
Sigrid Jin | Jin Hyung Park 🪄 👧
@sigridjin_eth
✯ @thisissigrid ★ ☄ CS @UBC ☄ ★ Ultrathink Engineer @sionic_ai 🐟 digital nomad 💻
Może Ci się spodobać















Read this tweet every day

What many people perceive as a focus problem is often a thoroughness problem. One route to improving focus is to *direct your efforts to thoroughness without the expectation of focus arriving first*. Put simply, thoroughness improves focus, no matter how slow the process may be.

You Don't Need Pre-built Graphs for RAG: Retrieval Augmented Generation with Adaptive Reasoning Structures Dynamically extracts reasoning structures at inference time without requiring pre-built graphs, achieving superior performance and efficiency. 📝arxiv.org/abs/2508.06105

It was 3.5 Billion Dollars 💀💀
Andrew Tulloch, "the PyTorch King" is back at Meta He at least got a 2 Billion Dollar bag


This a great experiment! It's not quite a RL scaling law, in the sense of what I've collected from a few frontier labs. Lots of things are similar, but their methods for establishing these relationships seems a bit different. First, they definitely use a set of base models sort…

🧵 As AI labs race to scale RL, one question matters: when should you stop pre-training and start RL? We trained 5 Qwen models (0.6B→14B) with RL on GSM8K and found something wild: Small models see EMERGENCE-LIKE jumps. Large models see diminishing returns. The scaling law?…


Codex is so good, and is going to get so amazing. I am having a hard time imagining what creating software at the end of 2026 is going to look like.

The fast.ai course is how I got started in AI. Few years later, in a full circle moment, I got the opportunity to contribute & help teach a few lectures of the course too. I still think it's one of the best resources for learning deep learning. Highly recommend!

course.fast.ai, combined with learning help from an LLM, is more accessible than ever. Great way to learn how AI and deep learning really work at the foundations.


with each leap of AI, humanity takes a small step backward
Interviewed an engineer. I’m 99% sure he was using Cluely. He’d pause for 3 seconds, stare into the void before every answer, then drop a perfectly structured 5-paragraph essay, with zero soul. I miss interviewing humans.

RL is probably one of the only things that can be easily published ...

Lot of insights in @YejinChoinka's talk on RL training. Rip for next token prediction training (NTP) and welcome to Reinforcement Learning Pretraining (RLP). #COLM2025 No place to even stand in the room.


In a technology race, the company that innovates fastest wins. All you need are a billion AI chips, a terawatt of power and 100M robots.

I have to admit, Grok Imagine has evolved a lot — it delivers excellent results, especially in anime 🔥

The oceans are increasingly gasping for breath. Increasingly, low-oxygen events in the world’s oceans coincide with heatwaves. The far-reaching implications for society include a decline of fish biomass, especially in productive ocean regions. climatechangepost.com/news/the-ocean…

VL is sometimes a bit complex and I really advise you to play it with a reference to this cookbook!

Introducing Qwen3-VL Cookbooks! 🧑🍳 A curated collection of notebooks showcasing the power of Qwen3-VL—via both local deployment and API—across diverse multimodal use cases: ✅ Thinking with Images ✅ Computer-Use Agent ✅ Multimodal Coding ✅ Omni Recognition ✅ Advanced…
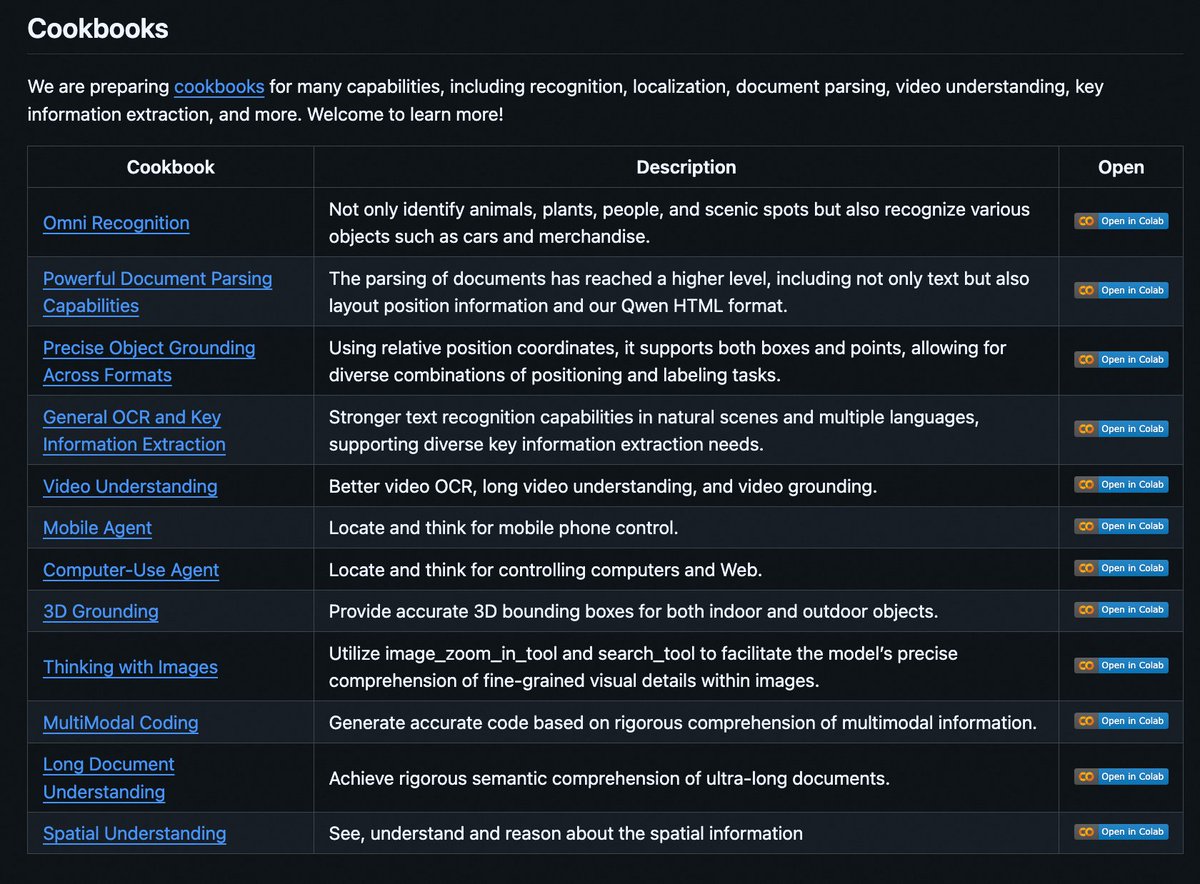

See u there!

After weeks of learning about systems at @scaleml, we’re shifting gears to video foundation models. Thrilled to have @cloneofsimo sharing how to train them from scratch next Tuesday — no better person to learn from 🔥
















































































































United States Trendy
- 1. Columbus 180K posts
- 2. President Trump 1.16M posts
- 3. Middle East 284K posts
- 4. Brian Callahan 11.5K posts
- 5. #IndigenousPeoplesDay 13.8K posts
- 6. Azzi 8,433 posts
- 7. Thanksgiving 56.7K posts
- 8. Titans 37.9K posts
- 9. Vrabel 6,817 posts
- 10. Cape Verde 20.8K posts
- 11. Macron 224K posts
- 12. #UFC323 3,027 posts
- 13. HAZBINTOOZ 6,693 posts
- 14. Marc 51.5K posts
- 15. Sabres 3,862 posts
- 16. #Isles 1,676 posts
- 17. Native Americans 14.4K posts
- 18. Seth 51.5K posts
- 19. Giannis 9,597 posts
- 20. Cejudo 1,011 posts
Może Ci się spodobać
-
 Ben Ja Min | nonce Classic
Ben Ja Min | nonce Classic
@bambben -
 Tariz | Rádius ✨
Tariz | Rádius ✨
@Hyunxukee -
 Ahri | Ⓜ️Ⓜ️T
Ahri | Ⓜ️Ⓜ️T
@heysoahri -
 Moneystack 🟧 .ip | DeSpread
Moneystack 🟧 .ip | DeSpread
@MoneyStack9 -
 Chaerin Kim
Chaerin Kim
@decentra1ized_ -
 zzoha.eth
zzoha.eth
@gohameye -
 Dev.Chooble
Dev.Chooble
@dev_chooble -
 상혁 Jaden Park
상혁 Jaden Park
@fkemgod -
 SB
SB
@subinium -
 decipher
decipher
@DecipherGlobal -
 Boosik | Orca🌊 Ⓜ️Ⓜ️T
Boosik | Orca🌊 Ⓜ️Ⓜ️T
@0xboosik -
 JonghyunChun
JonghyunChun
@JonghyunChun -
 MORBID-19
MORBID-19
@JuhyukB -
 web3vibe
web3vibe
@web3vibe -
 Do Dive
Do Dive
@Crypnovice88
Something went wrong.
Something went wrong.