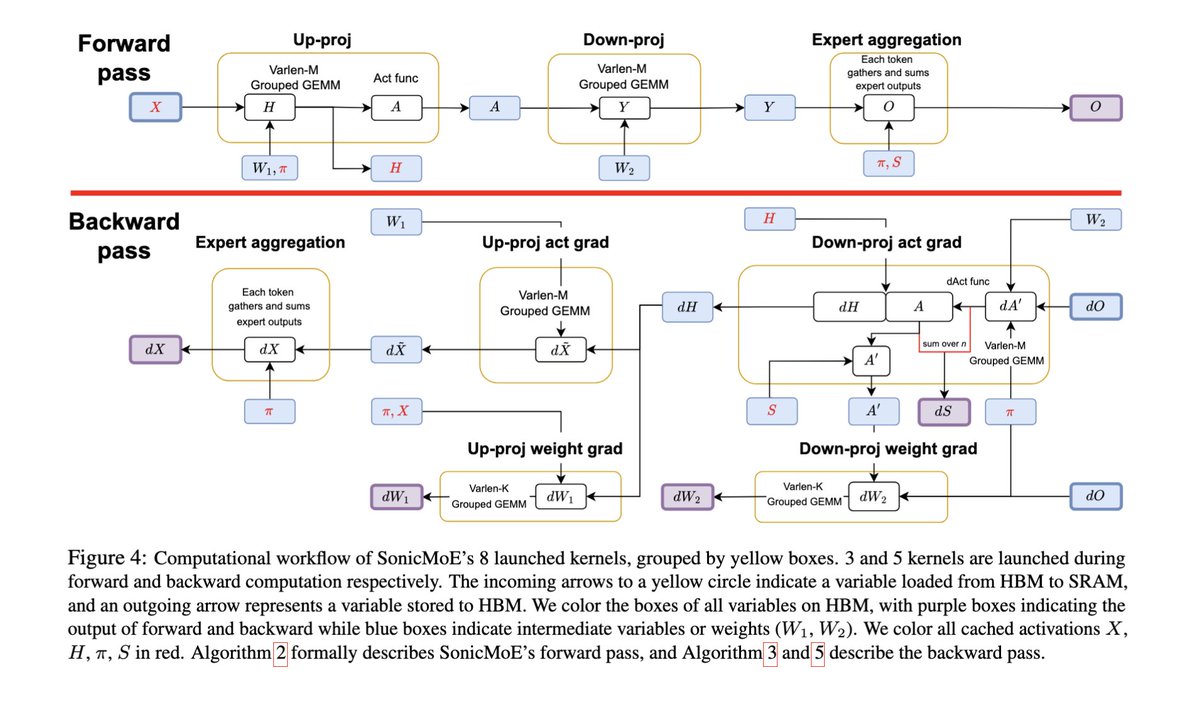
The author of FlashAttention, Tri Dao, just dropped a new paper called SonicMoE With 1.86x higher MoE kernel throughput and 45% lower activation memory per layer on H100s, by introduceing tile-aware routing that cuts padding waste for sparse MoEs Trending on alphaXiv 📈

cool paper studying the differences between SFT and DPO. arxiv.org/abs/2407.10490

Interested in how @Kimi_Moonshot 's kimi linear attention (KDA) "improves" linear attention, I break down the math to show how it evolves all the way from the most basic version. Linear attention can be seen in two perspectives: - On the one hand the linear "fast memory"…




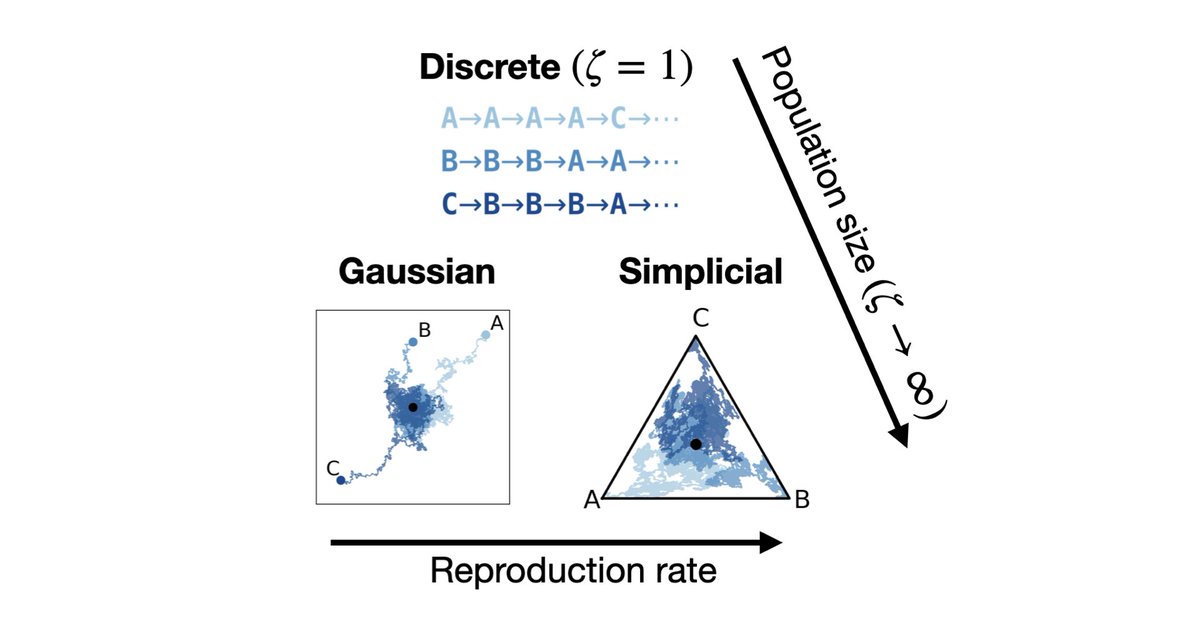
If you want to do diffusion on discrete data, you have three choices: discrete, Gaussian, or simplicial. How are they related? Which should you use? We theoretically unify all three and train one model to do them all! @AlinaChandra @yucenlily @alex4ali @andrewgwils 1/7

Weekend project: 1. Crawl all research papers from top venues. 2. Extract limitations sections. 3. Dump it into notebookLM or Gemini. 4. Start asking questions to find unsolved problems. Enjoy! @cneuralnetwork

TurboDiffusion: 100–205× faster video generation on a single RTX 5090 🚀 Only takes 1.8s to generate a high-quality 5-second video. The key to both high speed and high quality? 😍SageAttention + Sparse-Linear Attention (SLA) + rCM Github: github.com/thu-ml/TurboDi… Technical…

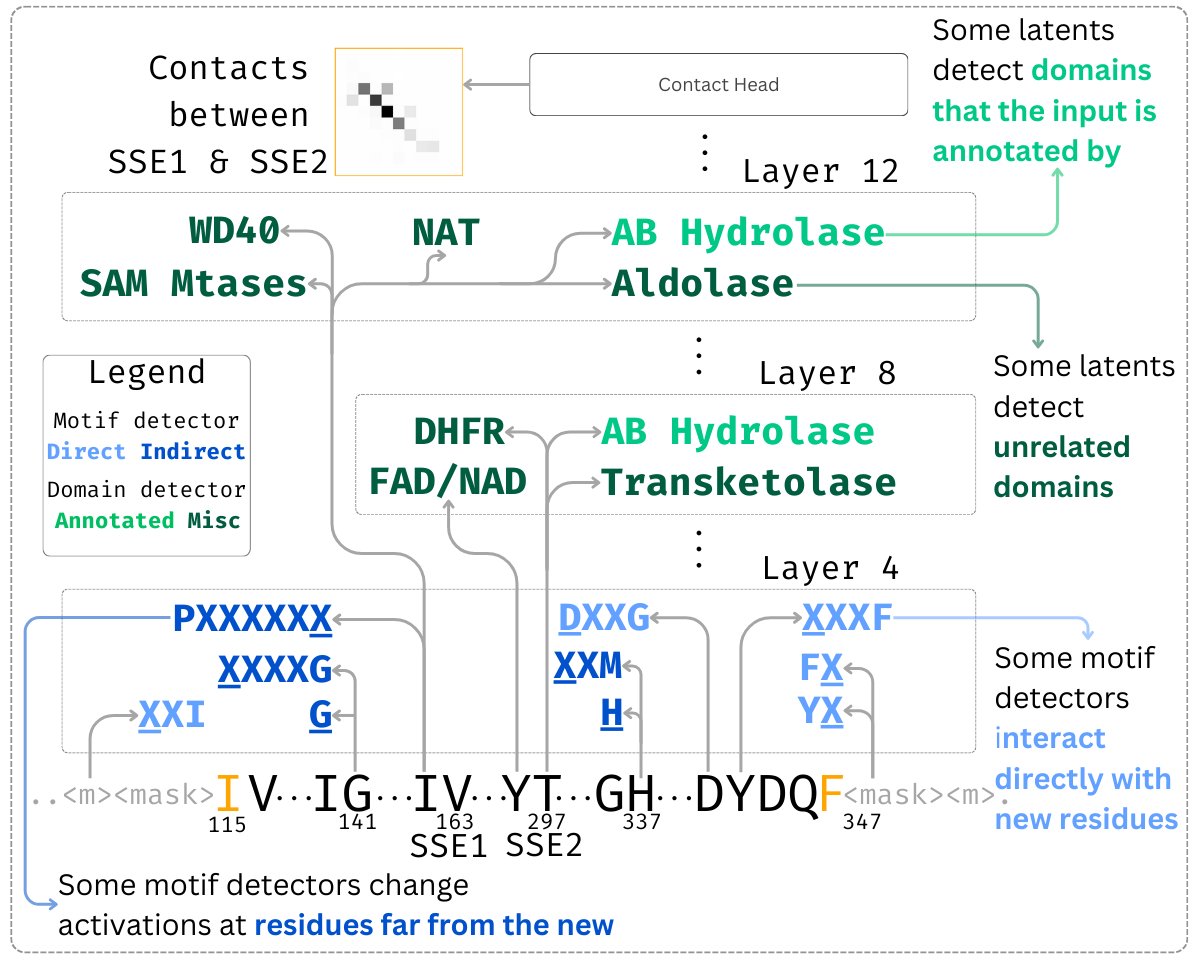
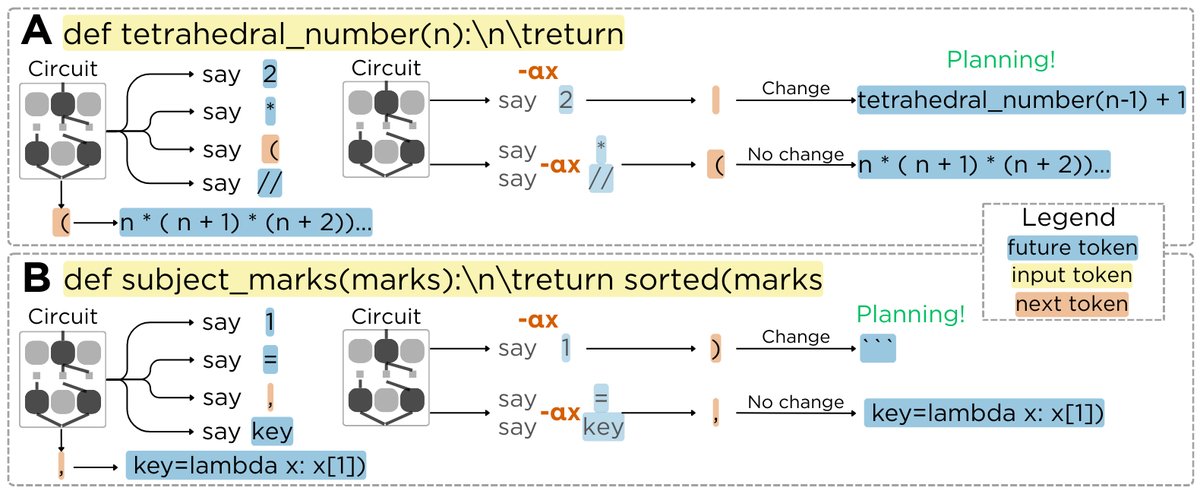
I’ll be at NeurIPS Dec 3–7, presenting two Mech Interp workshop posters on (1) circuit-level analysis of protein language models and (2) detecting planning behavior in LLMs. If you’re into mechanistic interpretability for science / cognition, I’d love to chat / grab coffee!





































































United States Trends
- 1. Browns 26,8 B posts
- 2. #HereWeGo 2.761 posts
- 3. Brigitte Bardot 226 B posts
- 4. Go Birds 6.123 posts
- 5. Ja'Marr Chase 1.714 posts
- 6. #DawgPound 2.409 posts
- 7. #AskFFT N/A
- 8. Tonges 2.564 posts
- 9. Austin Hooper N/A
- 10. Chuck Clark N/A
- 11. FINALLY DID IT 570 B posts
- 12. #sundayvibes 6.131 posts
- 13. Jaycee N/A
- 14. Myles Garrett 2.023 posts
- 15. X-Men 41,7 B posts
- 16. Hammonton 1.791 posts
- 17. Jeffery Simmons N/A
- 18. Sunday of 2025 18,7 B posts
- 19. Nick Shirley 332 B posts
- 20. Saba 9.432 posts








Something went wrong.
Something went wrong.