
zkash
@asyncakash
learning to make gpus go brrr | 🦀 | prev: @availproject, @puffer_finance, @class_lambda, topology | alum @iitroorkee
Potrebbero piacerti















and still claude gives you uv pip


the chatgpt deep research task I requested last night is still running lol Seems like the scheduler kicked off my task before completion welp 🥲 @OpenAI compensate me with one free dr query now 😤

Some unstructured thoughts on what creates abundance mindset..

what’s with the meteoric pump of $zec while the entire market is bleeding red?!

New post in the GPU 𝕻𝖊𝖗𝖋𝖔𝖗𝖒𝖆𝖓𝖈𝖊 Glossary on memory coalescing -- a hardware feature that CUDA programmers need to mind to get anywhere near full memory bandwidth utilization. The article includes a quick µ-benchmark, reproducible with Godbolt. What a tool!


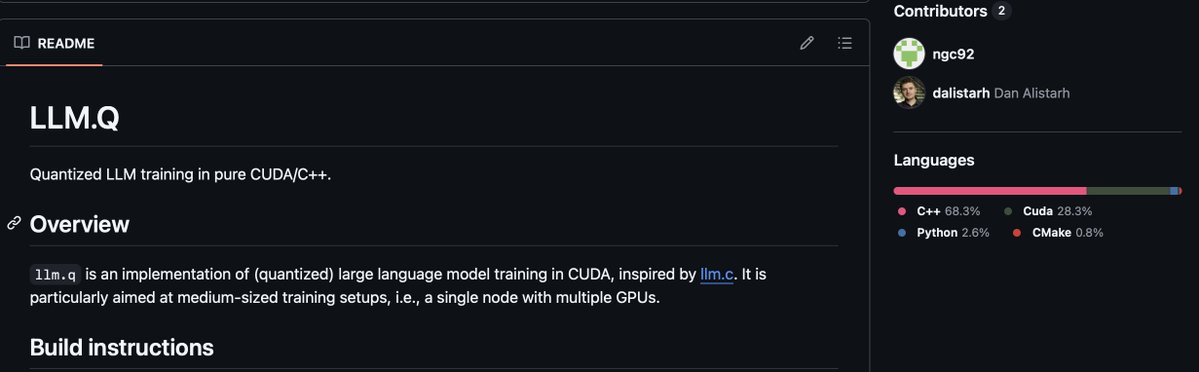
it's insane to me how little attention the llm.q repo has it's a fully C/C++/CUDA implementation of multi-gpu (zero + fsdp), quantized LLM training with support for selective AC it's genuinely the coolest OSS thing I've seen this year (what's crazier is 1 person wrote it!)

Really enjoyed @samsja19’s talk on the challenges of decentralized training (e.g. DiLoCo) under low-bandwidth conditions. Was surprised to learn how much weather can destabilize training 🤯 @PrimeIntellect is doing some wild stuff with decentralized RL! 🚀 Thanks for the…

too much new learning material! we're releasing a few chapters of hard study on post training AI models. it covers all major aspects plus more to come. - Evaluating Large Language models on benchmarks and custom use cases - Preference Alignment with DPO - Fine tuning Vision…

hi! if you’re interested in using or writing mega kernels for AI (one big GPU kernel for an entire model) you should tune in to today’s @GPU_MODE livestream today in ~3 hours we have the authors of MPK talking about their awesome new compiler for mega kernels! see you there :)


I was lucky to work in both China and the US LLM labs, and I've been thinking this for a while. The current values of pretraining are indeed different: US labs be like: - lots of GPUs and much larger flops run - Treating stabilities more seriously, and could not tolerate spikes…

I bet OpenAI/xAI is laughing so hard, this result is obvious tbh, they took a permanent architectural debuff in order to save on compute costs.
Qwen is basically the Samsung (smartphone) of llms. They ship nice new models everything month.

China saved opensource LLMs, some notable releases from July only > Kimi K2 > Qwen3 235B-A22B-2507 > Qwen3 Coder 480B-A35B > Qwen3 235B-A22B-Thinking-2507 > GLM-4.5 > GLM-4.5 Air > Qwen3 30B-A3B-2507 > Qwen3 30B-A3B-Thinking-2507 > Qwen3 Coder 30B-A3B US & EU need to do better
imagine trying to “learn to code” in cursor when the tab key is basically god mode 💀

We've trained a new Tab model that is now the default in Cursor. This model makes 21% fewer suggestions than the previous model while having a 28% higher accept rate for the suggestions it makes. Learn more about how we improved Tab with online RL.

chinese ai labs slaying it 🔥

🚀 Introducing Qwen3-Next-80B-A3B — the FUTURE of efficient LLMs is here! 🔹 80B params, but only 3B activated per token → 10x cheaper training, 10x faster inference than Qwen3-32B.(esp. @ 32K+ context!) 🔹Hybrid Architecture: Gated DeltaNet + Gated Attention → best of speed &…

Just had the most amazing Transformers (with flash attention) lecture from @danielhanchen — he broke down the guts of Transformers and walked us through the full backprop step-by-step, all by hand. Huge thanks to @TheZachMueller for organizing!

DO NOT buy a gpu to write kernels. use @modal notebooks. take 2 mins out of your day to learn this simple trick and kick off your work without paying a shit ton for electricity or cloud gpu run 24/7

🚨 career update i’ve joined @bulletxyz_ to build the growth engine driving the next million on-chain traders. excited to build a @solana native trading layer that brings CEX performance fully on-chain. more ↓



























































































United States Tendenze
- 1. Chauncey Billups 85.5K posts
- 2. Terry Rozier 80.5K posts
- 3. #FalloutDay 4,840 posts
- 4. Mafia 120K posts
- 5. Candace 30.6K posts
- 6. Damon Jones 24.6K posts
- 7. Binance 195K posts
- 8. Ti West 2,665 posts
- 9. Tiago Splitter 3,237 posts
- 10. #7_years_with_ATEEZ 69.2K posts
- 11. The FBI 178K posts
- 12. #RepublicansAreAWOL 3,924 posts
- 13. #에이티즈_7주년_항해는_계속된다 54.4K posts
- 14. Changpeng Zhao 19.6K posts
- 15. #A_TO_Z 53.5K posts
- 16. Stephen A 21K posts
- 17. Bethesda 7,684 posts
- 18. New Vegas 6,332 posts
- 19. Gilbert Arenas 9,769 posts
- 20. Gambling 171K posts
Potrebbero piacerti
-
 Marek Kaput
Marek Kaput
@jajakobyly -
 pia
pia
@0xpiapark -
 tupas.eth fred.stark
tupas.eth fred.stark
@fntupas -
 sun
sun
@sunbh_eth -
 kariy ⛩️
kariy ⛩️
@ammarif_ -
 Tiago
Tiago
@0xtiagofneto -
 Mat Hitchens | DelightFi
Mat Hitchens | DelightFi
@MatHitchens -
 CryptoNights
CryptoNights
@Islam98568047 -
 pavvan | intern
pavvan | intern
@pavvannn -
 Kodawari
Kodawari
@0xKodawari -
 KSK
KSK
@ksk8176012 -
 Bucur Paul Cosmin
Bucur Paul Cosmin
@bpol_tweet -
 playerx
playerx
@ziblibito -
 FreeBird
FreeBird
@FreeBird914845 -
 julio
julio
@julio4__
Something went wrong.
Something went wrong.