
Linghao Zhang
@starryzhangcs
Staff @XiaomiMiMo. I build something verifiable and scalable for code. Ex @MSFTResearch

man I'm excited, can't wait to reveal soon what @KLieret @_carlosejimenez @OfirPress @lschmidt3 @Diyi_Yang and I have been working on. Where should code evaluation go after SWE-bench? We have an answer ⚔️

If you are impacted by layoff, welcome to dm me

👋 Say Hi to MiMo-Audio! Our BREAKTHROUGH in general-purpose audio intelligence. 🎯 Scaling pretraining to 100M+ hours leads to EMERGENCE of few-shot generalization across diverse audio tasks! 🔥 Post-trained MiMo-Audio-7B-Instruct: • crushes benchmarks: SOTA on MMSU, MMAU,…


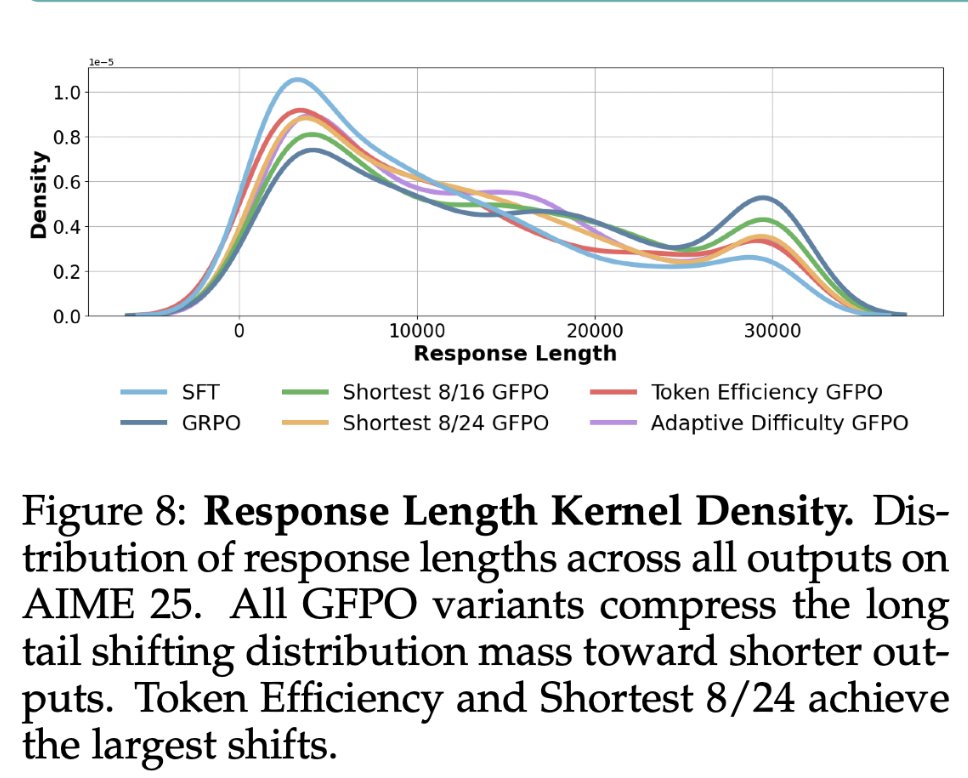
GRPO makes reasoning model yap a lot, but there's a simple fix: Sample more responses during training, and train on the shortest ones. This creates a length pressure that makes the model sound much more terse, without sacrificing accuracy!! Examples of GRPO vs GFPO versions…


Thinking Less at test-time requires Sampling More at training-time! GFPO is a new, cool, and simple Policy Opt algorithm is coming to your RL Gym tonite, led by @VaishShrivas and our MSR group: Group Filtered PO (GFPO) trades off training-time with test-time compute, in order…




🚀 MiMo‑VL 2508 is live! Same size, much smarter 🚀 We’ve upgraded performance, thinking control, and overall user experience. 📈 Benchmark gains across image + video: MMMU 70.6, VideoMME 70.8. Consistent improvements across the board. 🤖 Thinking Control: toggle reasoning…

exactly

The biggest lever towards ASI is right in front of you (RL environments) but you feel too smart to work on data

2026+: everyone releases their own OS Building with Claude Code SDK made me realize that we are just a UI away from the next ChatGPT moment. Models are more intelligent than they seem. AI Agents are already unlocking unique and novel experiences. Claude Code is the…


What happens if you compare LMs on SWE-bench without the fancy scaffolds? Our new leaderboard “SWE-bench (bash only)” shows you which LMs are the best at getting the job done with just bash. More on why this is important 👇


🗒️Have been exploring Agent-RL training over the past few months, particularly in GUI scenarios. Here’s a summary of some practical insights and lessons 🤔 learned from the perspective of an industry researcher, and some reference papers.



Slides for my lecture “LLM Reasoning” at Stanford CS 25: dennyzhou.github.io/LLM-Reasoning-… Key points: 1. Reasoning in LLMs simply means generating a sequence of intermediate tokens before producing the final answer. Whether this resembles human reasoning is irrelevant. The crucial…
based

Releasing mini, a radically simple SWE-agent: 100 lines of code, 0 special tools, and gets 65% on SWE-bench verified! Made for benchmarking, fine-tuning, RL, or just for use from your terminal. It’s open source, simple to hack, and compatible with any LM! Link in 🧵


Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains 'We introduce Rubrics as Rewards (RaR), a framework that uses structured, checklist-style rubrics as interpretable reward signals for on-policy training with GRPO. Our best RaR method yields up to a relative…


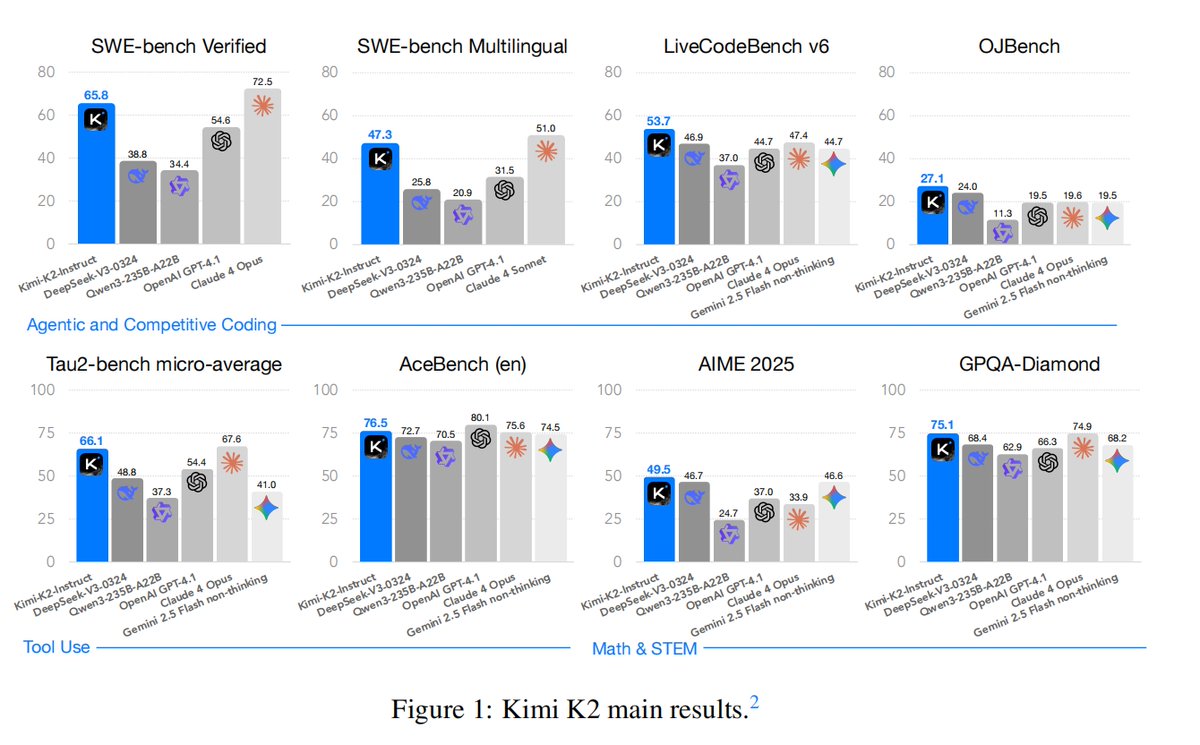
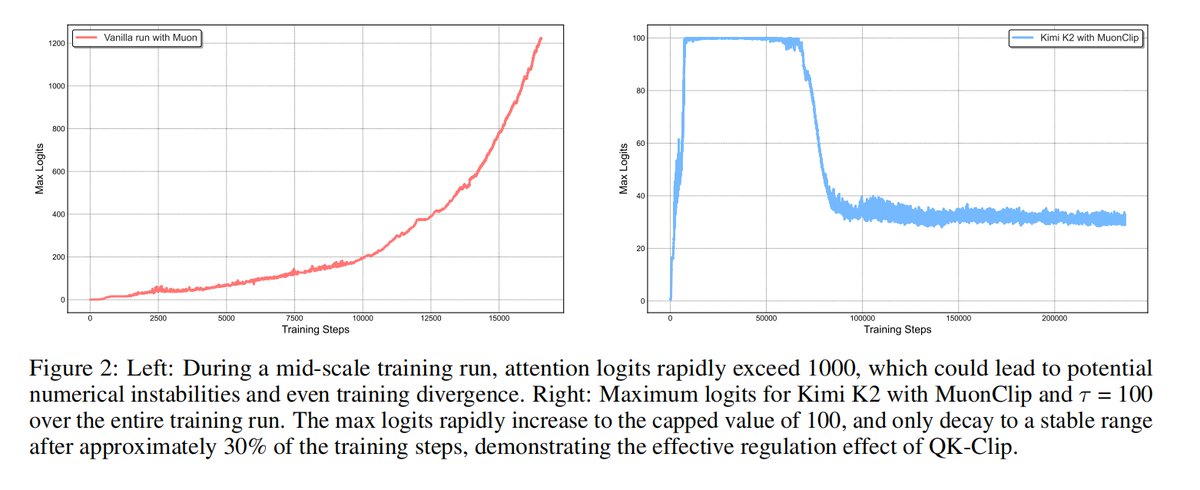
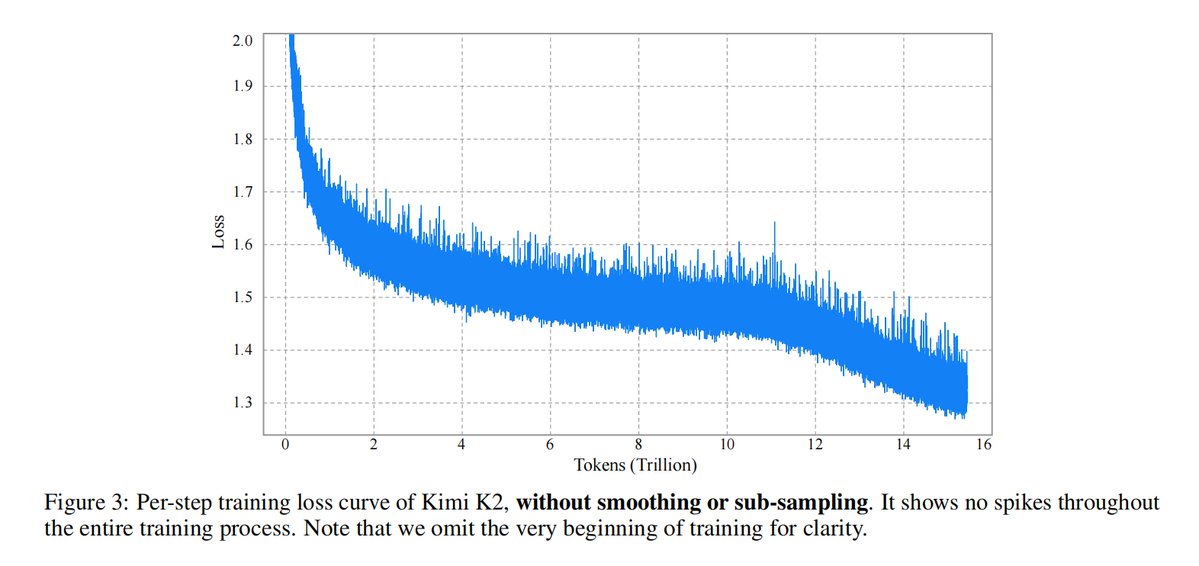
Kimi K2 tech report just dropped! Quick hits: - MuonClip optimizer: stable + token-efficient pretraining at trillion-parameter scale - 20K+ tools, real & simulated: unlocking scalable agentic data - Joint RL with verifiable + self-critique rubric rewards: alignment that adapts -…
🌕 Did you notice Kimi’s doodle today at kimi.ai? It’s our little Moon Day surprise - A tribute to the spirit of exploration, and to the day humans first set foot on the Moon 🍻 May Kimi fuel your next big idea 💡



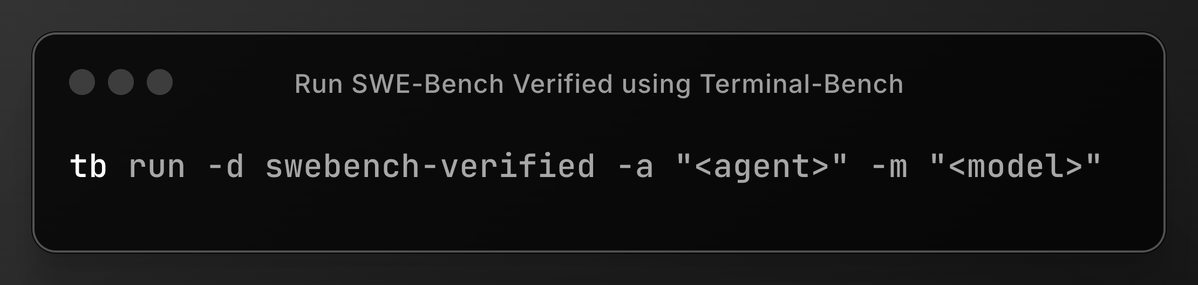
Evaluating agents on benchmarks is a pain. Each benchmark comes with its own harness, scoring scripts, and environments and integrating can take days. We're introducing the Terminal-Bench dataset registry to solve this problem. Think of it as the npm of agent benchmarks. Now…

Scaling up RL is all the rage right now, I had a chat with a friend about it yesterday. I'm fairly certain RL will continue to yield more intermediate gains, but I also don't expect it to be the full story. RL is basically "hey this happened to go well (/poorly), let me slightly…

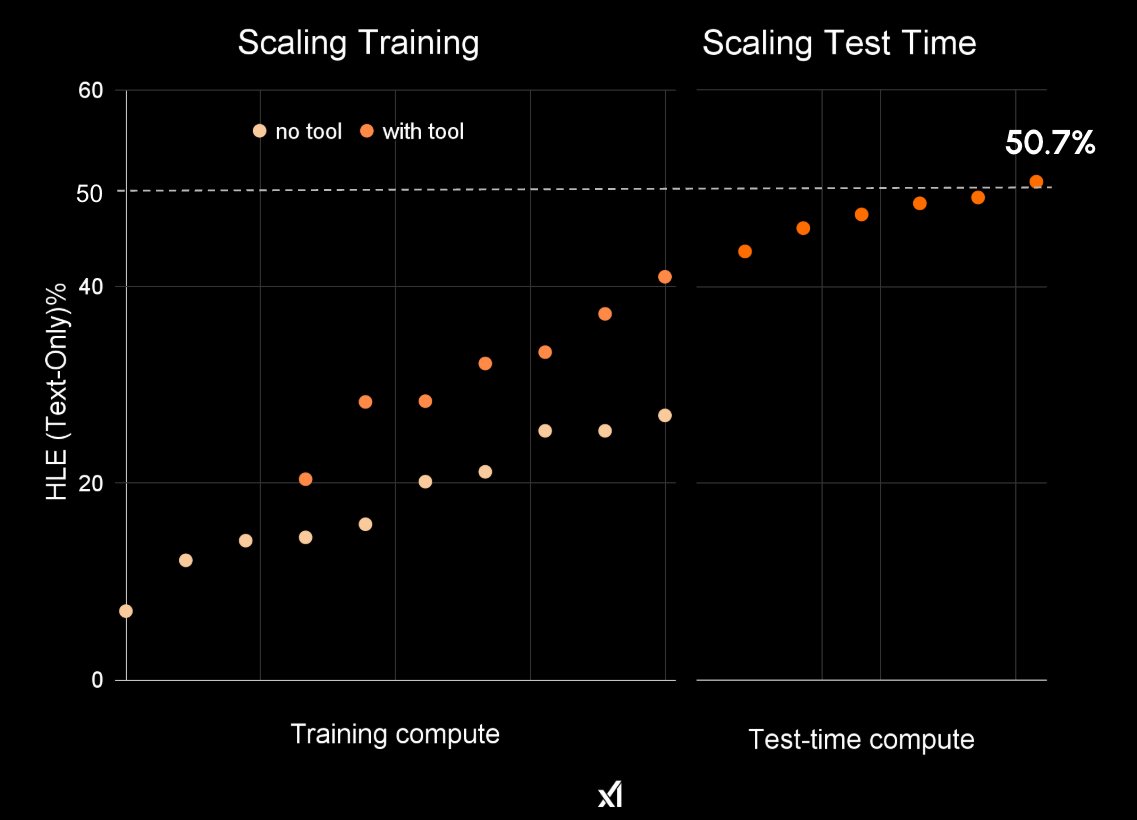
We built 200k-GPU clusters; We scaled up & curated higher-quality data; We scaled compute by 100x; We developed training & test-time recipes; We made everything RL native; We stabilized infrastructure and speeded up; That's how you turn RL into the pre-training scale. Yet I am…

> opens claude code > write a huge ass prompt > auto-accept edits > go drink water, watch a yt video, chillax, work on something else > come back, work is done. What a time to live in. wow.

























































































United States Trends
- 1. Godzilla 25K posts
- 2. Shabbat 3,121 posts
- 3. Trench 7,507 posts
- 4. $DUOL 2,679 posts
- 5. Barca 98.4K posts
- 6. Lamine 66.9K posts
- 7. Brujas 28.3K posts
- 8. #dispatch 39.9K posts
- 9. Barcelona 154K posts
- 10. Brugge 49.6K posts
- 11. Richardson 3,411 posts
- 12. Captain Kangaroo N/A
- 13. Flick 38.4K posts
- 14. Toledo 10.2K posts
- 15. Alastor 88K posts
- 16. Sharia 120K posts
- 17. Jared Golden 2,169 posts
- 18. Foden 22.4K posts
- 19. SCOTUS 37.2K posts
- 20. Anthony Taylor 1,893 posts
Something went wrong.
Something went wrong.