
내가 좋아할 만한 콘텐츠















The #Gemini3 model is soo good at coding. Pairing #codex and Gemini together, I could squash almost all my bugs in just 2 passes max. Thanks @GoogleDeepMind I was a non-believer in LLM based coding for serious work, but I'm rapidly changing my opinion about it. 🥲🥲
RIP @burgerbecky You'll be missed and the world is forever a little darker with your light that's gone 😔 May your next journey be as exciting as infinite scroll of Space Invaders
Beyond all other failures this week VS @code deprecating Intellicode in favor of @GitHubCopilot is the most sad thing to happen 😔 Not everything needed a subscription account - Intellicode had a long and healthy run being bundled as the default
I'd love to try this out on some math heavy papers, but it makes me uncomfortable to know that hallucinations could completely paint a different picture from what paper claims. Does anyone have any better recommendation. Wasn't there something in this direction from @allen_ai

Introducing quickarXiv Papers are often written in convoluted language that is hard to understand. We're fixing that. Swap arxiv → quickarxiv on any paper URL to get an instant blog with figures, insights, and explanations. Now extracted with DeepSeek OCR 🚀
I want to migrate away from GH to @codeberg_org but the biggest hurdle is the dozens of integrations & the ecosystem access overall. Codeberg is a solid choice & feels like the good ol' Github without the bloat & incessant spam/scam vectors

Interesting thread on 6 months of "hardcore" usage of coding agents (rewriting ~300k LOC). The meta-learning is ironic: The user stopped hard "vibe coding" and return to disciplined context engineering. reddit.com/r/ClaudeAI/com…


Very cool blog by @character_ai diving into how they trained their proprietary model Kaiju (13B, 34B, 110B), before switching to OSS model, and spoiler: it has Noam Shazeer written all over it. Most of the choices for model design (MQA, SWA, KV Cache, Quantization) are not to…

💯 FOSS models are the way to go. Making things accessible & pushing the boundaries of what is doable


Gemma3n was released a few months ago, I wasn't able to find more info and I found it a *very interesting* architecture with a lot of innovations (Matryoshka Transformer, MobileNetV5, etc), so I decided to dig further, here you are the slides of this talk: drive.google.com/file/d/15hbh03…

I struggled to explain agents & tools in layterms. This one does a fairly good job about concepts with examples fly.io/blog/everyone-…

How is memorized data stored in a model? We disentangle MLP weights in LMs and ViTs into rank-1 components based on their curvature in the loss, and find representational signatures of both generalizing structure and memorized training data


There’s lots of symmetry in neural networks! 🔍 We survey where they appear, how they shape loss landscapes and learning dynamics, and applications in optimization, weight space learning, and much more. ➡️ Symmetry in Neural Network Parameter Spaces arxiv.org/abs/2506.13018

HLE of 45%. Wow! 💣

🚀 Hello, Kimi K2 Thinking! The Open-Source Thinking Agent Model is here. 🔹 SOTA on HLE (44.9%) and BrowseComp (60.2%) 🔹 Executes up to 200 – 300 sequential tool calls without human interference 🔹 Excels in reasoning, agentic search, and coding 🔹 256K context window Built…

I jumped into the @windsurf camp today. Some of the features they integrate are so cool - like deepwiki and codemaps. Only feedback: please integrate other models via Openrouter for e.g... BYOK is great but limited only to Anthropic

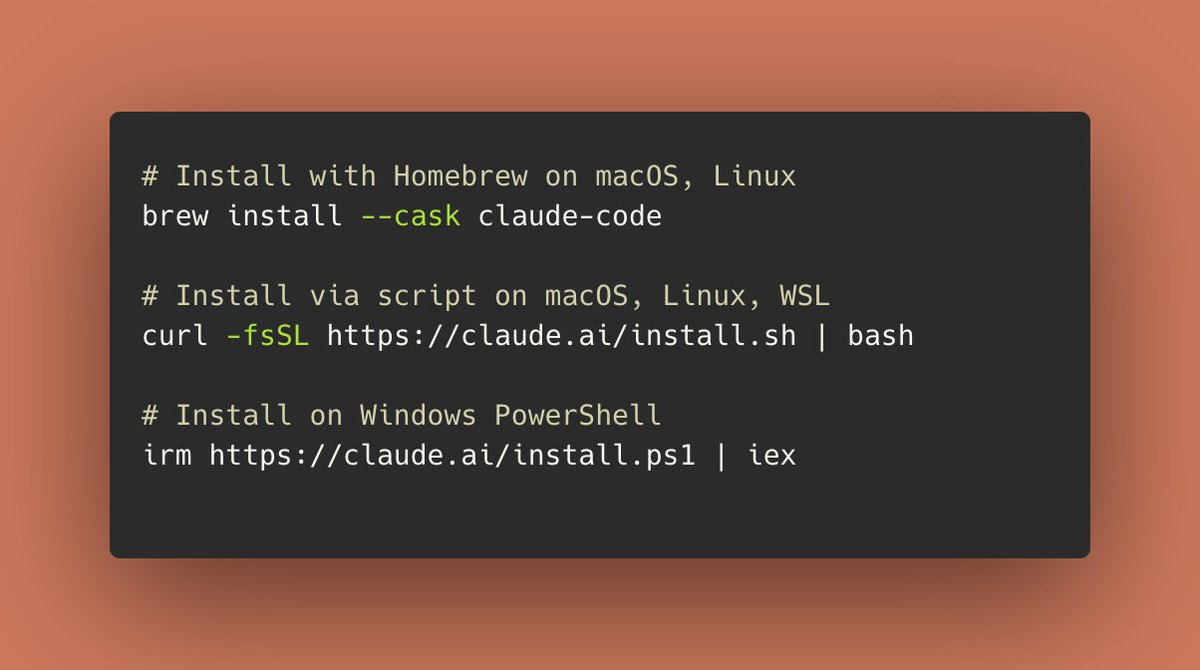
Claude Code's native installer is now generally available. It's simpler, more stable, and doesn't require Node.js. We recommend this as the default installation method for all Claude Code users going forward.

Hot take: DAgger (Ross 2011) should be the first paper you read to get into RL, instead of Sutton's book. Maybe also read scheduled sampling (Bengio 2015). And before RL, study supervised learning thoroughly.



Ever wondered about graph learning? Watch Ameya Velingker (@ameya_pa) and Haggai Maron (@HaggaiMaron) give a masterful introduction at the Simons Institute's workshop on Graph Learning Meets Theoretical Computer Science. Video: simons.berkeley.edu/talks/ameya-ve…




Good deep dive after you digest 😀 1. sander.ai/2023/07/20/per… 2. arxiv.org/abs/2406.08929 3. lilianweng.github.io/posts/2021-07-…

Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on! 📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon. It traces the core…

Guide-coded a high throughput document pipeline using @allen_ai OLMO ocr + LayoutLM3 today. Combining these two proved sticky - especially for runs in parallel. LayoutLM has natural proclivity to use easyocr tesseract type of OCR engine. Too many rough edges to patch over

DeepSeek finally released a new model and paper. And because this DeepSeek-OCR release is a bit different from what everyone expected, and DeepSeek releases are generally a big deal, I wanted to do a brief explainer of what it is all about. In short, they explore how vision…













































































































United States 트렌드
- 1. Knicks 12.2K posts
- 2. Landry Shamet 1,169 posts
- 3. #AEWDynamite 20.5K posts
- 4. Philon 1,699 posts
- 5. Brandon Williams N/A
- 6. #Survivor49 3,644 posts
- 7. #CMAawards 5,202 posts
- 8. #AEWCollision 8,239 posts
- 9. Vucevic 4,645 posts
- 10. Vooch N/A
- 11. Blazers 3,911 posts
- 12. Derik Queen 3,279 posts
- 13. #mnwild N/A
- 14. Simon Walker N/A
- 15. Dubon 3,630 posts
- 16. Wallstedt N/A
- 17. Donovan Mitchell 3,892 posts
- 18. Josh Hart 2,543 posts
- 19. Bristow 1,077 posts
- 20. Jackson Blake N/A
내가 좋아할 만한 콘텐츠
-
 Pavel Izmailov
Pavel Izmailov
@Pavel_Izmailov -
 Tanmay Gupta
Tanmay Gupta
@tanmay2099 -
 Dhruv Batra
Dhruv Batra
@DhruvBatra_ -
 Gergely Neu
Gergely Neu
@neu_rips -
 UvA AMLab
UvA AMLab
@AmlabUva -
 Alexander Terenin - on the faculty job market
Alexander Terenin - on the faculty job market
@avt_im -
 Andrew Carr 🤸
Andrew Carr 🤸
@andrew_n_carr -
 Max Jaderberg
Max Jaderberg
@maxjaderberg -
 Arsha Nagrani
Arsha Nagrani
@NagraniArsha -
 Samarth Sinha
Samarth Sinha
@_sam_sinha_ -
 Matthew Johnson
Matthew Johnson
@SingularMattrix -
 Yu Bai
Yu Bai
@yubai01 -
 Ricky T. Q. Chen
Ricky T. Q. Chen
@RickyTQChen -
 Yash Kant
Yash Kant
@yash2kant -
 Michal Valko
Michal Valko
@misovalko
Something went wrong.
Something went wrong.