
You might like















My student @AngelikiGiannou is on the job market and she's the one that wrote the OG Looped Transformer paper. I strongly encourage you to read it, it's a tour de force! While I won't claim it influenced work on test-time compute, it 100% anticipated directions the community is…
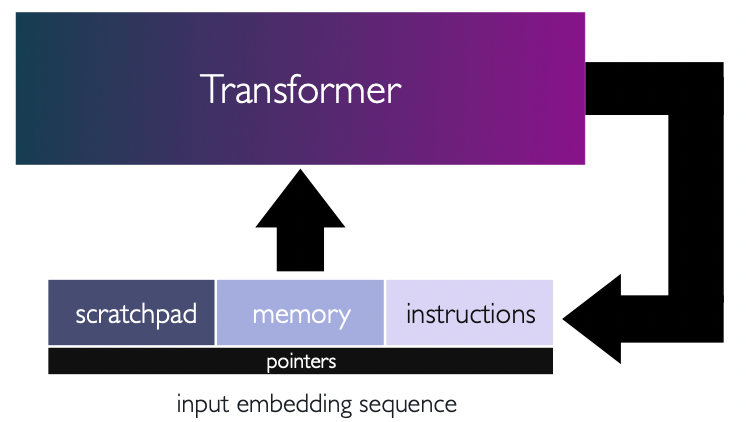
Can transformers follow instructions? We explore this in: "Looped Transformers as Programmable Computers" arxiv.org/abs/2301.13196 led by Angeliki (@AngelikiGiannou) and Shashank (@shashank_r12) in collaboartion with the @Kangwook_Lee and @jasondeanlee Here is a 🧵

The MixAttention blog post from Databricks/Mosaic is great: databricks.com/blog/mixattent…


@jefrankle frantically asks not to whisper the words that won him this very well deserved award !!! But here’s one for you - “Lottery Tickets” !!!


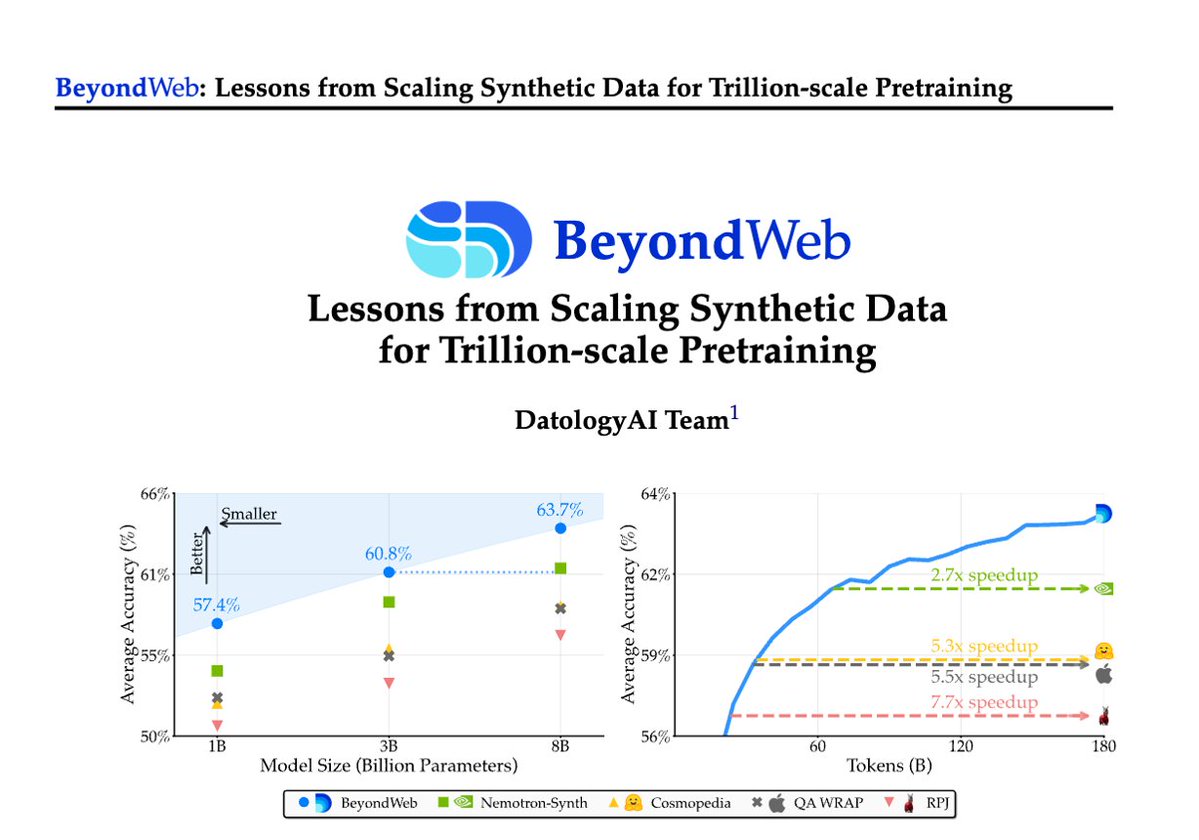
1/Pretraining is hitting a data wall; scaling raw web data alone leads to diminishing returns. Today @datologyai shares BeyondWeb, our synthetic data approach & all the learnings from scaling it to trillions of tokens🧑🏼🍳 - 3B LLMs beat 8B models🚀 - Pareto frontier for performance

🚀 Introducing NSA: A Hardware-Aligned and Natively Trainable Sparse Attention mechanism for ultra-fast long-context training & inference! Core components of NSA: • Dynamic hierarchical sparse strategy • Coarse-grained token compression • Fine-grained token selection 💡 With…





We are announcing Open Thoughts, our large-scale open-source effort to curate the best open reasoning datasets! DeepSeek-R1 is amazing but we still don't have access to high-quality open reasoning datasets. These datasets are crucial if you want to build your reasoning models!…

Introducing Bespoke-Stratos-32B, our reasoning model distilled from DeepSeek-R1 using Berkeley NovaSky’s Sky-T1 recipe. The model outperforms Sky-T1 and o1-preview in reasoning (Math and Code) benchmarks and almost reaches the performance of DeepSeek-R1-Distill-Qwen-32B while…

We are happy to announce Curator, an open-source library designed to streamline synthetic data generation! High-quality synthetic data generation is essential in training and evaluating LLMs/agents/RAG pipelines these days, but tooling around this is still entirely lacking! So…
Nice to see my previous work that I led at Google DeepMind covered by VentureBeat (in the light of a new work from Meta). Context: We had introduced the novel idea of Generative Retrieval for recommender systems to the world in our Neurips 2023 paper called TIGER (Transformer…

It's finally here! Excited to share the project I led with KRAFTON and NVIDIA. The future of gaming is here 🙌

Transform solo gameplay into a seamless team experience with PUBG Ally. KRAFTON & NVIDIA have teamed up to create the world’s first Co-Playable Character (CPC), built with NVIDIA ACE → nvda.ws/3W4kzhJ

Watch the full conversation: youtu.be/2tlWPgmiX2s?si…

youtube.com
YouTube
Mixed Attention & LLM Context | Data Brew | Episode 35
Databricks research scientist @shashank_r12 s shares approaches in LLMs: - How RAG enhances accuracy - Evolution of attention mechanisms - Practical applications & trade-offs of Mamba architectures

Soo disappointed that it's just a "department" and not a School, College or an Institute.. gotta get ahead of the curve, @IITKgp!!

I have three Ph.D. student openings in my research group at @RutgersCS starting in Fall 2025. If you are interested in working with me on efficient algorithms and systems for LLMs, foundation models, and AI4Science, please apply at: grad.rutgers.edu/academics/prog… The deadline is…

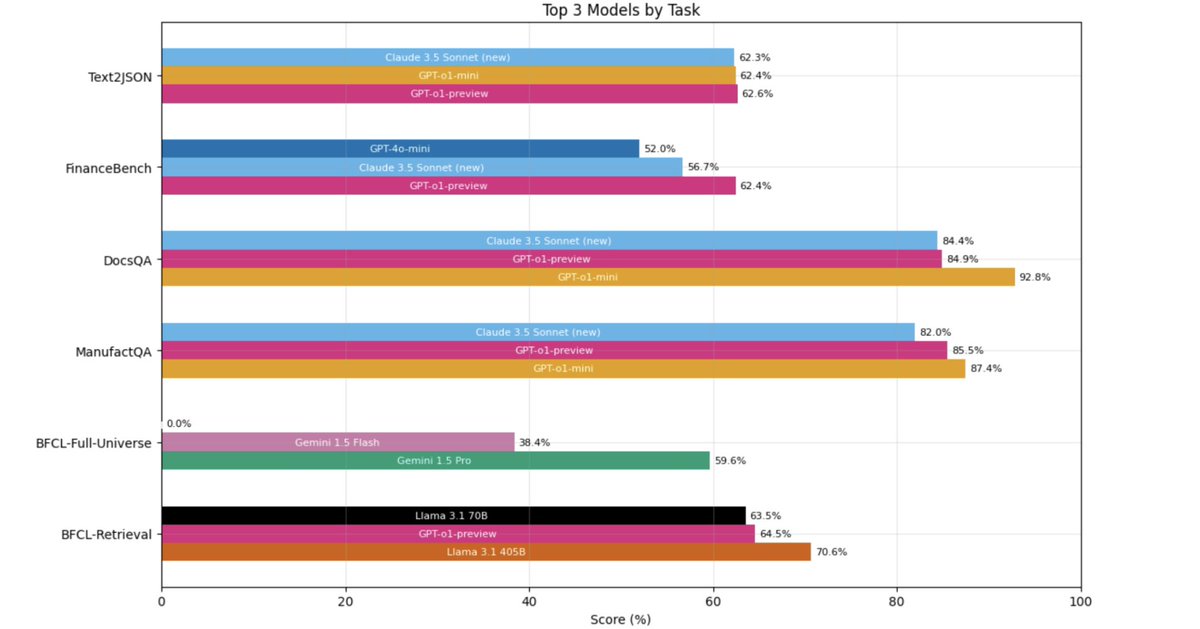
🧵 Super proud to finally share this work I led last quarter - the @Databricks Domain Intelligence Benchmark Suite (DIBS)! TL;DR: Academic benchmarks ≠ real performance and domain intelligence > general capabilities for enterprise tasks. 1/3

i'm somewhat confident that both the following properties will hold of language models in 2027: 1. tokenization will be gone, replaced with byte-level ingestion 2. all tokens that don't need to be read or written by a human will be continuous vectors luckily two interesting…


At NeurIPS early? Like making GPUs go brrr? Join me at a luncheon tomorrow on LLM Scaling x Efficiency, 5 mins from the conference center... Note, folks need to have directly relevant work of not in the field. DM me for more info or for reccs! Per the usual, I'll be doing 3…

I'll be at NeurIPS and would love to chat about anything AI. Also, visit the Databricks booth to checkout out some of the work we've been doing! databricks.com/blog/databrick…


Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques including online preference optimization, this model improves core performance at…


🤔 How can we achieve GPT-3 175B-level performance with only 1.3B parameters? 🌟 New from #NVIDIAResearch: HYMBA (HYbrid Multi-head Bi-Attention) combines MLP and attention mechanisms to dramatically boost small language model capabilities. HYMBA could revolutionize NLP…
























































































United States Trends
- 1. Blue Origin 6,153 posts
- 2. Megyn Kelly 28.1K posts
- 3. Vine 31.8K posts
- 4. New Glenn 7,300 posts
- 5. Senator Fetterman 17.2K posts
- 6. CarPlay 4,228 posts
- 7. #NXXT_JPMorgan N/A
- 8. World Cup 96K posts
- 9. Portugal 57.9K posts
- 10. Padres 29.1K posts
- 11. Brainiac 3,388 posts
- 12. Matt Gaetz 12.3K posts
- 13. Black Mirror 5,086 posts
- 14. GeForce Season N/A
- 15. Cynthia 110K posts
- 16. Eric Swalwell 23.1K posts
- 17. Osimhen 97.4K posts
- 18. Katie Couric 9,209 posts
- 19. #WorldKindnessDay 16.6K posts
- 20. V-fib N/A
You might like
-
 Kartik Sreenivasan
Kartik Sreenivasan
@KartikSreeni -
 Dimitris Papailiopoulos
Dimitris Papailiopoulos
@DimitrisPapail -
 Kangwook Lee
Kangwook Lee
@Kangwook_Lee -
 Konstantin Mishchenko
Konstantin Mishchenko
@konstmish -
 Francesco Orabona
Francesco Orabona
@bremen79 -
 Denny Zhou
Denny Zhou
@denny_zhou -
 Rob Nowak
Rob Nowak
@rdnowak -
 Harit Vishwakarma
Harit Vishwakarma
@harit_v -
 Hongyi Wang
Hongyi Wang
@HongyiWang10 -
 Becca Willett
Becca Willett
@WillettBecca -
 Dimitri Bertsekas
Dimitri Bertsekas
@DBertsekas -
 Aryan Mokhtari
Aryan Mokhtari
@AryanMokhtari -
 Kwang-Sung (Kwang) Jun
Kwang-Sung (Kwang) Jun
@kwangsungjun -
 Arya Mazumdar
Arya Mazumdar
@MountainOfMoon -
 Dipanjan Das
Dipanjan Das
@dipanjand
Something went wrong.
Something went wrong.