
Sourav
@srvmshr
ML University of Tokyo. Prev: Microsoft Research RF, @virginia_tech. Personal opinions. Coasting life with @jnchrltte
قد يعجبك
















Gemma3n was released a few months ago, I wasn't able to find more info and I found it a *very interesting* architecture with a lot of innovations (Matryoshka Transformer, MobileNetV5, etc), so I decided to dig further, here you are the slides of this talk: drive.google.com/file/d/15hbh03…

I struggled to explain agents & tools in layterms. This one does a fairly good job about concepts with examples fly.io/blog/everyone-…


How is memorized data stored in a model? We disentangle MLP weights in LMs and ViTs into rank-1 components based on their curvature in the loss, and find representational signatures of both generalizing structure and memorized training data

He has a great future in making terribly bad but mathematically relevant scratches.


There’s lots of symmetry in neural networks! 🔍 We survey where they appear, how they shape loss landscapes and learning dynamics, and applications in optimization, weight space learning, and much more. ➡️ Symmetry in Neural Network Parameter Spaces arxiv.org/abs/2506.13018

HLE of 45%. Wow! 💣

🚀 Hello, Kimi K2 Thinking! The Open-Source Thinking Agent Model is here. 🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%) 🔹 Executes up to 200 – 300 sequential tool calls without human interference 🔹 Excels in reasoning, agentic search, and coding 🔹 256K context window Built…

I jumped into the @windsurf camp today. Some of the features they integrate are so cool - like deepwiki and codemaps. Only feedback: please integrate other models via Openrouter for e.g... BYOK is great but limited only to Anthropic

Claude Code's native installer is now generally available. It's simpler, more stable, and doesn't require Node.js. We recommend this as the default installation method for all Claude Code users going forward.

Hot take: DAgger (Ross 2011) should be the first paper you read to get into RL, instead of Sutton's book. Maybe also read scheduled sampling (Bengio 2015). And before RL, study supervised learning thoroughly.



Ever wondered about graph learning? Watch Ameya Velingker (@ameya_pa) and Haggai Maron (@HaggaiMaron) give a masterful introduction at the Simons Institute's workshop on Graph Learning Meets Theoretical Computer Science. Video: simons.berkeley.edu/talks/ameya-ve…




Good deep dive after you digest 😀 1. sander.ai/2023/07/20/per… 2. arxiv.org/abs/2406.08929 3. lilianweng.github.io/posts/2021-07-…

Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on! 📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon. It traces the core…

Different places, different systems 'Tenure' makes no sense in S Asia, but has a lot of weight in N-Am univ. Similarly, one could be a Lecturer/Asst Professor with just a Masters in Asia, and only seek job progression after a doctorate. Best not to have preconceived biases

Received a PhD application email from an Assistant Professor at another county (for themselves). I am so confused at multiple levels.

Our Huxley-Gödel Machine learns to rewrite its own code, estimating its own long-term self-improvement potential. It generalizes on new tasks (SWE-Bench Lite), matching the best officially checked human-engineered agents. Arxiv 2510.21614 With @Wenyi_AI_Wang, @PiotrPiekosAI,…

Guide-coded a high throughput document pipeline using @allen_ai OLMO ocr + LayoutLM3 today. Combining these two proved sticky - especially for runs in parallel. LayoutLM has natural proclivity to use easyocr tesseract type of OCR engine. Too many rough edges to patch over
Slightly non-technical take as recounted by my late landlady Ginny 50s~70s had strong hopes. Post war, there was only one way - UP! People worked more towards common good. Individualism was less. Things got done easier because the path of least resistance also was the fastest.

What’s the best thing written about why the remarkably vigorous and inventive France of the 70s and 80s (TGV, Minitel, Ariane, Rafale, Concorde, the world’s preeminent nuclear grid…) has not been nearly as visible in the 21st century? What went wrong?
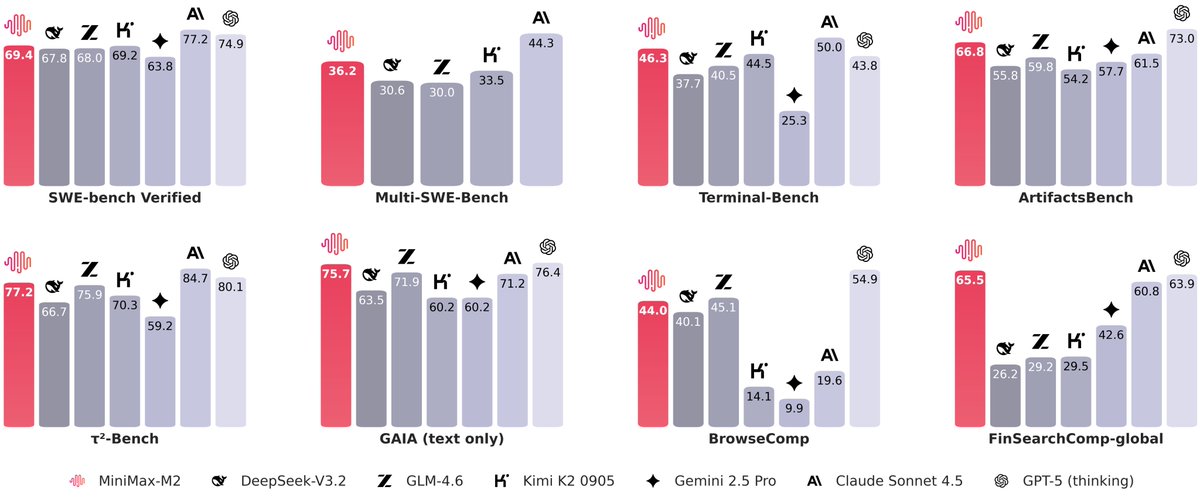
There is no moat when you have open source players like @MiniMax__AI coming in hot 🔥 Congratulations on the nice release

We’re open-sourcing MiniMax M2 — Agent & Code Native, at 8% Claude Sonnet price, ~2x faster ⚡ Global FREE for a limited time via MiniMax Agent & API - Advanced Coding Capability: Engineered for end-to-end developer workflows. Strong capability on a wide-range of applications…

DeepSeek finally released a new model and paper. And because this DeepSeek-OCR release is a bit different from what everyone expected, and DeepSeek releases are generally a big deal, I wanted to do a brief explainer of what it is all about. In short, they explore how vision…

I wonder what does it take for @SonyAlpha to spot amateur photographers outside of Instagram (ughh!). Do they even notice people on other channels? Genuinely curious



This is an excellent history of LLMs, doesn't miss seminal papers I know. Reminds you we're standing on the shoulders of giants, and giants are still being born today. gregorygundersen.com/blog/2025/10/0…














































































































United States الاتجاهات
- 1. Nuss 5,076 posts
- 2. #AEWCollision 8,637 posts
- 3. Miller Moss N/A
- 4. Hawks 16.5K posts
- 5. Lagway 3,089 posts
- 6. Ty Simpson 2,722 posts
- 7. Bama 11.5K posts
- 8. Watford 2,765 posts
- 9. Clemson 5,752 posts
- 10. Van Buren 1,094 posts
- 11. #RockHall2025 3,755 posts
- 12. Stoops 1,523 posts
- 13. Cam Coleman 3,850 posts
- 14. Vandy 5,858 posts
- 15. Jeremiyah Love 1,820 posts
- 16. Wake Forest 1,734 posts
- 17. Iowa 31.8K posts
- 18. Norvell 1,404 posts
- 19. Auburn 15.8K posts
- 20. DEANDRE HUNTER N/A
قد يعجبك
-
 Tanmay Gupta
Tanmay Gupta
@tanmay2099 -
 Dhruv Batra
Dhruv Batra
@DhruvBatra_ -
 Gergely Neu
Gergely Neu
@neu_rips -
 UvA AMLab
UvA AMLab
@AmlabUva -
 Alexander Terenin - on the faculty job market
Alexander Terenin - on the faculty job market
@avt_im -
 Andrew Carr 🤸
Andrew Carr 🤸
@andrew_n_carr -
 Max Jaderberg
Max Jaderberg
@maxjaderberg -
 Arsha Nagrani
Arsha Nagrani
@NagraniArsha -
 Samarth Sinha
Samarth Sinha
@_sam_sinha_ -
 Matthew Johnson
Matthew Johnson
@SingularMattrix -
 Yu Bai
Yu Bai
@yubai01 -
 Ricky T. Q. Chen
Ricky T. Q. Chen
@RickyTQChen -
 Yash Kant
Yash Kant
@yash2kant -
 Michal Valko
Michal Valko
@misovalko -
 Andreas Kirsch 🇺🇦
Andreas Kirsch 🇺🇦
@BlackHC
Something went wrong.
Something went wrong.