
你可能会喜欢















👀

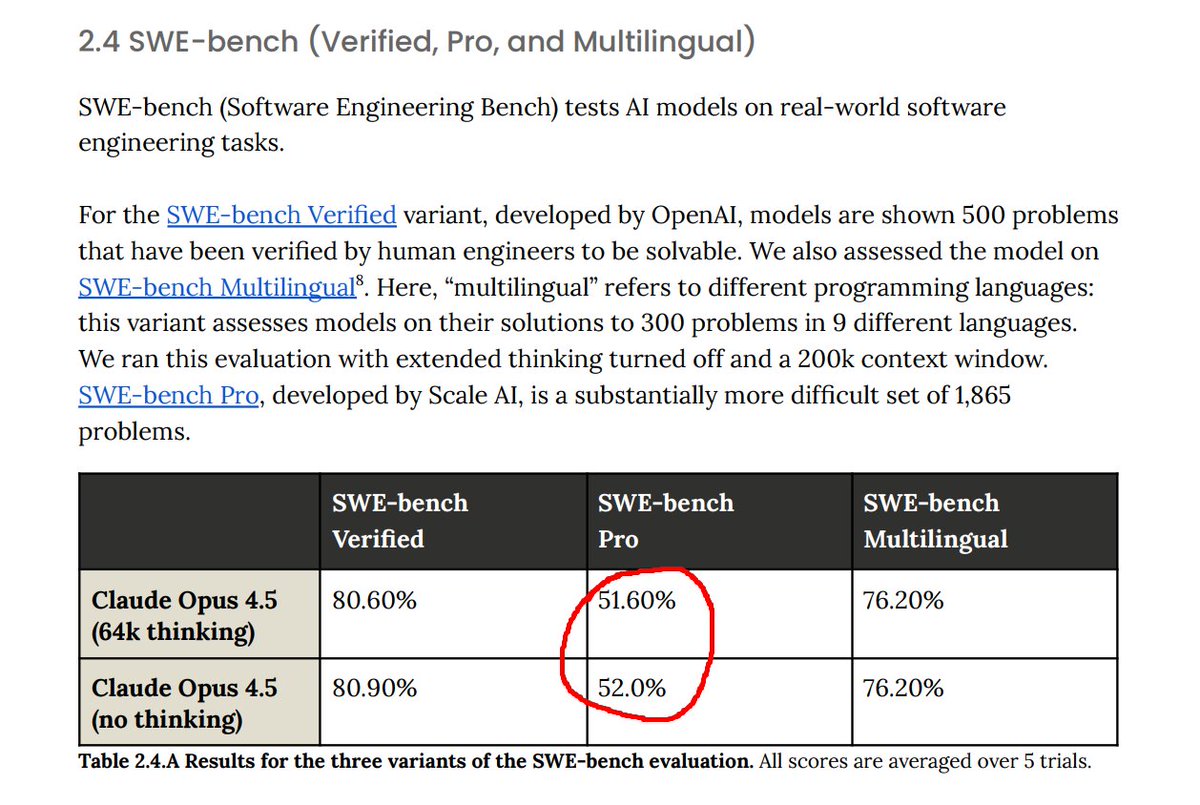
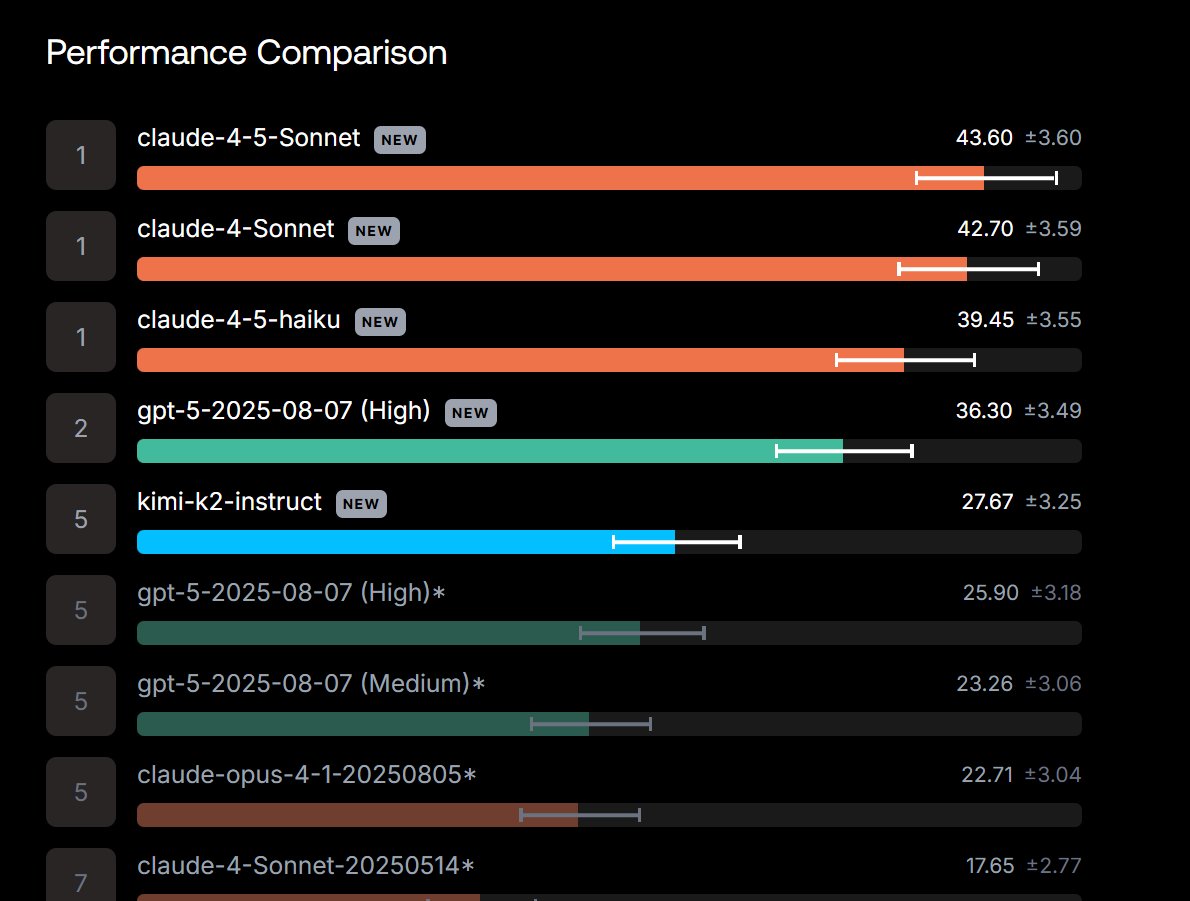
real metrics banger is hidden in the system card. Yes, you can overfit on Django and nail SWE-bench Verified. But there's this recent SWE-bench Pro from @scale_AI , and opus gets 52%. The next best, sonet 4.5, is only 43.6, and non-anthropic model, GPT-5, is 36%. This is HUGE…

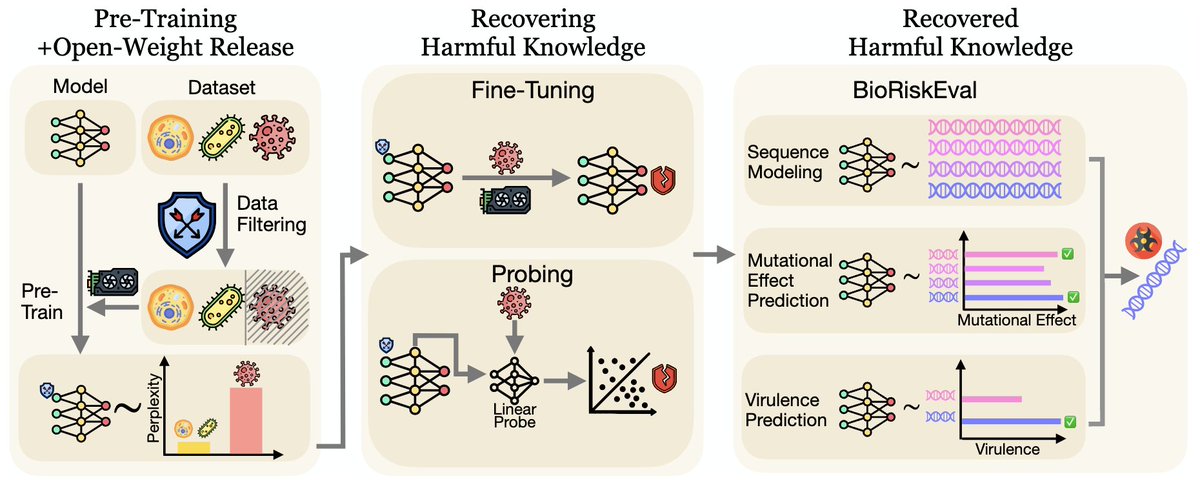
Our new research from @Scale_AI reveals that harmful biological knowledge can persist inside bio-foundation models even after filtering. We introduce BioRiskEval, the first comprehensive framework built to assess dual-use risk in these models using a realistic adversarial threat…

1/ New Chain of Thought podcast episode from @Scale_AI, where we dive into SWE-Bench Pro, a benchmark designed to rigorously evaluate LLM coding agents on professional software engineering tasks.

🚀New @scale_AI paper: 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵𝗥𝘂𝗯𝗿𝗶𝗰𝘀, a benchmark for evaluating Deep Research (DR) agents. Even top agents like Gemini & OpenAI DR achieve <𝟲𝟴% 𝗿𝘂𝗯𝗿𝗶𝗰 𝗰𝗼𝗺𝗽𝗹𝗶𝗮𝗻𝗰𝗲. We built 𝟮.𝟱𝗞+ expert rubrics with 𝟮.𝟴𝗞+ hrs of human labor to measure why.

Today, we honor the courage, dedication, and sacrifice of all who have served. Thank you to our veterans. 🇺🇸






























































































































United States 趋势
- 1. Arch Manning 2,760 posts
- 2. Texas A&M 10.3K posts
- 3. #SmackDown 14.3K posts
- 4. #BedBathandBeyondisBack 1,410 posts
- 5. Sark 2,450 posts
- 6. Bears 127K posts
- 7. Aggies 5,243 posts
- 8. Eagles 141K posts
- 9. #OPLive 1,696 posts
- 10. #HookEm 4,210 posts
- 11. #iufb 2,401 posts
- 12. Marcel Reed 1,703 posts
- 13. Brunson 5,334 posts
- 14. Ben Johnson 27.3K posts
- 15. Wingo 1,763 posts
- 16. Lindor 1,896 posts
- 17. Purdue 5,491 posts
- 18. Bucks 18.7K posts
- 19. Longhorns 3,526 posts
- 20. Wisner N/A
你可能会喜欢
-
 Alexandr Wang
Alexandr Wang
@alexandr_wang -
 Hugging Face
Hugging Face
@huggingface -
 Geoffrey Hinton
Geoffrey Hinton
@geoffreyhinton -
 Andrej Karpathy
Andrej Karpathy
@karpathy -
 LlamaIndex 🦙
LlamaIndex 🦙
@llama_index -
 Jan Leike
Jan Leike
@janleike -
 Anthropic
Anthropic
@AnthropicAI -
 AI at Meta
AI at Meta
@AIatMeta -
 clem 🤗
clem 🤗
@ClementDelangue -
 LangChain
LangChain
@LangChainAI -
 a16z
a16z
@a16z -
 Chroma
Chroma
@trychroma -
 Runway
Runway
@runwayml -
 Greg Brockman
Greg Brockman
@gdb -
 Ilya Sutskever
Ilya Sutskever
@ilyasut
Something went wrong.
Something went wrong.